[Example] Add STAFNet Model for Air Quality Prediction #1070
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,169 @@ | ||
| # STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction | ||
|
|
||
| | 预训练模型 | 指标 | | ||
| | ------------------------------------------------------------ | ---------------------- | | ||
| | [stafnet.pdparams](https://paddle-org.bj.bcebos.com/paddlescience/models/stafnet/stafnet.pdparams) | AQI_MAE(1-48h) : 26.72 | | ||
|
|
||
| === "模型训练命令" | ||
|
|
||
| ```` | ||
| ``` sh | ||
| python stafnet.py TRAIN_DIR="Your train dataset path" eval_data_path="Your evaluate dataset path" | ||
| ``` | ||
| ```` | ||
|
|
||
| === "模型评估命令" | ||
|
|
||
| ```` | ||
| ``` sh | ||
| python stafnet.py mode=eval EVAL.pretrained_model_path="https://paddle-org.bj.bcebos.com/paddlescience/models/stafnet/stafnet.pdparams" EVAL.pretrained_model_path="https://paddle-org.bj.bcebos.com/paddlescience/datasets/stafnet/val_data.pkl" | ||
|
There was a problem hiding this comment. wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/stafnet/val_data.pkl -P ./dataset/ |
||
| ``` | ||
| ```` | ||
|
|
||
| ## 1. 背景介绍 | ||
|
|
||
| 近些年,全球城市化和工业化不可避免地导致了严重的空气污染问题。心脏病、哮喘和肺癌等非传染性疾病的高发与暴露于空气污染直接相关。因此,空气质量预测已成为公共卫生、国民经济和城市管理的研究热点。目前已经建立了大量监测站来监测空气质量,并将其地理位置和历史观测数据合并为时空数据。然而,由于空气污染形成和扩散的高度复杂性,空气质量预测仍然面临着一些挑战。 | ||
|
|
||
| 首先,空气中污染物的排放和扩散会导致邻近地区的空气质量迅速恶化,这一现象在托布勒地理第一定律中被描述为空间依赖关系,建立空间关系模型对于预测空气质量至关重要。然而,由于空气监测站的地理分布稀疏,要捕捉数据中内在的空间关联具有挑战性。其次,空气质量受到多源复杂因素的影响,尤其是气象条件。例如,长时间的小风或静风会抑制空气污染物的扩散,而自然降雨则在清除和冲刷空气污染物方面发挥作用。然而,空气质量站和气象站位于不同区域,导致多模态特征不对齐。融合不对齐的多模态特征并获取互补信息以准确预测空气质量是另一个挑战。最后但并非最不重要的一点是,空气质量的变化具有明显的多周期性特征。利用这一特点对提高空气质量预测的准确性非常重要,但也具有挑战性。 | ||
|
|
||
| 针对空气质量预测提出了许多研究。早期的方法侧重于学习单个观测站观测数据的时间模式,而放弃了观测站之间的空间关系。最近,由于图神经网络(GNN)在处理非欧几里得图结构方面的有效性,越来越多的方法采用 GNN 来模拟空间依赖关系。这些方法将车站位置作为上下文特征,隐含地建立空间依赖关系模型,没有充分利用车站位置和车站之间关系所包含的宝贵空间信息。此外,现有的时空 GNN 缺乏在错位图中融合多个特征的能力。因此,大多数方法都需要额外的插值算法,以便在早期阶段将气象特征与 AQ 特征进行对齐和连接。这种方法消除了空气质量站和气象站之间的空间和结构信息,还可能引入噪声导致误差累积。此外,在空气质量预测中利用多周期性的问题仍未得到探索。 | ||
|
|
||
| 该案例研究时空图网络网络在空气质量预测方向上的应用。 | ||
|
|
||
|
|
||
| ## 2. 模型原理 | ||
|
|
||
| STAFNet是一个新颖的多模式预报框架--时空感知融合网络来预测空气质量。STAFNet 由三个主要部分组成:空间感知 GNN、跨图融合关注机制和 TimesNet 。具体来说,为了捕捉各站点之间的空间关系,我们首先引入了空间感知 GNN,将空间信息明确纳入信息传递和节点表示中。为了全面表示气象影响,我们随后提出了一种基于交叉图融合关注机制的多模态融合策略,在不同类型站点的数量和位置不一致的情况下,将气象数据整合到 AQ 数据中。受多周期分析的启发,我们采用 TimesNet 将时间序列数据分解为不同频率的周期信号,并分别提取时间特征。 | ||
|
|
||
| 本章节仅对 STAFNet的模型原理进行简单地介绍,详细的理论推导请阅读 STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction | ||
|
|
||
| 模型的总体结构如图所示: | ||
|
|
||
| 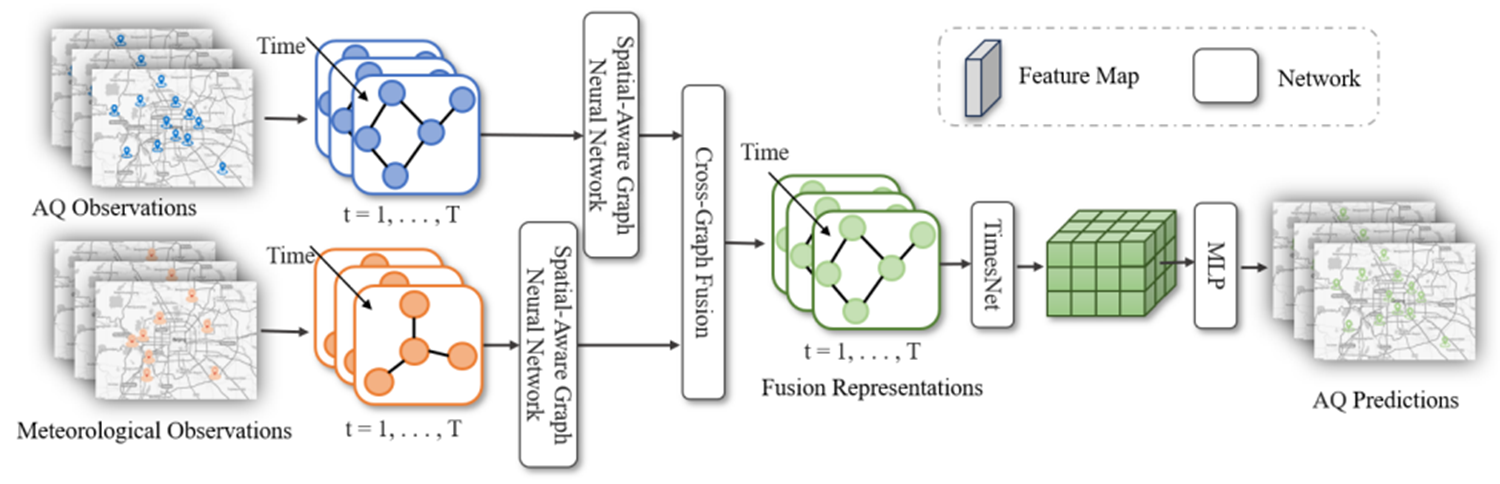 | ||
|
|
||
| <div align = "center">STAFNet网络模型</div> | ||
|
|
||
| STAFNet 包含三个模块,分别将空间信息、气象信息和历史信息融合到空气质量特征表征中。首先模型的输入:过去T个时刻的**空气质量**数据和**气象**数据,使用两个空间感知 GNN(SAGNN),利用监测站之间的空间关系分别提取空气质量和气象信息。然后,跨图融合注意(CGF)将气象信息融合到空气质量表征中。最后,我们采用 TimesNet 模型来描述空气质量序列的时间动态,并生成多步骤预测。这一推理过程可表述如下, | ||
|
|
||
| 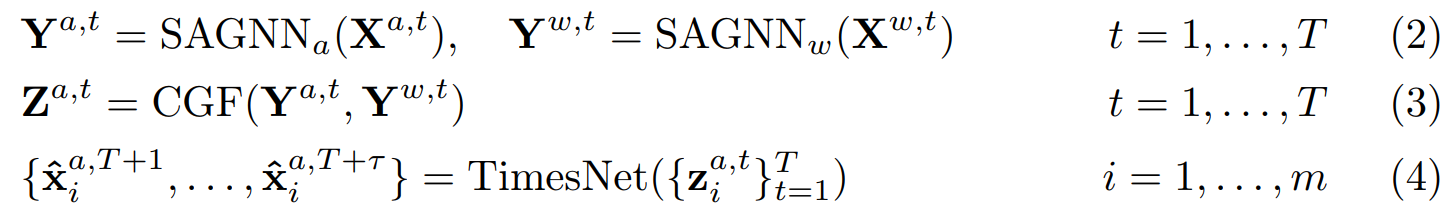 | ||
|
|
||
| ## 3. 模型构建 | ||
|
|
||
| ### 3.1 数据集介绍 | ||
|
|
||
| 数据集采用了STAFNet处理好的北京空气质量数据集。数据集都包含: | ||
|
|
||
| (1)空气质量观测值(即 PM2.5、PM10、O3、NO2、SO2 和 CO); | ||
|
|
||
| (2)气象观测值(即温度、气压、湿度、风速和风向); | ||
|
|
||
| (3)站点位置(即经度和纬度)。 | ||
|
|
||
| 所有空气质量和气象观测数据每小时记录一次。数据集的收集时间为 2021 年 1 月 24 日至 2023 年 1 月 19 日,按 9:1的比例将数据分为训练集和测试集。空气质量观测数据来自国家城市空气质量实时发布平台,气象观测数据来自中国气象局。数据集的具体细节如下表所示: | ||
|
|
||
| <div> <!--块级封装--> <center> <!--将图片和文字居中--> <img src="https://paddle-org.bj.bcebos.com/paddlescience/docs/stafnet/dataset.jpg" alt="image-20240530104042194" style="zoom: 25%;" /> <br> <!--换行--> 北京空气质量数据集 <!--标题--> </center> </div> | ||
|
|
||
| 具体的数据集可从https://quotsoft.net/air/下载。 | ||
|
|
||
| 运行本问题代码前请下载[数据集](https://paddle-org.bj.bcebos.com/paddlescience/datasets/stafnet/val_data.pkl), 下载后分别存放在路径: | ||
|
|
||
| ``` | ||
| ./dataset | ||
| ``` | ||
|
|
||
| ### 3.2 模型搭建 | ||
|
|
||
| 在STAFNet模型中,输入过去72小时35个站点的空气质量数据,预测这35个站点未来48小时的空气质量。在本问题中,我们使用神经网络 `stafnet` 作为模型,其接收图结构数据,输出预测结果。 | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/stafnet.py:11 | ||
| --8<-- | ||
| ``` | ||
|
There was a problem hiding this comment. 代码不显示,参考其他案例文档,在第一行添加py linenums="11" title="examples/stafnet/stafnet.py",下面的代码块均修改一下 |
||
|
|
||
| ### 3.4 参数和超参数设定 | ||
|
|
||
| 其中超参数`cfg.MODEL.gat_hidden_dim`、`cfg.MODEL.e_layers`、`cfg.MODEL.d_model`、`cfg.MODEL.top_k`等默认设定如下: | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/conf/stafnet.yaml:38:62 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| ### 3.5 优化器构建 | ||
|
|
||
| 训练过程会调用优化器来更新模型参数,此处选择较为常用的 `Adam` 优化器。 | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/stafnet.py:64 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| 其中学习率相关的设定如下: | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/conf/stafnet.yaml:73:78 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| ### 3.6 约束构建 | ||
|
|
||
| 在本案例中,我们使用监督数据集对模型进行训练,因此需要构建监督约束。 | ||
|
|
||
| 在定义约束之前,我们需要指定数据集的路径等相关配置,将这些信息存放到对应的 YAML 文件中,如下所示。 | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/conf/stafnet.yaml:31:34 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| 最后构建监督约束,如下所示。 | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/stafnet.py:53:59 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| ### 3.7 评估器构建 | ||
|
|
||
| 在训练过程中通常会按一定轮数间隔,用验证集(测试集)评估当前模型的训练情况,因此使用 `ppsci.validate.SupervisedValidator` 构建评估器,构建过程与 [约束构建](https://github.com/PaddlePaddle/PaddleScience/blob/develop/docs/zh/examples/cfdgcn.md#34) 类似,只需把数据目录改为测试集的目录,并在配置文件中设置 `EVAL.batch_size=1` 即可。 | ||
|
There was a problem hiding this comment.
|
||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/stafnet.py:30:53 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| 评估指标为预测结果和真实结果的MSE 值,因此需自定义指标计算函数,如下所示。 | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/stafnet.py:30:53 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| ### 3.8 模型训练 | ||
|
|
||
| 由于本问题为时序预测问题,因此可以使用PaddleScience内置的`psci.loss.MAELoss('mean')`作为训练过程的损失函数。同时选择使用随机梯度下降法对网络进行优化。完成述设置之后,只需要将上述实例化的对象按顺序传递给 `ppsci.solver.Solver`,然后启动训练。具体代码如下: | ||
|
|
||
| ``` | ||
| --8<-- | ||
| examples/stafnet/stafnet.py:125:140 | ||
| --8<-- | ||
| ``` | ||
|
|
||
| ## 4. 完整代码 | ||
|
|
||
| ```python | ||
| --8<-- | ||
| examples/stafnet/stafnet.py | ||
| --8<-- | ||
| ``` | ||
|
|
||
| ## 5. 参考资料 | ||
|
|
||
| - [STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction]([STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction | SpringerLink](https://link.springer.com/chapter/10.1007/978-3-031-78186-5_22)) | ||
|
There was a problem hiding this comment.
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,85 @@ | ||
| defaults: | ||
| - ppsci_default | ||
| - TRAIN: train_default | ||
| - TRAIN/ema: ema_default | ||
| - TRAIN/swa: swa_default | ||
| - EVAL: eval_default | ||
| - INFER: infer_default | ||
| - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default | ||
| - _self_ | ||
| hydra: | ||
| run: | ||
| # dynamic output directory according to running time and override name | ||
| dir: outputs_stafnet/${now:%Y-%m-%d}/${now:%H-%M-%S}/${hydra.job.override_dirname} | ||
| job: | ||
| name: ${mode} # name of logfile | ||
| chdir: false # keep current working directory unchanged | ||
| callbacks: | ||
| init_callback: | ||
| _target_: ppsci.utils.callbacks.InitCallback | ||
| sweep: | ||
| # output directory for multirun | ||
| dir: ${hydra.run.dir} | ||
| subdir: ./ | ||
|
|
||
| # general settings | ||
| mode: train # running mode: train/eval | ||
| seed: 42 | ||
| output_dir: ${hydra:run.dir} | ||
| log_freq: 20 | ||
| # dataset setting | ||
| DATASET: | ||
| label_keys: [label] | ||
| data_dir: ./dataset/train_data.pkl | ||
|
|
||
|
|
||
|
|
||
| MODEL: | ||
| input_keys: [aq_train_data, mete_train_data] | ||
| output_keys: [label] | ||
| output_attention: True | ||
| seq_len: 72 | ||
| pred_len: 48 | ||
| aq_gat_node_features: 7 | ||
| aq_gat_node_num: 35 | ||
| mete_gat_node_features: 7 | ||
| mete_gat_node_num: 18 | ||
| gat_hidden_dim: 32 | ||
| gat_edge_dim: 3 | ||
| e_layers: 2 | ||
| enc_in: 7 | ||
| dec_in: 7 | ||
| c_out: 7 | ||
| d_model: 32 | ||
| embed: "fixed" | ||
| freq: "t" | ||
| dropout: 0.05 | ||
| factor: 3 | ||
| n_heads: 4 | ||
| d_ff: 64 | ||
| num_kernels: 6 | ||
| top_k: 4 | ||
|
There was a problem hiding this comment. output_attention: true |
||
|
|
||
| # training settings | ||
| TRAIN: | ||
| epochs: 100 | ||
| iters_per_epoch: 400 | ||
| save_freq: 10 | ||
| eval_during_train: true | ||
| eval_freq: 10 | ||
| batch_size: 32 | ||
| learning_rate: 0.0001 | ||
| lr_scheduler: | ||
| epochs: ${TRAIN.epochs} | ||
| iters_per_epoch: ${TRAIN.iters_per_epoch} | ||
| learning_rate: 0.0005 | ||
| step_size: 20 | ||
| gamma: 0.95 | ||
| pretrained_model_path: null | ||
| checkpoint_path: null | ||
|
|
||
| EVAL: | ||
| eval_data_path: ./dataset/new_val_data.pkl | ||
|
|
||
| pretrained_model_path: null | ||
| compute_metric_by_batch: false | ||
| eval_with_no_grad: true | ||
| batch_size: 32 | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,138 @@ | ||
| import ppsci | ||
| from ppsci.utils import logger | ||
| from omegaconf import DictConfig | ||
| import hydra | ||
| import paddle | ||
| from ppsci.data.dataset.stafnet_dataset import gat_lstmcollate_fn | ||
|
There was a problem hiding this comment. from ppsci.data.dataset.stafnet_dataset import gat_lstmcollate_fn去掉吧,并没有用到 |
||
| import multiprocessing | ||
|
|
||
| def train(cfg: DictConfig): | ||
| # set model | ||
| model = ppsci.arch.STAFNet(**cfg.MODEL) | ||
| train_dataloader_cfg = { | ||
| "dataset": { | ||
| "name": "STAFNetDataset", | ||
| "file_path": cfg.DATASET.data_dir, | ||
| "input_keys": cfg.MODEL.input_keys, | ||
| "label_keys": cfg.MODEL.output_keys, | ||
| "seq_len": cfg.MODEL.seq_len, | ||
| "pred_len": cfg.MODEL.pred_len, | ||
|
|
||
| }, | ||
| "batch_size": cfg.TRAIN.batch_size, | ||
| "sampler": { | ||
| "name": "BatchSampler", | ||
| "drop_last": False, | ||
| "shuffle": True, | ||
| }, | ||
| "num_workers": 0 | ||
| } | ||
| eval_dataloader_cfg= { | ||
| "dataset": { | ||
| "name": "STAFNetDataset", | ||
| "file_path": cfg.EVAL.eval_data_path, | ||
| "input_keys": cfg.MODEL.input_keys, | ||
| "label_keys": cfg.MODEL.output_keys, | ||
| "seq_len": cfg.MODEL.seq_len, | ||
| "pred_len": cfg.MODEL.pred_len, | ||
| }, | ||
| "batch_size": cfg.TRAIN.batch_size, | ||
| "sampler": { | ||
| "name": "BatchSampler", | ||
| "drop_last": False, | ||
| "shuffle": True, | ||
HydrogenSulfate marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| }, | ||
| "num_workers": 0 | ||
| } | ||
|
|
||
| sup_constraint = ppsci.constraint.SupervisedConstraint( | ||
| train_dataloader_cfg, | ||
| loss=ppsci.loss.MSELoss("mean"), | ||
| name="STAFNet_Sup", | ||
| ) | ||
| constraint = {sup_constraint.name: sup_constraint} | ||
| sup_validator = ppsci.validate.SupervisedValidator( | ||
| eval_dataloader_cfg, | ||
| loss=ppsci.loss.MSELoss("mean"), | ||
| metric={"MSE": ppsci.metric.MSE()}, | ||
| name="Sup_Validator", | ||
| ) | ||
| validator = {sup_validator.name: sup_validator} | ||
|
|
||
| # set optimizer | ||
| lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)() | ||
| optimizer = ppsci.optimizer.Adam(lr_scheduler)(model) | ||
| ITERS_PER_EPOCH = len(sup_constraint.data_loader) | ||
|
|
||
| # initialize solver | ||
| solver = ppsci.solver.Solver( | ||
| model, | ||
| constraint, | ||
| cfg.output_dir, | ||
| optimizer, | ||
| lr_scheduler, | ||
| cfg.TRAIN.epochs, | ||
| ITERS_PER_EPOCH, | ||
| eval_during_train=cfg.TRAIN.eval_during_train, | ||
| seed=cfg.seed, | ||
| validator=validator, | ||
| compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch, | ||
| eval_with_no_grad=cfg.EVAL.eval_with_no_grad, | ||
| ) | ||
|
|
||
| # train model | ||
| solver.train() | ||
|
|
||
| def evaluate(cfg: DictConfig): | ||
| model = ppsci.arch.STAFNet(**cfg.MODEL) | ||
| eval_dataloader_cfg= { | ||
| "dataset": { | ||
| "name": "STAFNetDataset", | ||
| "file_path": cfg.EVAL.eval_data_path, | ||
| "input_keys": cfg.MODEL.input_keys, | ||
| "label_keys": cfg.MODEL.output_keys, | ||
| "seq_len": cfg.MODEL.seq_len, | ||
| "pred_len": cfg.MODEL.pred_len, | ||
| }, | ||
| "batch_size": cfg.TRAIN.batch_size, | ||
| "sampler": { | ||
| "name": "BatchSampler", | ||
| "drop_last": False, | ||
| "shuffle": True, | ||
HydrogenSulfate marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| }, | ||
| "num_workers": 0 | ||
| } | ||
| sup_validator = ppsci.validate.SupervisedValidator( | ||
| eval_dataloader_cfg, | ||
| loss=ppsci.loss.MSELoss("mean"), | ||
| metric={"MSE": ppsci.metric.MSE()}, | ||
| name="Sup_Validator", | ||
| ) | ||
| validator = {sup_validator.name: sup_validator} | ||
|
|
||
| # initialize solver | ||
| solver = ppsci.solver.Solver( | ||
| model, | ||
| validator=validator, | ||
| cfg=cfg, | ||
| pretrained_model_path=cfg.EVAL.pretrained_model_path, | ||
| compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch, | ||
| eval_with_no_grad=cfg.EVAL.eval_with_no_grad, | ||
| ) | ||
|
|
||
| # evaluate model | ||
| solver.eval() | ||
|
|
||
|
|
||
| @hydra.main(version_base=None, config_path="./conf", config_name="stafnet.yaml") | ||
| def main(cfg: DictConfig): | ||
| if cfg.mode == "train": | ||
| train(cfg) | ||
| elif cfg.mode == "eval": | ||
| evaluate(cfg) | ||
| else: | ||
| raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'") | ||
|
|
||
| if __name__ == "__main__": | ||
| multiprocessing.set_start_method("spawn") | ||
| main() | ||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
python stafnet.py DATASET.data_dir="Your train dataset path" EVAL.eval_data_path="Your evaluate dataset path"