![]()
- A self-hosted, privacy-focused transcription for Telegram -
🚀 No GPU Required • No API Keys • CPU-Only • Low Resource Usage ツ
🚀 No GPU Required • No API Keys • CPU-Only • Low Resource Usage ツ
- 🎙️ Voice Transcription - Convert voice messages to text instantly
- 🎵 Multi-Format Support - MP3, M4A, WAV, OGG, FLAC audio files
- ⚡ Concurrent Processing - Handle multiple users simultaneously
- 📝 Smart Text Handling - Auto-generate text files for long transcriptions
- 🧠 AI-Powered - OpenAI Whisper model for accurate transcription
- 💻 CPU-Only Processing - No GPU required, runs on basic servers (512MB RAM minimum)
- 🚫 No API Dependencies - No external API keys or cloud services needed
- 🐳 Docker Ready - Easy deployment with containerization
- 🔒 Privacy Focused - Process audio locally, complete data privacy
- 💰 Cost Effective - Ultra-low resource usage, perfect for budget hosting



{kind=link}
{kind=link}
Deploy instantly to your favorite cloud platform with pre-configured settings! All platforms support CPU-only deployment - no GPU needed!
- Docker and Docker Compose
- Telegram Bot Token (Create Bot)
-
Clone the repository
git clone https://github.com/Malith-Rukshan/whisper-transcriber-bot.git cd whisper-transcriber-bot -
Configure environment
cp .env.example .env nano .env # Add your bot token -
Download AI model
chmod +x download_model.sh ./download_model.sh
-
Deploy with Docker
docker-compose up -d
🎉 That's it! Your bot is now running and ready to transcribe audio!
| Command | Description |
|---|---|
/start |
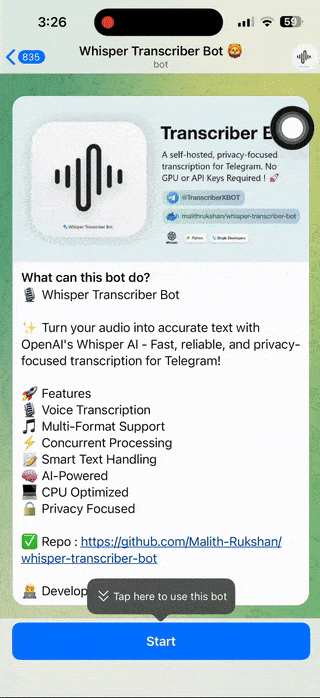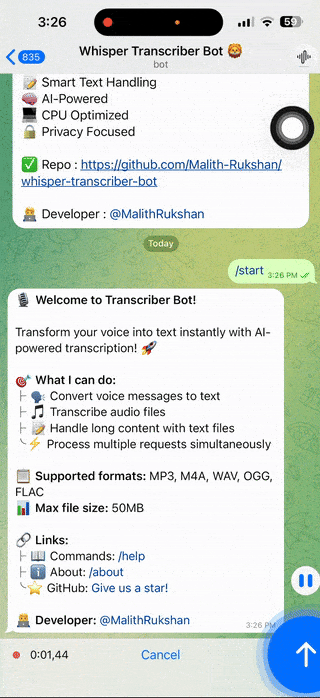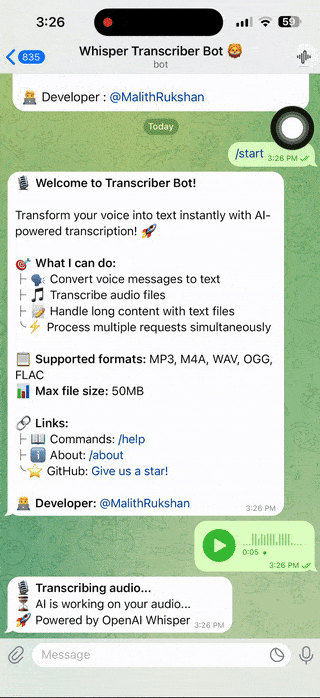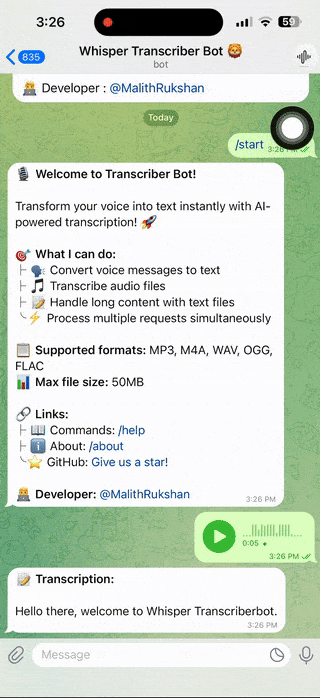
🏠 Welcome message and bot introduction |
/help |
📖 Detailed usage instructions |
/about |
ℹ️ Bot information and developer details |
/status |
🔍 Check bot health and configuration |
- Send Audio 🎙️ - Forward voice messages or upload audio files
- Wait for AI ⏳ - Bot processes audio (typically 1-3 seconds)
- Get Text 📝 - Receive transcription or download text file for long content
- Voice Messages - Direct Telegram voice notes
- Audio Files - MP3, M4A, WAV, OGG, FLAC (up to 50MB)
- Document Audio - Audio files sent as documents
Perfect for cloud platforms like Render, Railway, etc. The model is included in the image.
version: '3.8'
services:
whisper-bot:
image: malithrukshan/whisper-transcriber-bot:latest
container_name: whisper-transcriber-bot
restart: unless-stopped
environment:
- TELEGRAM_BOT_TOKEN=${TELEGRAM_BOT_TOKEN}For local development where you want to persist models between container rebuilds:
version: '3.8'
services:
whisper-bot:
image: malithrukshan/whisper-transcriber-bot:latest
container_name: whisper-transcriber-bot
restart: unless-stopped
environment:
- TELEGRAM_BOT_TOKEN=${TELEGRAM_BOT_TOKEN}
volumes:
- ./models:/app/models# Cloud deployment (model included in image)
docker run -d \
--name whisper-bot \
-e TELEGRAM_BOT_TOKEN=your_token_here \
malithrukshan/whisper-transcriber-bot:latest
# Local development (with volume mount)
docker run -d \
--name whisper-bot \
-e TELEGRAM_BOT_TOKEN=your_token_here \
-v $(pwd)/models:/app/models \
malithrukshan/whisper-transcriber-bot:latest# Clone and setup
git clone https://github.com/Malith-Rukshan/whisper-transcriber-bot.git
cd whisper-transcriber-bot
# Create virtual environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install dependencies
pip install -r requirements.txt
pip install -r requirements-dev.txt # Development dependencies
# Download model
./download_model.sh
# Configure environment
cp .env.example .env
# Add your bot token to .env
# Run bot
python src/bot.pywhisper-transcriber-bot/
├── src/ # Source code
│ ├── bot.py # Main bot application
│ ├── transcriber.py # Whisper integration
│ ├── config.py # Configuration management
│ └── utils.py # Utility functions
├── tests/ # Test files
│ ├── test_bot.py # Bot functionality tests
│ └── test_utils.py # Utility function tests
├── .github/workflows/ # CI/CD automation
├── models/ # AI model storage
├── Dockerfile # Container configuration
├── docker-compose.yml # Deployment setup
├── requirements.txt # Production dependencies
├── requirements-dev.txt # Development dependencies
└── README.md # This file
# Run all tests
python -m pytest
# Run with coverage
python -m pytest --cov=src
# Run specific test file
python -m pytest tests/test_bot.py
# Run with verbose output
python -m pytest -vThe test suite covers:
- ✅ Bot initialization and configuration
- ✅ Command handlers (
/start,/help,/about,/status) - ✅ Audio processing workflow
- ✅ Utility functions
- ✅ Error handling scenarios
# Format code
black src/ tests/
# Security check
bandit -r src/| Variable | Description | Default |
|---|---|---|
TELEGRAM_BOT_TOKEN |
Bot token from @BotFather | Required |
WHISPER_MODEL_PATH |
Path to Whisper model file | models/ggml-base.en.bin |
WHISPER_MODEL_NAME |
Model name for display | base.en |
BOT_USERNAME |
Bot username for branding | TranscriberXBOT |
MAX_AUDIO_SIZE_MB |
Maximum audio file size | 50 |
SUPPORTED_FORMATS |
Supported audio formats | mp3,m4a,wav,ogg,flac |
LOG_LEVEL |
Logging verbosity | INFO |
# Adjust CPU threads for transcription
export WHISPER_THREADS=4
# Set memory limits
export WHISPER_MAX_MEMORY=512M
# Configure concurrent processing
export MAX_CONCURRENT_TRANSCRIPTIONS=5| Audio Length | Processing Time | Memory Usage |
|---|---|---|
| 30 seconds | ~1.2 seconds | ~180MB |
| 2 minutes | ~2.8 seconds | ~200MB |
| 5 minutes | ~6.1 seconds | ~220MB |
- Single Instance: Handles 50+ concurrent users
- Minimal Resources: 1 CPU core, 512MB RAM minimum (no GPU required!)
- Storage: 1GB for model + temporary files
- Cost-Effective: Perfect for budget VPS hosting ($5-10/month)
- No External APIs: Zero ongoing API costs or dependencies
- Load Balancing: Deploy multiple instances for higher traffic
We welcome contributions! Please see our Contributing Guide for details.
- Fork the repository
- Create a feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
- Follow PEP 8 style guide
- Write tests for new features
- Update documentation
- Ensure Docker build succeeds
- Run quality checks before PR
- Framework: python-telegram-bot v22.2
- AI Model: OpenAI Whisper base.en (147MB, CPU-optimized)
- Bindings: pywhispercpp for C++ performance (no GPU needed)
- Runtime: Python 3.11 with asyncio for concurrent processing
- Container: Multi-architecture Docker (AMD64/ARM64)
- Resource: CPU-only inference, minimal memory footprint
- Async Processing: Non-blocking audio transcription
- Concurrent Handling: Multiple users supported simultaneously
- Memory Management: Efficient model loading and cleanup
- Error Recovery: Robust error handling and logging
This project is licensed under the MIT License - see the LICENSE file for details.
- OpenAI - For the incredible Whisper speech recognition model
- pywhispercpp - High-performance Python bindings for whisper.cpp
- python-telegram-bot - Excellent Telegram Bot API framework
- whisper.cpp - Optimized C++ implementation of Whisper
Malith Rukshan
- 🌐 Website: malith.dev
- 📧 Email: hello@malith.dev
- 🐦 Telegram: @MalithRukshan