@@ -732,6 +732,48 @@ if __name__ == "__main__":
732732
733733(TODO)
734734
735+ ### 数据集构建
736+
737+ 根据不同的模型,其所需要的指令也是不同的。如下是一个基于 DeepSeek + DeepSpeed 的数据集示例:
738+
739+ ```json
740+ {
741+ "instruction": "Write unit test for following code.\n<SomeCode>",
742+ "output": "<TestCode>"
743+ }
744+ ```
745+
746+ 下面是 LLaMA 模型的数据集示例:
747+
748+ ```json
749+ {
750+ "instruction": "Write unit test for following code.",
751+ "input": "<SomeCode>",
752+ "output": "<TestCode>"
753+ }
754+ ```
755+
756+ #### 数据集构建
757+
758+ 我们构建 [Unit Eval](https://github.com/unit-mesh/unit-eval) 项目,以生成更适合于 AutoDev 的数据集。
759+
760+ - 代码补全。行内(Inline)、块内(InBlock)、块间(AfterBlock)三种场景。
761+ - 单元测试生成。生成符合上下文的单元测试。
762+
763+ 详细见 Unit Eval 文档:https://github.com/unit-mesh/unit-eval
764+
765+ #### 开源数据集
766+
767+ 在 GitHub、HuggingFace 等平台上,有一些开源的数据集,如:
768+
769+ - [https://huggingface.co/datasets/ise-uiuc/Magicoder-OSS-Instruct-75K](https://huggingface.co/datasets/ise-uiuc/Magicoder-OSS-Instruct-75K)
770+
771+ 在 License 合适的情况下,我们可以直接使用这些数据集。
772+
773+ #### 数据蒸馏
774+
775+ 数据蒸馏。过去的定义是,即将大型真实数据集(训练集)作为输入,并输出一个小的合成蒸馏数据集。但是,我们要做的是直接用 OpenAI 生成预期的数据集。
776+
735777### 模型微调
736778
737779有监督微调(SFT)是指采用预先训练好的神经网络模型,并针对你自己的专门任务在少量的监督数据上对其进行重新训练的技术。
@@ -753,6 +795,8 @@ if __name__ == "__main__":
753795| 内部代码补全 | 大于 10,000 | 不需要 |
754796| IDE + 代码补全 | 大于 10,000 | 需要 |
755797
798+ 通常来说,我们测试是结合 IDE 的功能,以及代码补全的功能,因此,我们需要合并两个数据集。
799+
756800#### OpenBayes + DeepSeek 微调
757801
758802在这里我们使用的是,以及 DeepSeek 官方提供的脚本来进行微调。
@@ -771,41 +815,6 @@ if __name__ == "__main__":
771815- 详细的 Notebook 见:[code/finetune/finetune.ipynb](code/finetune/finetune.ipynb)
772816- 微调参数,详细见:[Trainer](https://huggingface.co/docs/transformers/v4.36.1/zh/main_classes/trainer)
773817
774- ### 数据集构建
775-
776- 根据不同的模型,其所需要的指令也是不同的。如下是一个基于 DeepSeek + DeepSpeed 的数据集示例:
777-
778- ```json
779- {
780- "instruction": "Write unit test for following code.\n<SomeCode>",
781- "output": "<TestCode>"
782- }
783- ```
784-
785- 下面是 LLaMA 模型的数据集示例:
786-
787- ```json
788- {
789- "instruction": "Write unit test for following code.",
790- "input": "<SomeCode>",
791- "output": "<TestCode>"
792- }
793- ```
794-
795- #### 数据集构建
796-
797- 我们构建 [Unit Eval](https://github.com/unit-mesh/unit-eval) 以生成更适合于 AutoDev 的数据集。
798-
799- #### 开源数据集
800-
801- 在 GitHub、HuggingFace 等平台上,有一些开源的数据集,如:
802-
803- - [https://huggingface.co/datasets/ise-uiuc/Magicoder-OSS-Instruct-75K](https://huggingface.co/datasets/ise-uiuc/Magicoder-OSS-Instruct-75K)
804-
805- #### 数据蒸馏
806-
807- 数据蒸馏。即将大型真实数据集(训练集)作为输入,并输出一个小的合成蒸馏数据集。
808-
809818## 步骤 3:围绕意图的数据工程与模型演进
810819
811820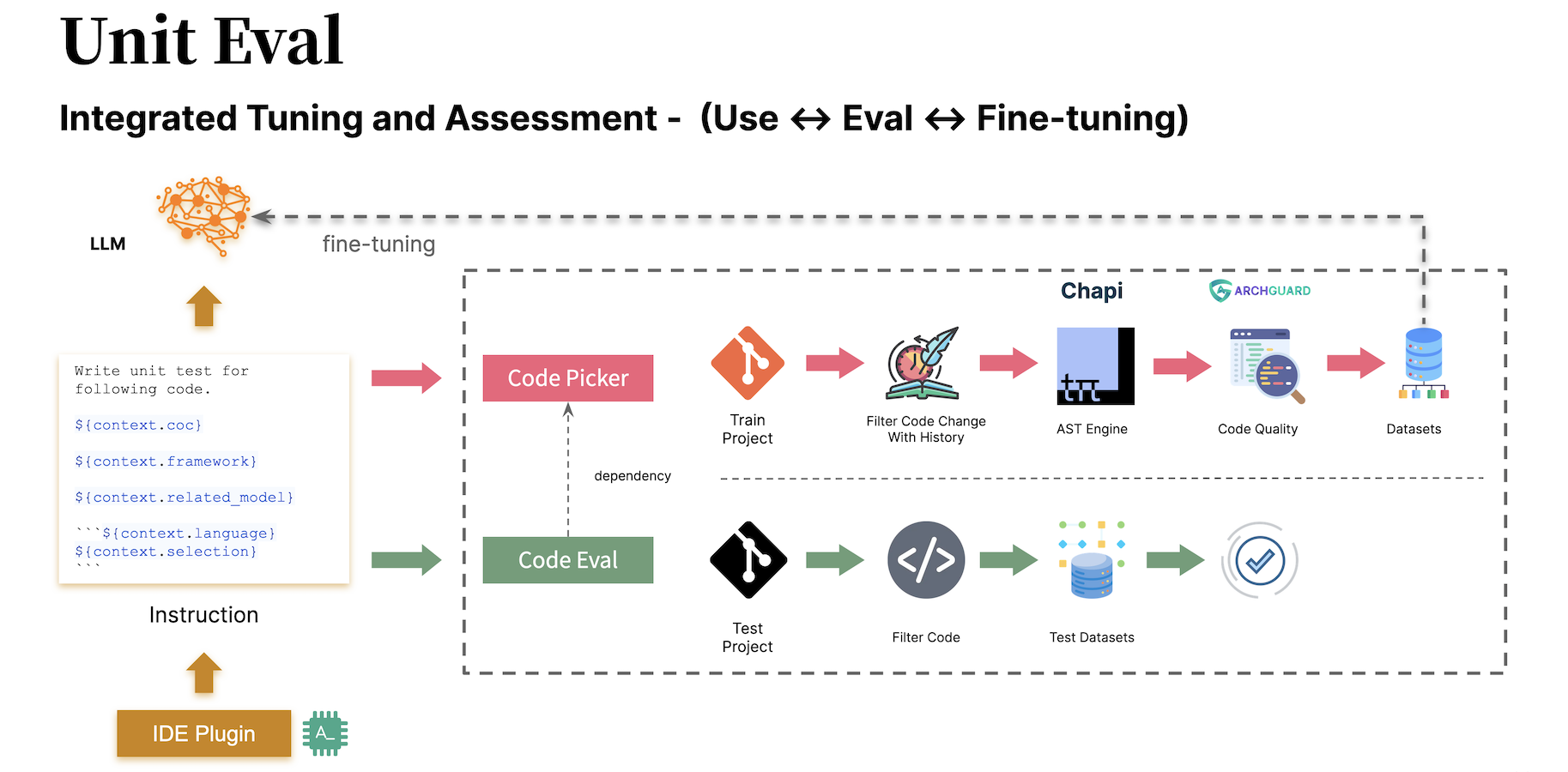
0 commit comments