diff --git a/README.md b/README.md
index 7379f1d0e..2d282c600 100644
--- a/README.md
+++ b/README.md
@@ -132,7 +132,7 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 问题类型 | 案例名称 | 优化算法 | 模型类型 | 训练方式 | 数据集 | 参考资料 |
|-----|---------|-----|---------|----|---------|---------|
-| 天气预报 | [Extformer-MoE 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/extformer_moe.md) | 数据驱动 | Transformer | 监督学习 | [enso](https://tianchi.aliyun.com/dataset/98942) | - |
+| 天气预报 | [Extformer-MoE 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/extformer_moe) | 数据驱动 | Transformer | 监督学习 | [enso](https://tianchi.aliyun.com/dataset/98942) | - |
| 天气预报 | [FourCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fourcastnet) | 数据驱动 | AFNO | 监督学习 | [ERA5](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://arxiv.org/pdf/2202.11214.pdf) |
| 天气预报 | [NowCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
| 天气预报 | [GraphCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/graphcast) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
@@ -142,11 +142,11 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 天气预报 | [Pangu-Weather 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/pangu_weather) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
| 大气污染物 | [STAFNet 污染物浓度预测](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/stafnet) | 数据驱动 | STAFNet | 监督学习 | [Data](https://quotsoft.net/air) | [Paper](https://link.springer.com/chapter/10.1007/978-3-031-78186-5_22) |
-| 天气预报 | [DGMR 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/dgmr.md) | 数据驱动 | GAN | 监督学习 | [UK dataset](https://huggingface.co/datasets/openclimatefix/nimrod-uk-1km) | [Paper](https://arxiv.org/pdf/2104.00954.pdf) |
-| 地震波形反演 | [VelocityGAN 地震波形反演](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/velocity_gan.md) | 数据驱动 | VelocityGAN | 监督学习 | [OpenFWI](https://openfwi-lanl.github.io/docs/data.html#vel) | [Paper](https://arxiv.org/abs/1809.10262v6) |
-| 交通预测 | [TGCN 交通流量预测](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/tgcn.md) | 数据驱动 | GCN & CNN | 监督学习 | [PEMSD4 & PEMSD8](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tgcn/tgcn_data.zip) | - |
-| 生成模型| [图像生成中的梯度惩罚应用](./zh/examples/wgan_gp.md)|数据驱动|WGAN GP|监督学习|[Data1](https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz)
[Data2](http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz)| [Paper](https://github.com/igul222/improved_wgan_training) |
-
+| 天气预报 | [DGMR 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/dgmr) | 数据驱动 | GAN | 监督学习 | [UK dataset](https://huggingface.co/datasets/openclimatefix/nimrod-uk-1km) | [Paper](https://arxiv.org/pdf/2104.00954.pdf) |
+| 地震波形反演 | [VelocityGAN 地震波形反演](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/velocity_gan) | 数据驱动 | VelocityGAN | 监督学习 | [OpenFWI](https://openfwi-lanl.github.io/docs/data.html#vel) | [Paper](https://arxiv.org/abs/1809.10262v6) |
+| 交通预测 | [TGCN 交通流量预测](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/tgcn) | 数据驱动 | GCN & CNN | 监督学习 | [PEMSD4 & PEMSD8](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tgcn/tgcn_data.zip) | - |
+| 遥感图像分割 | [UNetFormer 遥感图像分割](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/unetformer) | 数据驱动 | UNetFormer | 监督学习 | [Vaihingen](https://paperswithcode.com/dataset/isprs-vaihingen) | [Paper](https://github.com/WangLibo1995/GeoSeg) |
+| 生成模型| [图像生成中的梯度惩罚应用](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/wgan_gp)|数据驱动|WGAN GP|监督学习|[Data1](https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz)
[Data2](http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz)| [Paper](https://github.com/igul222/improved_wgan_training) |
## 🕘最近更新
diff --git a/docs/index.md b/docs/index.md
index 288e23199..830ec5582 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -161,6 +161,7 @@
| 大气污染物 | [STAFNet 污染物浓度预测](./zh/examples/stafnet.md) | 数据驱动 | STAFNet | 监督学习 | [Data](https://quotsoft.net/air) | [Paper](https://link.springer.com/chapter/10.1007/978-3-031-78186-5_22) |
| 天气预报 | [DGMR 气象预报](./zh/examples/dgmr.md) | 数据驱动 | GAN | 监督学习 | [UK dataset](https://huggingface.co/datasets/openclimatefix/nimrod-uk-1km) | [Paper](https://arxiv.org/pdf/2104.00954.pdf) |
| 地震波形反演 | [VelocityGAN 地震波形反演](./zh/examples/velocity_gan.md) | 数据驱动 | VelocityGAN | 监督学习 | [OpenFWI](https://openfwi-lanl.github.io/docs/data.html#vel) | [Paper](https://arxiv.org/abs/1809.10262v6) |
+ | 遥感图像分割 | [UNetFormer分割图像](./zh/examples/unetformer.md) | 数据驱动 | UNetformer | 监督学习 | [Vaihingen](https://paperswithcode.com/dataset/isprs-vaihingen) | [Paper](https://github.com/WangLibo1995/GeoSeg) |
| 交通预测 | [TGCN 交通流量预测](./zh/examples/tgcn.md) | 数据驱动 | GCN & CNN | 监督学习 | [PEMSD4 & PEMSD8](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tgcn/tgcn_data.zip) | - |
| 生成模型| [图像生成中的梯度惩罚应用](./zh/examples/wgan_gp.md)|数据驱动|WGAN GP|监督学习|[Data1](https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz)
[Data2](http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz)| [Paper](https://github.com/igul222/improved_wgan_training) |
diff --git a/docs/zh/examples/unetformer.md b/docs/zh/examples/unetformer.md
new file mode 100644
index 000000000..9598c7f5e
--- /dev/null
+++ b/docs/zh/examples/unetformer.md
@@ -0,0 +1,223 @@
+# UNetFormer
+
+!!! note
+
+ 1. 运行之前,建议快速了解一下[数据集](#31)和[数据读取方式](#32-dataset-api)。
+ 2. 将[Vaihingen数据集]下载到`data`目录中对应的子目录(如`data/vaihingen/train_images`)。
+ 3. 运行tools/vaihingen_patch_split.py处理原数据集,得到可供训练的数据。
+
+文件数据集结构如下
+```none
+airs
+├── unetformer(code)
+├── model_weights (save the model weights trained on ISPRS vaihingen)
+├── fig_results (save the masks predicted by models)
+├── lightning_logs (CSV format training logs)
+├── data
+│ ├── vaihingen
+│ │ ├── train_images (original)
+│ │ ├── train_masks (original)
+│ │ ├── test_images (original)
+│ │ ├── test_masks (original)
+│ │ ├── test_masks_eroded (original)
+│ │ ├── train (processed)
+│ │ ├── test (processed)
+```
+
+=== "模型训练命令"
+
+ ``` sh
+ # 将[Vaihingen数据集]下载到`data`目录中对应的子目录(如`data/vaihingen/train_images`)
+ # 创建训练数据集
+ python tools/vaihingen_patch_split.py --img-dir "data/vaihingen/train_images" --mask-dir "data/vaihingen/train_masks" --output-img-dir "data/vaihingen/train/images_1024" --output-mask-dir "data/vaihingen/train/masks_1024" --mode "train" --split-size 1024 --stride 512
+ # 创建测试数据集
+ python tools/vaihingen_patch_split.py --img-dir "data/vaihingen/test_images" --mask-dir "data/vaihingen/test_masks_eroded" --output-img-dir "data/vaihingen/test/images_1024" --output-mask-dir "data/vaihingen/test/masks_1024" --mode "val" --split-size 1024 --stride 1024 --eroded
+ # 创建masks_1024_rgb可视化数据集
+ python tools/vaihingen_patch_split.py --img-dir "data/vaihingen/test_images" --mask-dir "data/vaihingen/test_masks" --output-img-dir "data/vaihingen/test/images_1024" --output-mask-dir "data/vaihingen/test/masks_1024_rgb" --mode "val" --split-size 1024 --stride 1024 --gt
+ # 模型训练
+ python train_supervision.py -c config/vaihingen/unetformer.py
+ ```
+
+=== "模型评估命令"
+
+ ``` sh
+ # 下载处理好的[Vaihingen测试数据集](https://paddle-org.bj.bcebos.com/paddlescience/datasets/unetformer/test.zip),并解压。
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/unetformer/test.zip -P ./data/vaihingen/
+ unzip -q ./data/vaihingen/test.zip -d data/vaihingen/
+ # 下载预训练模型文件
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/models/unetformer/unetformer-r18-512-crop-ms-e105_epoch0_best.pdparams -P ./model_weights/vaihingen/unetformer-r18-512-crop-ms-e105/
+ python vaihingen_test.py -c config/vaihingen/unetformer.py -o fig_results/vaihingen/unetformer --rgb
+ ```
+
+## 1. 背景简介
+
+遥感城市场景图像的语义分割在众多实际应用中具有广泛需求,例如土地覆盖制图、城市变化检测、环境保护和经济评估等领域。在深度学习技术快速发展的推动下,卷积神经网络(CNN)多年来一直主导着语义分割领域。CNN采用分层特征表示方式,展现出强大的局部信息提取能力。然而卷积层的局部特性限制了网络捕获全局上下文信息的能力。近年来,作为计算机视觉领域的热点研究方向,Transformer架构在全局信息建模方面展现出巨大潜力,显著提升了图像分类、目标检测特别是语义分割等视觉相关任务的性能。
+
+本文提出了一种基于Transformer的解码器架构,构建了类UNet结构的Transformer网络(UNetFormer),用于实时城市场景分割。为实现高效分割,UNetFormer选择轻量级ResNet18作为编码器,并在解码器中开发了高效的全局-局部注意力机制,以同时建模全局和局部信息。本文提出的基于Transformer的解码器与Swin Transformer编码器结合后,在Vaihingen数据集上也取得了当前最佳性能(91.3% F1分数和84.1% mIoU)。
+
+## 2. 模型原理
+
+本段落仅简单介绍模型原理,具体细节请阅读[UNetFormer: A UNet-like Transformer for Efficient
+Semantic Segmentation of Remote Sensing Urban
+Scene Imagery](https://arxiv.org/abs/2109.08937)。
+
+### 2.1 模型结构
+
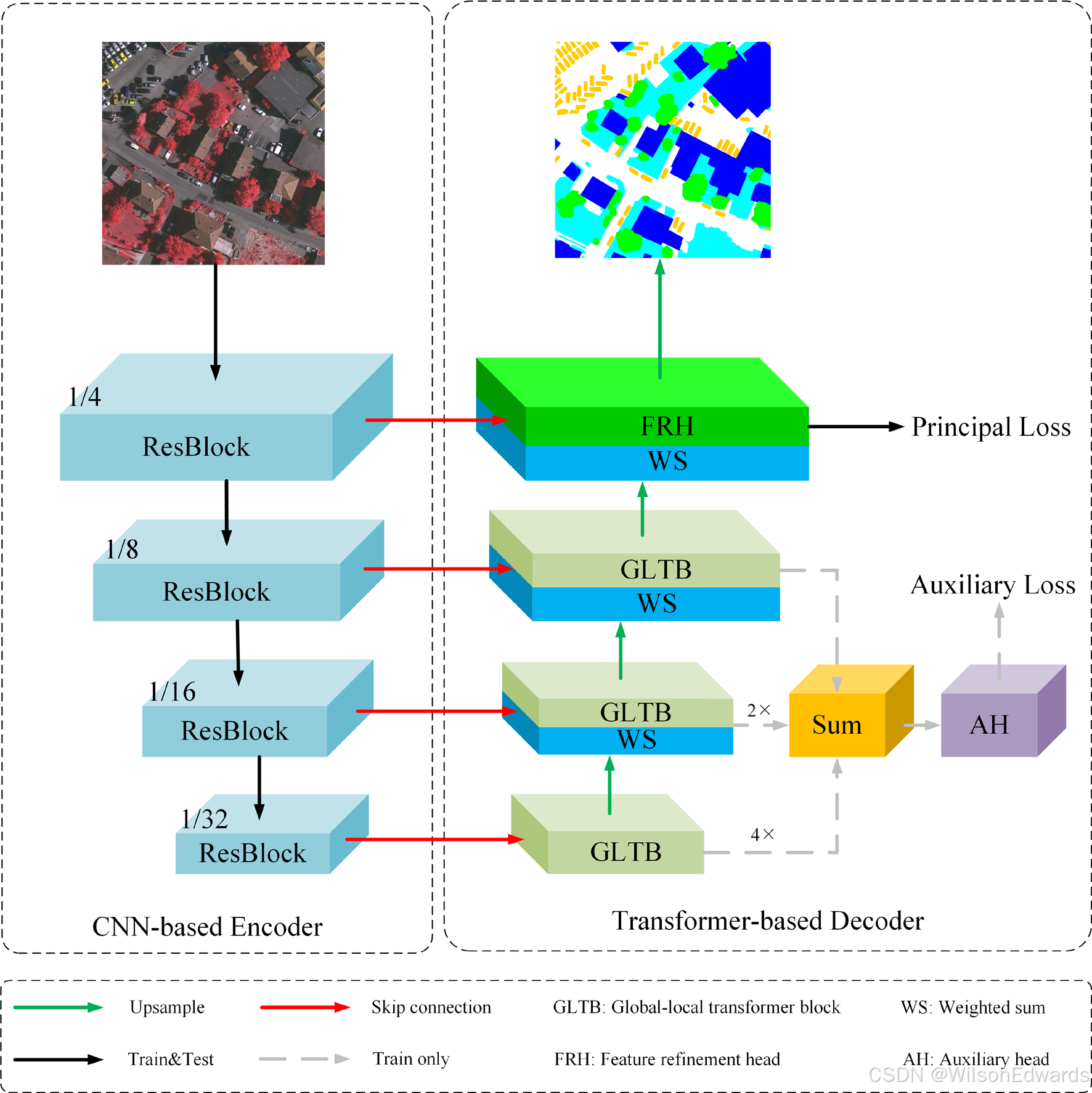
+UNetFormer是一种基于transformer的解码器的深度学习网络,下图显示了模型的整体结构。
+
+
+
+- `ResBlock`是resnet18网络的各个模块。
+
+- `GLTB`由全局-局部注意、MLP、两个batchnorm层和两个加和操作组成。
+
+### 2.2 损失函数
+
+判别器的损失函数由两部分组成,主损失函数$\mathcal{L}_{\text {p }}$为SoftCrossEntropyLoss交叉熵损失函数$\mathcal{L}_{c e}$和DiceLoss损失函数$\mathcal{L}_{\text {dice }}$。其表达式为:
+
+$$
+\mathcal{L}_{c e}=-\frac{1}{N} \sum_{n=1}^{N} \sum_{k=1}^{K} y_{k}^{(n)} \log \hat{y}_{k}^{(n)}
+$$
+
+$$
+\mathcal{L}_{\text {dice }}=1-\frac{2}{N} \sum_{n=1}^{N} \sum_{k=1}^{K} \frac{\hat{y}_{k}^{(n)} y_{k}^{(n)}}{\hat{y}_{k}^{(n)}+y_{k}^{(n)}}
+$$
+
+$$
+\mathcal{L}_{\text {p }}=\mathcal{L}_{c e}+\mathcal{L}_{\text {dice }}
+$$
+
+其中N、K分别表示样本数量和类别数量。$y^{(n)}$和$\hat{y}^{(n)}$表示标签的one-hot编码和相应的softmax输出,$\mathrm{n} \in[1, \ldots, \mathrm{n}]$。
+
+为了更好的结合,我们选择交叉熵函数作为辅助损失函数${L}_{a u x}$,并且乘以系数$\alpha$总损失函数其表达式为:
+
+$$
+\mathcal{L}=\mathcal{L}_{p}+\alpha \times \mathcal{L}_{a u x}
+$$
+
+其中,$\alpha$默认为0.4。
+
+## 3. 模型构建
+以下我们讲解释用PaddleScience构建UnetFormer的关键部分。
+
+### 3.1 数据集介绍
+
+数据集采用了[ISPRS](https://www.isprs.org/)开源的[Vaihingen](https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx)数据集。
+
+ISPRS提供了城市分类和三维建筑重建测试项目的两个最先进的机载图像数据集。该数据集采用了由高分辨率正交照片和相应的密集图像匹配技术产生的数字地表模型(DSM)。这两个数据集区域都涵盖了城市场景。Vaihingen是一个相对较小的村庄,有许多独立的建筑和小的多层建筑,该数据集包含33幅不同大小的遥感图像,每幅图像都是从一个更大的顶层正射影像图片提取的,图像选择的过程避免了出现没有数据的情况。顶层影像和DSM的空间分辨率为9 cm。遥感图像格式为8位TIFF文件,由近红外、红色和绿色3个波段组成。DSM是单波段的TIFF文件,灰度等级(对应于DSM高度)为32位浮点值编码。
+
+
+
+每个数据集已手动分类为6个最常见的土地覆盖类别。
+
+①不透水面 (RGB: 255, 255, 255)
+
+②建筑物(RGB: 0, 0, 255)
+
+③低矮植被 (RGB: 0, 255, 255)
+
+④树木 (RGB: 0, 255, 0)
+
+⑤汽车(RGB: 255, 255, 0)
+
+⑥背景 (RGB: 255, 0, 0)
+
+背景类包括水体和与其他已定义类别不同的物体(例如容器、网球场、游泳池),这些物体通常属于城市场景中的不感兴趣的语义对象。
+
+### 3.2 构建dataset API
+
+由于一份数据集由33个超大遥感图片组成组成。为了方便训练,我们自定义一个图像分割程序,将原始图片分割为1024×1024大小的可训练图片,程序代码具体信息在GeoSeg/tools/vaihingen_patch_split.py中可以看到。
+
+### 3.3 模型构建
+
+本案例的模型搭建代码如下
+
+
+
+参数配置如下:
+``` py linenums="12"
+--8<--
+examples/unetformer/config/vaihingen/unetformer.py:12:36
+--8<--
+```
+
+### 3.4 loss函数
+
+UNetFormer的损失函数由SoftCrossEntropyLoss交叉熵损失函数和DiceLoss损失函数组成
+
+#### 3.4.1 SoftCrossEntropyLoss
+
+
+``` py linenums="13"
+--8<--
+examples/unetformer/geoseg/losses/soft_ce.py:13:43
+--8<--
+```
+
+#### 3.4.2 DiceLoss
+
+``` py linenums="36"
+--8<--
+examples/unetformer/geoseg/losses/dice.py:36:145
+--8<--
+```
+
+#### 3.4.2 JointLoss
+SoftCrossEntropyLoss和DiceLoss将使用JointLoss进行组合
+
+``` py linenums="23"
+--8<--
+examples/unetformer/geoseg/losses/joint_loss.py:23:40
+--8<--
+```
+#### 3.4.2 UNetFormerLoss
+``` py linenums="93"
+--8<--
+examples/unetformer/geoseg/losses/useful_loss.py:93:114
+--8<--
+```
+
+### 3.5 优化器构建
+
+UNetFormer使用AdamW优化器,可直接调用`paddle.optimizer.AdamW`构建,代码如下:
+
+``` py linenums="65"
+--8<--
+examples/unetformer/config/vaihingen/unetformer.py:65:76
+--8<--
+```
+
+### 3.6 模型训练
+
+``` py linenums="236"
+--8<--
+examples/unetformer/train_supervision.py:236:300
+--8<--
+```
+
+
+### 3.7 模型测试
+
+``` py linenums="61"
+--8<--
+examples/unetformer/vaihingen_test.py:61:121
+--8<--
+```
+
+## 4. 结果展示
+
+使用[Vaihingen](https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx)数据集的训练结果。
+
+| F1 | mIOU | OA |
+| :----: | :----: | :----: |
+| 0.9062 | 0.8318 | 0.9283 |
+
+
+
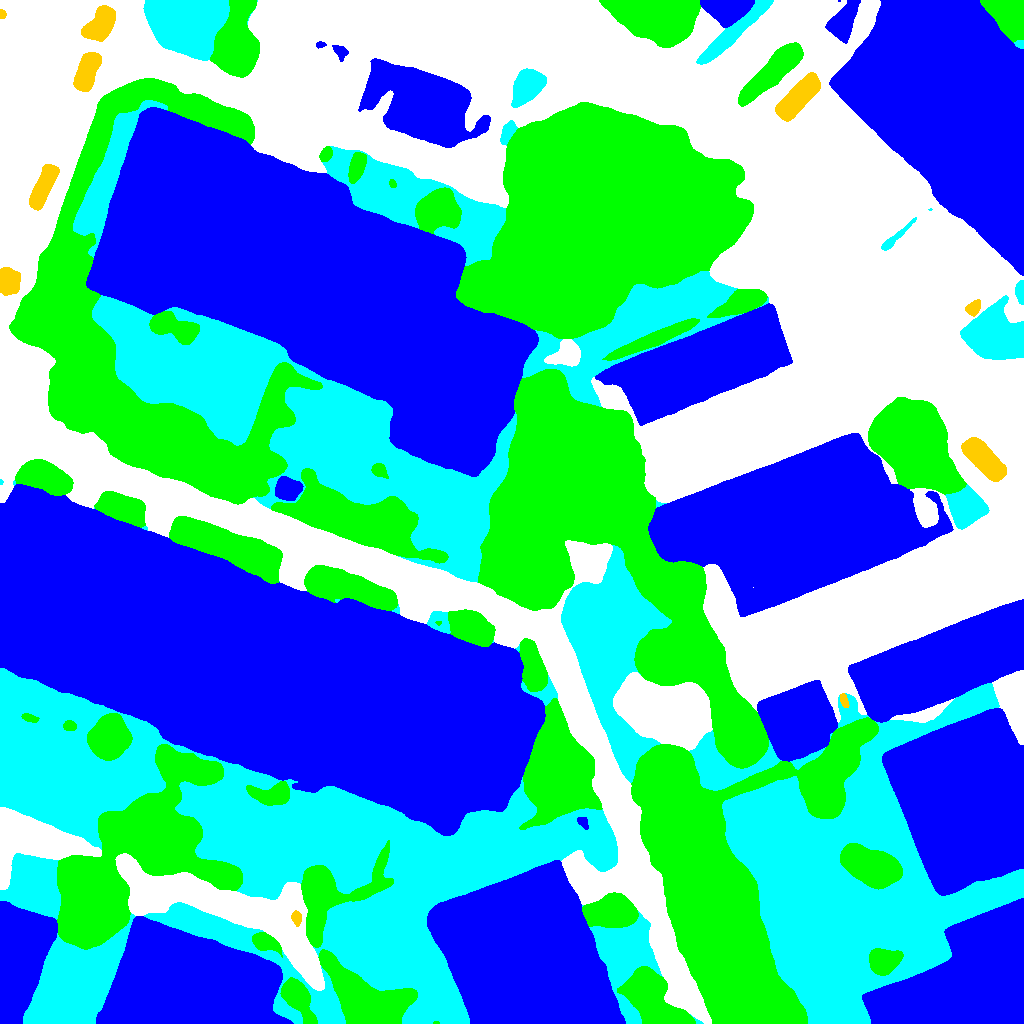
+
+
+两张图片对比可以看出模型已经精确地分割出遥感图片中建筑、树木、汽车等物体的轮廓,并且很好地处理了重叠区域。
+## 6. 参考文献
+
+- [UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery](https://arxiv.org/abs/2109.08937)
+- [https://github.com/WangLibo1995/GeoSeg](https://github.com/WangLibo1995/GeoSeg)
diff --git a/examples/unetformer/config/vaihingen/unetformer.py b/examples/unetformer/config/vaihingen/unetformer.py
new file mode 100644
index 000000000..ba046fc32
--- /dev/null
+++ b/examples/unetformer/config/vaihingen/unetformer.py
@@ -0,0 +1,76 @@
+import os
+
+import paddle
+from geoseg.datasets.vaihingen_dataset import CLASSES
+from geoseg.datasets.vaihingen_dataset import VaihingenDataset
+from geoseg.datasets.vaihingen_dataset import train_aug
+from geoseg.datasets.vaihingen_dataset import val_aug
+from geoseg.losses.useful_loss import UnetFormerLoss
+from geoseg.models.UNetFormer import UNetFormer
+from tools.utils import process_model_params
+
+max_epoch = 105
+ignore_index = len(CLASSES)
+train_batch_size = 8
+val_batch_size = 8
+lr = 0.0006
+weight_decay = 0.01
+backbone_lr = 6e-05
+backbone_weight_decay = 0.01
+num_classes = len(CLASSES)
+classes = CLASSES
+weights_name = "unetformer-r18-512-crop-ms-e105"
+weights_path = "model_weights/vaihingen/{}".format(weights_name)
+test_weights_name = "unetformer-r18-512-crop-ms-e105_epoch0_best"
+log_name = "vaihingen/{}".format(weights_name)
+monitor = "val_F1"
+monitor_mode = "max"
+save_top_k = 1
+save_last = True
+check_val_every_n_epoch = 1
+pretrained_ckpt_path = None
+gpus = "auto"
+resume_ckpt_path = None
+net = UNetFormer(num_classes=num_classes)
+loss = UnetFormerLoss(ignore_index=ignore_index)
+use_aux_loss = True
+os.makedirs("data/vaihingen/train/images_1024", exist_ok=True)
+os.makedirs("data/vaihingen/train/masks_1024", exist_ok=True)
+if len(os.listdir("data/vaihingen/train/images_1024")) == 0:
+ pass
+else:
+ train_dataset = VaihingenDataset(
+ data_root="data/vaihingen/train",
+ mode="train",
+ mosaic_ratio=0.25,
+ transform=train_aug,
+ )
+ train_loader = paddle.io.DataLoader(
+ dataset=train_dataset,
+ batch_size=train_batch_size,
+ num_workers=4,
+ shuffle=True,
+ drop_last=True,
+ )
+val_dataset = VaihingenDataset(transform=val_aug)
+test_dataset = VaihingenDataset(data_root="data/vaihingen/test", transform=val_aug)
+
+val_loader = paddle.io.DataLoader(
+ dataset=val_dataset,
+ batch_size=val_batch_size,
+ num_workers=4,
+ shuffle=False,
+ drop_last=False,
+)
+layerwise_params = {
+ "backbone.*": dict(lr=backbone_lr, weight_decay=backbone_weight_decay)
+}
+net_params = process_model_params(net, layerwise_params=layerwise_params)
+optimizer = paddle.optimizer.AdamW(
+ parameters=net_params, learning_rate=lr, weight_decay=weight_decay
+)
+tmp_lr = paddle.optimizer.lr.CosineAnnealingWarmRestarts(
+ T_0=15, T_mult=2, learning_rate=optimizer.get_lr()
+)
+optimizer.set_lr_scheduler(tmp_lr)
+lr_scheduler = tmp_lr
diff --git a/examples/unetformer/geoseg/__init__.py b/examples/unetformer/geoseg/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/examples/unetformer/geoseg/datasets/__init__.py b/examples/unetformer/geoseg/datasets/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/examples/unetformer/geoseg/datasets/transform.py b/examples/unetformer/geoseg/datasets/transform.py
new file mode 100644
index 000000000..323baf472
--- /dev/null
+++ b/examples/unetformer/geoseg/datasets/transform.py
@@ -0,0 +1,255 @@
+import numbers
+import random
+
+import numpy as np
+from PIL import Image
+from PIL import ImageEnhance
+from PIL import ImageOps
+
+
+class Compose(object):
+ def __init__(self, transforms):
+ self.transforms = transforms
+
+ def __call__(self, img, mask):
+ assert img.size == mask.size
+ for t in self.transforms:
+ img, mask = t(img, mask)
+ return img, mask
+
+
+class RandomCrop(object):
+ """
+ Take a random crop from the image.
+ First the image or crop size may need to be adjusted if the incoming image
+ is too small...
+ If the image is smaller than the crop, then:
+ the image is padded up to the size of the crop
+ unless 'nopad', in which case the crop size is shrunk to fit the image
+ A random crop is taken such that the crop fits within the image.
+ If a centroid is passed in, the crop must intersect the centroid.
+ """
+
+ def __init__(self, size=512, ignore_index=12, nopad=True):
+ if isinstance(size, numbers.Number):
+ self.size = int(size), int(size)
+ else:
+ self.size = size
+ self.ignore_index = ignore_index
+ self.nopad = nopad
+ self.pad_color = 0, 0, 0
+
+ def __call__(self, img, mask, centroid=None):
+ assert img.size == mask.size
+ w, h = img.size
+ th, tw = self.size
+ if w == tw and h == th:
+ return img, mask
+ if self.nopad:
+ if th > h or tw > w:
+ shorter_side = min(w, h)
+ th, tw = shorter_side, shorter_side
+ else:
+ if th > h:
+ pad_h = (th - h) // 2 + 1
+ else:
+ pad_h = 0
+ if tw > w:
+ pad_w = (tw - w) // 2 + 1
+ else:
+ pad_w = 0
+ border = pad_w, pad_h, pad_w, pad_h
+ if pad_h or pad_w:
+ img = ImageOps.expand(img, border=border, fill=self.pad_color)
+ mask = ImageOps.expand(mask, border=border, fill=self.ignore_index)
+ w, h = img.size
+ if centroid is not None:
+ c_x, c_y = centroid
+ max_x = w - tw
+ max_y = h - th
+ x1 = random.randint(c_x - tw, c_x)
+ x1 = min(max_x, max(0, x1))
+ y1 = random.randint(c_y - th, c_y)
+ y1 = min(max_y, max(0, y1))
+ else:
+ if w == tw:
+ x1 = 0
+ else:
+ x1 = random.randint(0, w - tw)
+ if h == th:
+ y1 = 0
+ else:
+ y1 = random.randint(0, h - th)
+ return img.crop((x1, y1, x1 + tw, y1 + th)), mask.crop(
+ (x1, y1, x1 + tw, y1 + th)
+ )
+
+
+class PadImage(object):
+ def __init__(self, size=(512, 512), ignore_index=0):
+ self.size = size
+ self.ignore_index = ignore_index
+
+ def __call__(self, img, mask):
+ assert img.size == mask.size
+ th, tw = self.size, self.size
+ w, h = img.size
+ if w > tw or h > th:
+ wpercent = tw / float(w)
+ target_h = int(float(img.size[1]) * float(wpercent))
+ img, mask = img.resize((tw, target_h), Image.BICUBIC), mask.resize(
+ (tw, target_h), Image.NEAREST
+ )
+ w, h = img.size
+ img = ImageOps.expand(img, border=(0, 0, tw - w, th - h), fill=0)
+ mask = ImageOps.expand(
+ mask, border=(0, 0, tw - w, th - h), fill=self.ignore_index
+ )
+ return img, mask
+
+
+class RandomHorizontalFlip(object):
+ def __init__(self, prob: float = 0.5):
+ self.prob = prob
+
+ def __call__(self, img, mask=None):
+ if mask is not None:
+ if random.random() < self.prob:
+ return img.transpose(Image.FLIP_LEFT_RIGHT), mask.transpose(
+ Image.FLIP_LEFT_RIGHT
+ )
+ else:
+ return img, mask
+ elif random.random() < self.prob:
+ return img.transpose(Image.FLIP_LEFT_RIGHT)
+ else:
+ return img
+
+
+class RandomVerticalFlip(object):
+ def __init__(self, prob: float = 0.5):
+ self.prob = prob
+
+ def __call__(self, img, mask=None):
+ if mask is not None:
+ if random.random() < self.prob:
+ return img.transpose(Image.FLIP_TOP_BOTTOM), mask.transpose(
+ Image.FLIP_TOP_BOTTOM
+ )
+ else:
+ return img, mask
+ elif random.random() < self.prob:
+ return img.transpose(Image.FLIP_TOP_BOTTOM)
+ else:
+ return img
+
+
+class Resize(object):
+ def __init__(self, size: tuple = (512, 512)):
+ self.size = size
+
+ def __call__(self, img, mask):
+ assert img.size == mask.size
+ return img.resize(self.size, Image.BICUBIC), mask.resize(
+ self.size, Image.NEAREST
+ )
+
+
+class RandomScale(object):
+ def __init__(self, scale_list=[0.75, 1.0, 1.25], mode="value"):
+ self.scale_list = scale_list
+ self.mode = mode
+
+ def __call__(self, img, mask):
+ oh, ow = img.size
+ scale_amt = 1.0
+ if self.mode == "value":
+ scale_amt = np.random.choice(self.scale_list, 1)
+ elif self.mode == "range":
+ scale_amt = random.uniform(self.scale_list[0], self.scale_list[-1])
+ h = int(scale_amt * oh)
+ w = int(scale_amt * ow)
+ return img.resize((w, h), Image.BICUBIC), mask.resize((w, h), Image.NEAREST)
+
+
+class ColorJitter(object):
+ def __init__(self, brightness=0.5, contrast=0.5, saturation=0.5):
+ if brightness is not None and brightness > 0:
+ self.brightness = [max(1 - brightness, 0), 1 + brightness]
+ if contrast is not None and contrast > 0:
+ self.contrast = [max(1 - contrast, 0), 1 + contrast]
+ if saturation is not None and saturation > 0:
+ self.saturation = [max(1 - saturation, 0), 1 + saturation]
+
+ def __call__(self, img, mask=None):
+ r_brightness = random.uniform(self.brightness[0], self.brightness[1])
+ r_contrast = random.uniform(self.contrast[0], self.contrast[1])
+ r_saturation = random.uniform(self.saturation[0], self.saturation[1])
+ img = ImageEnhance.Brightness(img).enhance(r_brightness)
+ img = ImageEnhance.Contrast(img).enhance(r_contrast)
+ img = ImageEnhance.Color(img).enhance(r_saturation)
+ if mask is None:
+ return img
+ else:
+ return img, mask
+
+
+class SmartCropV1(object):
+ def __init__(self, crop_size=512, max_ratio=0.75, ignore_index=12, nopad=False):
+ self.crop_size = crop_size
+ self.max_ratio = max_ratio
+ self.ignore_index = ignore_index
+ self.crop = RandomCrop(crop_size, ignore_index=ignore_index, nopad=nopad)
+
+ def __call__(self, img, mask):
+ assert img.size == mask.size
+ count = 0
+ while True:
+ img_crop, mask_crop = self.crop(img.copy(), mask.copy())
+ count += 1
+ labels, cnt = np.unique(np.array(mask_crop), return_counts=True)
+ cnt = cnt[labels != self.ignore_index]
+ if len(cnt) > 1 and np.max(cnt) / np.sum(cnt) < self.max_ratio:
+ break
+ if count > 10:
+ break
+ return img_crop, mask_crop
+
+
+class SmartCropV2(object):
+ def __init__(
+ self,
+ crop_size=512,
+ num_classes=13,
+ class_interest=[2, 3],
+ class_ratio=[0.1, 0.25],
+ max_ratio=0.75,
+ ignore_index=12,
+ nopad=True,
+ ):
+ self.crop_size = crop_size
+ self.num_classes = num_classes
+ self.class_interest = class_interest
+ self.class_ratio = class_ratio
+ self.max_ratio = max_ratio
+ self.ignore_index = ignore_index
+ self.crop = RandomCrop(crop_size, ignore_index=ignore_index, nopad=nopad)
+
+ def __call__(self, img, mask):
+ assert img.size == mask.size
+ count = 0
+ while True:
+ img_crop, mask_crop = self.crop(img.copy(), mask.copy())
+ count += 1
+ bins = np.array(range(self.num_classes + 1))
+ class_pixel_counts, _ = np.histogram(np.array(mask_crop), bins=bins)
+ cf = class_pixel_counts / (self.crop_size * self.crop_size)
+ cf = np.array(cf)
+ for c, f in zip(self.class_interest, self.class_ratio):
+ if cf[c] > f:
+ break
+ if np.max(cf) < 0.75 and np.argmax(cf) != self.ignore_index:
+ break
+ if count > 10:
+ break
+ return img_crop, mask_crop
diff --git a/examples/unetformer/geoseg/datasets/vaihingen_dataset.py b/examples/unetformer/geoseg/datasets/vaihingen_dataset.py
new file mode 100644
index 000000000..2fa6a4e5e
--- /dev/null
+++ b/examples/unetformer/geoseg/datasets/vaihingen_dataset.py
@@ -0,0 +1,272 @@
+import os
+import random
+
+import albumentations as albu
+import cv2
+import matplotlib.patches as mpatches
+import matplotlib.pyplot as plt
+import numpy as np
+import paddle
+from PIL import Image
+
+from .transform import Compose
+from .transform import RandomScale
+from .transform import SmartCropV1
+
+CLASSES = "ImSurf", "Building", "LowVeg", "Tree", "Car", "Clutter"
+PALETTE = [
+ [255, 255, 255],
+ [0, 0, 255],
+ [0, 255, 255],
+ [0, 255, 0],
+ [255, 204, 0],
+ [255, 0, 0],
+]
+ORIGIN_IMG_SIZE = 1024, 1024
+INPUT_IMG_SIZE = 1024, 1024
+TEST_IMG_SIZE = 1024, 1024
+
+
+def get_training_transform():
+ train_transform = [albu.RandomRotate90(p=0.5), albu.Normalize()]
+ return albu.Compose(train_transform)
+
+
+def train_aug(img, mask):
+ crop_aug = Compose(
+ [
+ RandomScale(scale_list=[0.5, 0.75, 1.0, 1.25, 1.5], mode="value"),
+ SmartCropV1(
+ crop_size=512, max_ratio=0.75, ignore_index=len(CLASSES), nopad=False
+ ),
+ ]
+ )
+ img, mask = crop_aug(img, mask)
+ img, mask = np.array(img), np.array(mask)
+ aug = get_training_transform()(image=img.copy(), mask=mask.copy())
+ img, mask = aug["image"], aug["mask"]
+ return img, mask
+
+
+def get_val_transform():
+ val_transform = [albu.Normalize()]
+ return albu.Compose(val_transform)
+
+
+def val_aug(img, mask):
+ img, mask = np.array(img), np.array(mask)
+ aug = get_val_transform()(image=img.copy(), mask=mask.copy())
+ img, mask = aug["image"], aug["mask"]
+ return img, mask
+
+
+class VaihingenDataset(paddle.io.Dataset):
+ def __init__(
+ self,
+ data_root="data/vaihingen/test",
+ mode="val",
+ img_dir="images_1024",
+ mask_dir="masks_1024",
+ img_suffix=".tif",
+ mask_suffix=".png",
+ transform=val_aug,
+ mosaic_ratio=0.0,
+ img_size=ORIGIN_IMG_SIZE,
+ ):
+ self.data_root = data_root
+ if not os.path.exists(self.data_root):
+ os.makedirs(self.data_root, exist_ok=True)
+ self.img_dir = img_dir
+ self.mask_dir = mask_dir
+ self.img_suffix = img_suffix
+ self.mask_suffix = mask_suffix
+ self.transform = transform
+ self.mode = mode
+ self.mosaic_ratio = mosaic_ratio
+ self.img_size = img_size
+ self.img_ids = self.get_img_ids(self.data_root, self.img_dir, self.mask_dir)
+
+ def __getitem__(self, index):
+ p_ratio = random.random()
+ if p_ratio > self.mosaic_ratio or self.mode == "val" or self.mode == "test":
+ img, mask = self.load_img_and_mask(index)
+ if self.transform:
+ img, mask = self.transform(img, mask)
+ else:
+ img, mask = self.load_mosaic_img_and_mask(index)
+ if self.transform:
+ img, mask = self.transform(img, mask)
+ img = (
+ paddle.to_tensor(data=img).transpose(perm=[2, 0, 1]).astype(dtype="float32")
+ )
+ mask = paddle.to_tensor(data=mask).astype(dtype="int64")
+ img_id = self.img_ids[index]
+ results = dict(img_id=img_id, img=img, gt_semantic_seg=mask)
+ return results
+
+ def __len__(self):
+ return len(self.img_ids)
+
+ def get_img_ids(self, data_root, img_dir, mask_dir):
+ img_filename_list = os.path.join(os.path.join(data_root, img_dir))
+ mask_filename_list = os.path.join(os.path.join(data_root, mask_dir))
+ os.makedirs(img_filename_list, exist_ok=True)
+ os.makedirs(mask_filename_list, exist_ok=True)
+ img_filename_list = os.listdir(os.path.join(data_root, img_dir))
+ mask_filename_list = os.listdir(os.path.join(data_root, mask_dir))
+ assert len(img_filename_list) == len(mask_filename_list)
+ img_ids = [str(id.split(".")[0]) for id in mask_filename_list]
+ return img_ids
+
+ def load_img_and_mask(self, index):
+ img_id = self.img_ids[index]
+ img_name = os.path.join(self.data_root, self.img_dir, img_id + self.img_suffix)
+ mask_name = os.path.join(
+ self.data_root, self.mask_dir, img_id + self.mask_suffix
+ )
+ img = Image.open(img_name).convert("RGB")
+ mask = Image.open(mask_name).convert("L")
+ return img, mask
+
+ def load_mosaic_img_and_mask(self, index):
+ indexes = [index] + [random.randint(0, len(self.img_ids) - 1) for _ in range(3)]
+ img_a, mask_a = self.load_img_and_mask(indexes[0])
+ img_b, mask_b = self.load_img_and_mask(indexes[1])
+ img_c, mask_c = self.load_img_and_mask(indexes[2])
+ img_d, mask_d = self.load_img_and_mask(indexes[3])
+ img_a, mask_a = np.array(img_a), np.array(mask_a)
+ img_b, mask_b = np.array(img_b), np.array(mask_b)
+ img_c, mask_c = np.array(img_c), np.array(mask_c)
+ img_d, mask_d = np.array(img_d), np.array(mask_d)
+ h = self.img_size[0]
+ w = self.img_size[1]
+ start_x = w // 4
+ strat_y = h // 4
+ offset_x = random.randint(start_x, w - start_x)
+ offset_y = random.randint(strat_y, h - strat_y)
+ crop_size_a = offset_x, offset_y
+ crop_size_b = w - offset_x, offset_y
+ crop_size_c = offset_x, h - offset_y
+ crop_size_d = w - offset_x, h - offset_y
+ random_crop_a = albu.RandomCrop(width=crop_size_a[0], height=crop_size_a[1])
+ random_crop_b = albu.RandomCrop(width=crop_size_b[0], height=crop_size_b[1])
+ random_crop_c = albu.RandomCrop(width=crop_size_c[0], height=crop_size_c[1])
+ random_crop_d = albu.RandomCrop(width=crop_size_d[0], height=crop_size_d[1])
+ croped_a = random_crop_a(image=img_a.copy(), mask=mask_a.copy())
+ croped_b = random_crop_b(image=img_b.copy(), mask=mask_b.copy())
+ croped_c = random_crop_c(image=img_c.copy(), mask=mask_c.copy())
+ croped_d = random_crop_d(image=img_d.copy(), mask=mask_d.copy())
+ img_crop_a, mask_crop_a = croped_a["image"], croped_a["mask"]
+ img_crop_b, mask_crop_b = croped_b["image"], croped_b["mask"]
+ img_crop_c, mask_crop_c = croped_c["image"], croped_c["mask"]
+ img_crop_d, mask_crop_d = croped_d["image"], croped_d["mask"]
+ top = np.concatenate((img_crop_a, img_crop_b), axis=1)
+ bottom = np.concatenate((img_crop_c, img_crop_d), axis=1)
+ img = np.concatenate((top, bottom), axis=0)
+ top_mask = np.concatenate((mask_crop_a, mask_crop_b), axis=1)
+ bottom_mask = np.concatenate((mask_crop_c, mask_crop_d), axis=1)
+ mask = np.concatenate((top_mask, bottom_mask), axis=0)
+ mask = np.ascontiguousarray(mask)
+ img = np.ascontiguousarray(img)
+ img = Image.fromarray(img)
+ mask = Image.fromarray(mask)
+ return img, mask
+
+
+def show_img_mask_seg(seg_path, img_path, mask_path, start_seg_index):
+ seg_list = os.listdir(seg_path)
+ seg_list = [f for f in seg_list if f.endswith(".png")]
+ fig, ax = plt.subplots(2, 3, figsize=(18, 12))
+ seg_list = seg_list[start_seg_index : start_seg_index + 2]
+ patches = [
+ mpatches.Patch(color=np.array(PALETTE[i]) / 255.0, label=CLASSES[i])
+ for i in range(len(CLASSES))
+ ]
+ for i in range(len(seg_list)):
+ seg_id = seg_list[i]
+ img_seg = cv2.imread(f"{seg_path}/{seg_id}", cv2.IMREAD_UNCHANGED)
+ img_seg = img_seg.astype(np.uint8)
+ img_seg = Image.fromarray(img_seg).convert("P")
+ img_seg.putpalette(np.array(PALETTE, dtype=np.uint8))
+ img_seg = np.array(img_seg.convert("RGB"))
+ mask = cv2.imread(f"{mask_path}/{seg_id}", cv2.IMREAD_UNCHANGED)
+ mask = mask.astype(np.uint8)
+ mask = Image.fromarray(mask).convert("P")
+ mask.putpalette(np.array(PALETTE, dtype=np.uint8))
+ mask = np.array(mask.convert("RGB"))
+ img_id = str(seg_id.split(".")[0]) + ".tif"
+ img = cv2.imread(f"{img_path}/{img_id}", cv2.IMREAD_COLOR)
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ ax[i, 0].set_axis_off()
+ ax[i, 0].imshow(img)
+ ax[i, 0].set_title("RS IMAGE " + img_id)
+ ax[i, 1].set_axis_off()
+ ax[i, 1].imshow(mask)
+ ax[i, 1].set_title("Mask True " + seg_id)
+ ax[i, 2].set_axis_off()
+ ax[i, 2].imshow(img_seg)
+ ax[i, 2].set_title("Mask Predict " + seg_id)
+ ax[i, 2].legend(
+ handles=patches,
+ bbox_to_anchor=(1.05, 1),
+ loc=2,
+ borderaxespad=0.0,
+ fontsize="large",
+ )
+
+
+def show_seg(seg_path, img_path, start_seg_index):
+ seg_list = os.listdir(seg_path)
+ seg_list = [f for f in seg_list if f.endswith(".png")]
+ fig, ax = plt.subplots(2, 2, figsize=(12, 12))
+ seg_list = seg_list[start_seg_index : start_seg_index + 2]
+ patches = [
+ mpatches.Patch(color=np.array(PALETTE[i]) / 255.0, label=CLASSES[i])
+ for i in range(len(CLASSES))
+ ]
+ for i in range(len(seg_list)):
+ seg_id = seg_list[i]
+ img_seg = cv2.imread(f"{seg_path}/{seg_id}", cv2.IMREAD_UNCHANGED)
+ img_seg = img_seg.astype(np.uint8)
+ img_seg = Image.fromarray(img_seg).convert("P")
+ img_seg.putpalette(np.array(PALETTE, dtype=np.uint8))
+ img_seg = np.array(img_seg.convert("RGB"))
+ img_id = str(seg_id.split(".")[0]) + ".tif"
+ img = cv2.imread(f"{img_path}/{img_id}", cv2.IMREAD_COLOR)
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ ax[i, 0].set_axis_off()
+ ax[i, 0].imshow(img)
+ ax[i, 0].set_title("RS IMAGE " + img_id)
+ ax[i, 1].set_axis_off()
+ ax[i, 1].imshow(img_seg)
+ ax[i, 1].set_title("Seg IMAGE " + seg_id)
+ ax[i, 1].legend(
+ handles=patches,
+ bbox_to_anchor=(1.05, 1),
+ loc=2,
+ borderaxespad=0.0,
+ fontsize="large",
+ )
+
+
+def show_mask(img, mask, img_id):
+ fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 12))
+ patches = [
+ mpatches.Patch(color=np.array(PALETTE[i]) / 255.0, label=CLASSES[i])
+ for i in range(len(CLASSES))
+ ]
+ mask = mask.astype(np.uint8)
+ mask = Image.fromarray(mask).convert("P")
+ mask.putpalette(np.array(PALETTE, dtype=np.uint8))
+ mask = np.array(mask.convert("RGB"))
+ ax1.imshow(img)
+ ax1.set_title("RS IMAGE " + str(img_id) + ".tif")
+ ax2.imshow(mask)
+ ax2.set_title("Mask " + str(img_id) + ".png")
+ ax2.legend(
+ handles=patches,
+ bbox_to_anchor=(1.05, 1),
+ loc=2,
+ borderaxespad=0.0,
+ fontsize="large",
+ )
diff --git a/examples/unetformer/geoseg/losses/__init__.py b/examples/unetformer/geoseg/losses/__init__.py
new file mode 100644
index 000000000..86f4567fd
--- /dev/null
+++ b/examples/unetformer/geoseg/losses/__init__.py
@@ -0,0 +1,13 @@
+from .dice import __all__ as __dice_all__
+from .functional import __all__ as __functional_all__
+from .joint_loss import __all__ as __joint_loss_all__
+from .soft_ce import __all__ as __soft_ce_all__
+from .useful_loss import __all__ as __useful_loss_all__
+
+__all__ = (
+ __dice_all__
+ + __functional_all__
+ + __joint_loss_all__
+ + __soft_ce_all__
+ + __useful_loss_all__
+)
diff --git a/examples/unetformer/geoseg/losses/dice.py b/examples/unetformer/geoseg/losses/dice.py
new file mode 100644
index 000000000..a73e3077d
--- /dev/null
+++ b/examples/unetformer/geoseg/losses/dice.py
@@ -0,0 +1,145 @@
+from typing import List
+
+import numpy as np
+import paddle
+from paddle_utils import add_tensor_methods
+
+from .functional import soft_dice_score
+
+__all__ = ["DiceLoss"]
+BINARY_MODE = "binary"
+MULTICLASS_MODE = "multiclass"
+MULTILABEL_MODE = "multilabel"
+
+add_tensor_methods()
+
+
+def to_tensor(x, dtype=None) -> paddle.Tensor:
+ if isinstance(x, paddle.Tensor):
+ if dtype is not None:
+ x = x.astype(dtype)
+ return x
+ if isinstance(x, np.ndarray) and x.dtype.kind not in {"O", "M", "U", "S"}:
+ x = paddle.to_tensor(data=x)
+ if dtype is not None:
+ x = x.astype(dtype)
+ return x
+ if isinstance(x, (list, tuple)):
+ x = np.ndarray(x)
+ x = paddle.to_tensor(data=x)
+ if dtype is not None:
+ x = x.astype(dtype)
+ return x
+ raise ValueError("Unsupported input type" + str(type(x)))
+
+
+class DiceLoss(paddle.nn.Layer):
+ """
+ Implementation of Dice loss for image segmentation task.
+ It supports binary, multiclass and multilabel cases
+ """
+
+ def __init__(
+ self,
+ mode: str = "multiclass",
+ classes: List[int] = None,
+ log_loss=False,
+ from_logits=True,
+ smooth: float = 0.0,
+ ignore_index=None,
+ eps=1e-07,
+ ):
+ """
+
+ :param mode: Metric mode {'binary', 'multiclass', 'multilabel'}
+ :param classes: Optional list of classes that contribute in loss computation;
+ By default, all channels are included.
+ :param log_loss: If True, loss computed as `-log(jaccard)`; otherwise `1 - jaccard`
+ :param from_logits: If True assumes input is raw logits
+ :param smooth:
+ :param ignore_index: Label that indicates ignored pixels (does not contribute to loss)
+ :param eps: Small epsilon for numerical stability
+ """
+ assert mode in {BINARY_MODE, MULTILABEL_MODE, MULTICLASS_MODE}
+ super(DiceLoss, self).__init__()
+ self.mode = mode
+ if classes is not None:
+ assert (
+ mode != BINARY_MODE
+ ), "Masking classes is not supported with mode=binary"
+ classes = to_tensor(classes, dtype="int64")
+ self.classes = classes
+ self.from_logits = from_logits
+ self.smooth = smooth
+ self.eps = eps
+ self.ignore_index = ignore_index
+ self.log_loss = log_loss
+
+ def forward(self, y_pred: paddle.Tensor, y_true: paddle.Tensor) -> paddle.Tensor:
+ """
+
+ :param y_pred: NxCxHxW
+ :param y_true: NxHxW
+ :return: scalar
+ """
+ assert y_true.shape[0] == y_pred.shape[0]
+ if self.from_logits:
+ if self.mode == MULTICLASS_MODE:
+ y_pred = paddle.nn.functional.log_softmax(y_pred, axis=1).exp()
+ else:
+ y_pred = paddle.nn.functional.log_sigmoid(x=y_pred).exp()
+ bs = y_true.shape[0]
+ num_classes = y_pred.shape[1]
+ dims = 0, 2
+ if self.mode == BINARY_MODE:
+ y_true = y_true.view(bs, 1, -1)
+ y_pred = y_pred.view(bs, 1, -1)
+ if self.ignore_index is not None:
+ mask = y_true != self.ignore_index
+ y_pred = y_pred * paddle.cast(mask, dtype="float32")
+ y_true = y_true * paddle.cast(mask, dtype="float32")
+ if self.mode == MULTICLASS_MODE:
+ y_true = y_true.view(bs, -1)
+ y_pred = y_pred.view(bs, num_classes, -1)
+ if self.ignore_index is not None:
+ if self.ignore_index is not None:
+ mask = y_true != self.ignore_index
+ mask = paddle.cast(mask, dtype="float32")
+ y_pred = paddle.cast(
+ y_pred * mask.unsqueeze(axis=1), dtype="float32"
+ )
+ mask_float = paddle.cast(mask, dtype=y_true.dtype)
+ masked_y_true = (y_true * mask_float).astype("int64")
+ y_true = paddle.nn.functional.one_hot(
+ num_classes=num_classes, x=masked_y_true
+ ).astype("int64")
+ mask = paddle.cast(mask, dtype="int64")
+ y_true = y_true.transpose(perm=[0, 2, 1]) * mask.unsqueeze(axis=1)
+ else:
+ y_true = paddle.nn.functional.one_hot(
+ num_classes=num_classes, x=y_true
+ ).astype("int64")
+ y_true = y_true.transpose(perm=[0, 2, 1])
+ if self.mode == MULTILABEL_MODE:
+ y_true = y_true.view(bs, num_classes, -1)
+ y_pred = y_pred.view(bs, num_classes, -1)
+ if self.ignore_index is not None:
+ mask = y_true != self.ignore_index
+ y_pred = y_pred * paddle.cast(mask, dtype="float32")
+ y_true = y_true * paddle.cast(mask, dtype="float32")
+ scores = soft_dice_score(
+ y_pred,
+ y_true.astype(dtype=y_pred.dtype),
+ smooth=self.smooth,
+ eps=self.eps,
+ dims=dims,
+ )
+ if self.log_loss:
+ loss = -paddle.log(x=scores.clip(min=self.eps))
+ else:
+ loss = 1.0 - scores
+ mask = y_true.sum(axis=dims) > 0
+ loss *= mask.astype(loss.dtype)
+ if self.classes is not None:
+ loss = loss[self.classes]
+ return loss.mean()
diff --git a/examples/unetformer/geoseg/losses/functional.py b/examples/unetformer/geoseg/losses/functional.py
new file mode 100644
index 000000000..3e8433b06
--- /dev/null
+++ b/examples/unetformer/geoseg/losses/functional.py
@@ -0,0 +1,279 @@
+import math
+from typing import Optional
+
+import paddle
+from paddle_utils import add_tensor_methods
+
+__all__ = [
+ "focal_loss_with_logits",
+ "softmax_focal_loss_with_logits",
+ "soft_jaccard_score",
+ "soft_dice_score",
+ "wing_loss",
+]
+
+add_tensor_methods()
+
+
+def focal_loss_with_logits(
+ output: paddle.Tensor,
+ target: paddle.Tensor,
+ gamma: float = 2.0,
+ alpha: Optional[float] = 0.25,
+ reduction: str = "mean",
+ normalized: bool = False,
+ reduced_threshold: Optional[float] = None,
+ eps: float = 1e-06,
+ ignore_index=None,
+) -> paddle.Tensor:
+ """Compute binary focal loss between target and output logits.
+
+ See :class:`~pytorch_toolbelt.losses.FocalLoss` for details.
+
+ Args:
+ output: Tensor of arbitrary shape (predictions of the models)
+ target: Tensor of the same shape as input
+ gamma: Focal loss power factor
+ alpha: Weight factor to balance positive and negative samples. Alpha must be in [0...1] range,
+ high values will give more weight to positive class.
+ reduction (string, optional): Specifies the reduction to apply to the output:
+ 'none' | 'mean' | 'sum' | 'batchwise_mean'. 'none': no reduction will be applied,
+ 'mean': the sum of the output will be divided by the number of
+ elements in the output, 'sum': the output will be summed. Note: :attr:`size_average`
+ and :attr:`reduce` are in the process of being deprecated, and in the meantime,
+ specifying either of those two args will override :attr:`reduction`.
+ 'batchwise_mean' computes mean loss per sample in batch. Default: 'mean'
+ normalized (bool): Compute normalized focal loss (https://arxiv.org/pdf/1909.07829.pdf).
+ reduced_threshold (float, optional): Compute reduced focal loss (https://arxiv.org/abs/1903.01347).
+
+ References:
+ https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/loss/losses.py
+ """
+ target = target.astype(dtype=output.dtype)
+ p = paddle.nn.functional.sigmoid(x=output)
+ ce_loss = paddle.nn.functional.binary_cross_entropy_with_logits(
+ logit=output, label=target, reduction="none"
+ )
+ pt = p * target + (1 - p) * (1 - target)
+ if reduced_threshold is None:
+ focal_term = (1.0 - pt).pow(y=gamma)
+ else:
+ focal_term = ((1.0 - pt) / reduced_threshold).pow(y=gamma)
+ focal_term = paddle.masked_fill(
+ x=focal_term, mask=pt < reduced_threshold, value=1
+ )
+ loss = focal_term * ce_loss
+ if alpha is not None:
+ loss *= alpha * target + (1 - alpha) * (1 - target)
+ if ignore_index is not None:
+ ignore_mask = target.equal(y=ignore_index)
+ loss = paddle.masked_fill(x=loss, mask=ignore_mask, value=0)
+ if normalized:
+ focal_term = paddle.masked_fill(x=focal_term, mask=ignore_mask, value=0)
+ if normalized:
+ norm_factor = focal_term.sum(dtype="float32").clamp_min(eps)
+ loss /= norm_factor
+ if reduction == "mean":
+ loss = loss.mean()
+ if reduction == "sum":
+ loss = loss.sum(dtype="float32")
+ if reduction == "batchwise_mean":
+ loss = loss.sum(axis=0, dtype="float32")
+ return loss
+
+
+def softmax_focal_loss_with_logits(
+ output: paddle.Tensor,
+ target: paddle.Tensor,
+ gamma: float = 2.0,
+ reduction="mean",
+ normalized=False,
+ reduced_threshold: Optional[float] = None,
+ eps: float = 1e-06,
+) -> paddle.Tensor:
+ """
+ Softmax version of focal loss between target and output logits.
+ See :class:`~pytorch_toolbelt.losses.FocalLoss` for details.
+
+ Args:
+ output: Tensor of shape [B, C, *] (Similar to nn.CrossEntropyLoss)
+ target: Tensor of shape [B, *] (Similar to nn.CrossEntropyLoss)
+ reduction (string, optional): Specifies the reduction to apply to the output:
+ 'none' | 'mean' | 'sum' | 'batchwise_mean'. 'none': no reduction will be applied,
+ 'mean': the sum of the output will be divided by the number of
+ elements in the output, 'sum': the output will be summed. Note: :attr:`size_average`
+ and :attr:`reduce` are in the process of being deprecated, and in the meantime,
+ specifying either of those two args will override :attr:`reduction`.
+ 'batchwise_mean' computes mean loss per sample in batch. Default: 'mean'
+ normalized (bool): Compute normalized focal loss (https://arxiv.org/pdf/1909.07829.pdf).
+ reduced_threshold (float, optional): Compute reduced focal loss (https://arxiv.org/abs/1903.01347).
+ """
+ log_softmax = paddle.nn.functional.log_softmax(x=output, axis=1)
+ loss = paddle.nn.functional.nll_loss(
+ input=log_softmax, label=target, reduction="none"
+ )
+ pt = paddle.exp(x=-loss)
+ if reduced_threshold is None:
+ focal_term = (1.0 - pt).pow(y=gamma)
+ else:
+ focal_term = ((1.0 - pt) / reduced_threshold).pow(y=gamma)
+ focal_term[pt < reduced_threshold] = 1
+ loss = focal_term * loss
+ if normalized:
+ norm_factor = focal_term.sum().clamp_min(eps)
+ loss = loss / norm_factor
+ if reduction == "mean":
+ loss = loss.mean()
+ if reduction == "sum":
+ loss = loss.sum()
+ if reduction == "batchwise_mean":
+ loss = loss.sum(axis=0)
+ return loss
+
+
+def soft_jaccard_score(
+ output: paddle.Tensor,
+ target: paddle.Tensor,
+ smooth: float = 0.0,
+ eps: float = 1e-07,
+ dims=None,
+) -> paddle.Tensor:
+ """
+
+ :param output:
+ :param target:
+ :param smooth:
+ :param eps:
+ :param dims:
+ :return:
+
+ Shape:
+ - Input: :math:`(N, NC, *)` where :math:`*` means
+ any number of additional dimensions
+ - Target: :math:`(N, NC, *)`, same shape as the input
+ - Output: scalar.
+
+ """
+ assert tuple(output.shape) == tuple(target.shape)
+ if dims is not None:
+ intersection = paddle.sum(x=output * target, axis=dims)
+ cardinality = paddle.sum(x=output + target, axis=dims)
+ else:
+ intersection = paddle.sum(x=output * target)
+ cardinality = paddle.sum(x=output + target)
+ union = cardinality - intersection
+ jaccard_score = (intersection + smooth) / paddle.clip(union + smooth, min=eps)
+ return jaccard_score
+
+
+def soft_dice_score(
+ output: paddle.Tensor,
+ target: paddle.Tensor,
+ smooth: float = 0.0,
+ eps: float = 1e-07,
+ dims=None,
+) -> paddle.Tensor:
+ """
+
+ :param output:
+ :param target:
+ :param smooth:
+ :param eps:
+ :return:
+
+ Shape:
+ - Input: :math:`(N, NC, *)` where :math:`*` means any number
+ of additional dimensions
+ - Target: :math:`(N, NC, *)`, same shape as the input
+ - Output: scalar.
+
+ """
+ assert tuple(output.shape) == tuple(target.shape)
+ if dims is not None:
+ intersection = paddle.sum(x=output * target, axis=dims)
+ cardinality = paddle.sum(x=output + target, axis=dims)
+ else:
+ intersection = paddle.sum(x=output * target)
+ cardinality = paddle.sum(x=output + target)
+ denominator = paddle.clip(cardinality + smooth, min=eps)
+ dice_score = (2.0 * intersection + smooth) / denominator
+ return dice_score
+
+
+def wing_loss(
+ output: paddle.Tensor,
+ target: paddle.Tensor,
+ width=5,
+ curvature=0.5,
+ reduction="mean",
+):
+ """
+ https://arxiv.org/pdf/1711.06753.pdf
+ :param output:
+ :param target:
+ :param width:
+ :param curvature:
+ :param reduction:
+ :return:
+ """
+ diff_abs = (target.astype("float32") - output).abs().astype("float32")
+ small_loss = width * paddle.log(1 + diff_abs / curvature)
+ C = width - width * math.log(1 + width / curvature)
+ mask_small = diff_abs < width
+ loss = diff_abs.clone()
+ loss = paddle.where(mask_small, small_loss, loss)
+ loss = paddle.where(~mask_small, loss - C, loss)
+
+ if reduction == "sum":
+ loss = loss.sum()
+
+ if reduction == "mean":
+ loss = loss.mean()
+
+ return loss
+
+
+def label_smoothed_nll_loss(
+ lprobs: paddle.Tensor,
+ target: paddle.Tensor,
+ epsilon: float,
+ ignore_index=None,
+ reduction="mean",
+ dim=-1,
+) -> paddle.Tensor:
+ """
+
+ Source: https://github.com/pytorch/fairseq/blob/master/fairseq/criterions/label_smoothed_cross_entropy.py
+
+ :param lprobs: Log-probabilities of predictions (e.g after log_softmax)
+ :param target:
+ :param epsilon:
+ :param ignore_index:
+ :param reduction:
+ :return:
+ """
+ if target.dim() == lprobs.dim() - 1:
+ target = target.unsqueeze(axis=dim)
+ if ignore_index is not None:
+ pad_mask = target.equal(y=ignore_index)
+ target = paddle.where(pad_mask, paddle.zeros_like(target), target)
+ nll_loss = -lprobs.take_along_axis(axis=dim, indices=target)
+ smooth_loss = -lprobs.sum(axis=dim, keepdim=True)
+ nll_loss = paddle.where(pad_mask, paddle.zeros_like(nll_loss), nll_loss)
+ smooth_loss = paddle.where(
+ pad_mask, paddle.zeros_like(smooth_loss), smooth_loss
+ )
+ else:
+ nll_loss = -lprobs.take_along_axis(axis=dim, indices=target)
+ smooth_loss = -lprobs.sum(axis=dim, keepdim=True)
+ nll_loss = nll_loss.squeeze(axis=dim)
+ smooth_loss = smooth_loss.squeeze(axis=dim)
+ if reduction == "sum":
+ nll_loss = nll_loss.sum()
+ smooth_loss = smooth_loss.sum()
+ if reduction == "mean":
+ nll_loss = nll_loss.mean()
+ smooth_loss = smooth_loss.mean()
+ eps_i = epsilon / lprobs.shape[dim]
+ loss = (1.0 - epsilon) * nll_loss + eps_i * smooth_loss
+ return loss
diff --git a/examples/unetformer/geoseg/losses/joint_loss.py b/examples/unetformer/geoseg/losses/joint_loss.py
new file mode 100644
index 000000000..169b07d4d
--- /dev/null
+++ b/examples/unetformer/geoseg/losses/joint_loss.py
@@ -0,0 +1,40 @@
+import paddle
+from paddle_utils import add_tensor_methods
+
+__all__ = ["JointLoss", "WeightedLoss"]
+
+add_tensor_methods()
+
+
+class WeightedLoss(paddle.nn.Layer):
+ """Wrapper class around loss function that applies weighted with fixed factor.
+ This class helps to balance multiple losses if they have different scales
+ """
+
+ def __init__(self, loss, weight=1.0):
+ super().__init__()
+ self.loss = loss
+ self.weight = weight
+
+ def forward(self, *input):
+ return self.loss(*input) * self.weight
+
+
+class JointLoss(paddle.nn.Layer):
+ """
+ Wrap two loss functions into one. This class computes a weighted sum of two losses.
+ """
+
+ def __init__(
+ self,
+ first: paddle.nn.Layer,
+ second: paddle.nn.Layer,
+ first_weight=1.0,
+ second_weight=1.0,
+ ):
+ super().__init__()
+ self.first = WeightedLoss(first, first_weight)
+ self.second = WeightedLoss(second, second_weight)
+
+ def forward(self, *input):
+ return self.first(*input) + self.second(*input)
diff --git a/examples/unetformer/geoseg/losses/soft_ce.py b/examples/unetformer/geoseg/losses/soft_ce.py
new file mode 100644
index 000000000..a13642552
--- /dev/null
+++ b/examples/unetformer/geoseg/losses/soft_ce.py
@@ -0,0 +1,43 @@
+from typing import Optional
+
+import paddle
+from paddle_utils import add_tensor_methods
+
+from .functional import label_smoothed_nll_loss
+
+__all__ = ["SoftCrossEntropyLoss"]
+
+add_tensor_methods()
+
+
+class SoftCrossEntropyLoss(paddle.nn.Layer):
+ """
+ Drop-in replacement for nn.CrossEntropyLoss with few additions:
+ - Support of label smoothing
+ """
+
+ __constants__ = ["reduction", "ignore_index", "smooth_factor"]
+
+ def __init__(
+ self,
+ reduction: str = "mean",
+ smooth_factor: float = 0.0,
+ ignore_index: Optional[int] = -100,
+ dim=1,
+ ):
+ super().__init__()
+ self.smooth_factor = smooth_factor
+ self.ignore_index = ignore_index
+ self.reduction = reduction
+ self.dim = dim
+
+ def forward(self, input: paddle.Tensor, target: paddle.Tensor) -> paddle.Tensor:
+ log_prob = paddle.nn.functional.log_softmax(x=input, axis=self.dim)
+ return label_smoothed_nll_loss(
+ log_prob,
+ target,
+ epsilon=self.smooth_factor,
+ ignore_index=self.ignore_index,
+ reduction=self.reduction,
+ dim=self.dim,
+ )
diff --git a/examples/unetformer/geoseg/losses/useful_loss.py b/examples/unetformer/geoseg/losses/useful_loss.py
new file mode 100644
index 000000000..e855aabd3
--- /dev/null
+++ b/examples/unetformer/geoseg/losses/useful_loss.py
@@ -0,0 +1,122 @@
+import paddle
+from paddle_utils import add_tensor_methods
+from paddle_utils import device2int
+
+from .dice import DiceLoss
+from .joint_loss import JointLoss
+from .soft_ce import SoftCrossEntropyLoss
+
+add_tensor_methods()
+__all__ = ["EdgeLoss", "OHEM_CELoss", "UnetFormerLoss"]
+
+
+class EdgeLoss(paddle.nn.Layer):
+ def __init__(self, ignore_index=255, edge_factor=1.0):
+ super(EdgeLoss, self).__init__()
+ self.main_loss = JointLoss(
+ SoftCrossEntropyLoss(smooth_factor=0.05, ignore_index=ignore_index),
+ DiceLoss(smooth=0.05, ignore_index=ignore_index),
+ 1.0,
+ 1.0,
+ )
+ self.edge_factor = edge_factor
+
+ def get_boundary(self, x):
+ out_0 = paddle.to_tensor(
+ data=[-1, -1, -1, -1, 8, -1, -1, -1, -1], dtype="float32"
+ ).reshape(1, 1, 3, 3)
+ out_0.stop_gradient = not False
+ laplacian_kernel_target = out_0.cuda(device_id=device2int(x.place))
+ x = x.unsqueeze(axis=1).astype(dtype="float32")
+ x = paddle.nn.functional.conv2d(x=x, weight=laplacian_kernel_target, padding=1)
+ x = x.clip(min=0)
+ x[x >= 0.1] = 1
+ x[x < 0.1] = 0
+ return x
+
+ def compute_edge_loss(self, logits, targets):
+ bs = tuple(logits.shape)[0]
+ boundary_targets = self.get_boundary(targets)
+ boundary_targets = boundary_targets.view(bs, 1, -1)
+ logits = (
+ paddle.nn.functional.softmax(x=logits, axis=1)
+ .argmax(axis=1)
+ .squeeze(axis=1)
+ )
+ boundary_pre = self.get_boundary(logits)
+ boundary_pre = boundary_pre / (boundary_pre + 0.01)
+ boundary_pre = boundary_pre.view(bs, 1, -1)
+ edge_loss = paddle.nn.functional.binary_cross_entropy_with_logits(
+ logit=boundary_pre, label=boundary_targets
+ )
+ return edge_loss
+
+ def forward(self, logits, targets):
+ loss = (
+ self.main_loss(logits, targets)
+ + self.compute_edge_loss(logits, targets) * self.edge_factor
+ ) / (self.edge_factor + 1)
+ return loss
+
+
+class OHEM_CELoss(paddle.nn.Layer):
+ def __init__(self, thresh=0.7, ignore_index=255):
+ super(OHEM_CELoss, self).__init__()
+ self.thresh = -paddle.log(
+ x=paddle.to_tensor(data=thresh, dtype="float32", stop_gradient=not False)
+ ).cuda()
+ self.ignore_index = ignore_index
+ self.criteria = paddle.nn.CrossEntropyLoss(
+ ignore_index=ignore_index, reduction="none"
+ )
+
+ def forward(self, logits, labels):
+ if logits.shape[2:] != labels.shape[1:]:
+ logits = paddle.nn.interpolate(
+ logits, size=labels.shape[1:], mode="bilinear", align_corners=True
+ )
+ if logits.shape[0] != labels.shape[0]:
+ raise ValueError("Batch size mismatch between logits and labels")
+ logits = logits.transpose([0, 2, 3, 1])
+ logits = logits.reshape([-1, logits.shape[3]])
+ labels = labels.reshape([-1])
+ valid_mask = labels != self.ignore_index
+ n_valid = paddle.sum(valid_mask).item()
+ n_min = max(1, n_valid // 16)
+ loss = self.criteria(logits, labels)
+ loss_hard = loss[loss > self.thresh]
+ if loss_hard.size < n_min:
+ loss_hard, _ = loss.topk(k=n_min)
+ return paddle.mean(x=loss_hard)
+
+
+class UnetFormerLoss(paddle.nn.Layer):
+ def __init__(self, ignore_index=255):
+ super().__init__()
+ self.main_loss = JointLoss(
+ SoftCrossEntropyLoss(smooth_factor=0.05, ignore_index=ignore_index),
+ DiceLoss(smooth=0.05, ignore_index=ignore_index),
+ 1.0,
+ 1.0,
+ )
+ self.aux_loss = SoftCrossEntropyLoss(
+ smooth_factor=0.05, ignore_index=ignore_index
+ )
+
+ def forward(self, logits, labels):
+ if self.training and len(logits) == 2:
+ logit_main, logit_aux = logits
+ loss = self.main_loss(logit_main, labels) + 0.4 * self.aux_loss(
+ logit_aux, labels
+ )
+ else:
+ loss = self.main_loss(logits, labels)
+ return loss
+
+
+if __name__ == "__main__":
+ targets = paddle.randint(low=0, high=2, shape=(2, 16, 16))
+ logits = paddle.randn(shape=(2, 2, 16, 16))
+ model = EdgeLoss()
+ loss = model.compute_edge_loss(logits, targets)
+ print(loss)
diff --git a/examples/unetformer/geoseg/models/UNetFormer.py b/examples/unetformer/geoseg/models/UNetFormer.py
new file mode 100644
index 000000000..1d5746bae
--- /dev/null
+++ b/examples/unetformer/geoseg/models/UNetFormer.py
@@ -0,0 +1,616 @@
+import einops
+import paddle
+from paddle_utils import add_tensor_methods
+from paddle_utils import dim2perm
+
+add_tensor_methods()
+
+
+class DropPath(paddle.nn.Layer):
+ """DropPath class"""
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def drop_path(self, inputs):
+ """drop path op
+ Args:
+ input: tensor with arbitrary shape
+ drop_prob: float number of drop path probability, default: 0.0
+ training: bool, if current mode is training, default: False
+ Returns:
+ output: output tensor after drop path
+ """
+ # if prob is 0 or eval mode, return original input
+ if self.drop_prob == 0.0 or not self.training:
+ return inputs
+ keep_prob = 1 - self.drop_prob
+ keep_prob = paddle.to_tensor(keep_prob, dtype="float32")
+ shape = (inputs.shape[0],) + (1,) * (inputs.ndim - 1) # shape=(N, 1, 1, 1)
+ random_tensor = keep_prob + paddle.rand(shape, dtype=inputs.dtype)
+ random_tensor = random_tensor.floor() # mask
+ output = (
+ inputs.divide(keep_prob) * random_tensor
+ ) # divide is to keep same output expectation
+ return output
+
+ def forward(self, inputs):
+ return self.drop_path(inputs)
+
+
+class ConvBNReLU(paddle.nn.Sequential):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ dilation=1,
+ stride=1,
+ norm_layer=paddle.nn.BatchNorm2D,
+ bias=False,
+ ):
+ super(ConvBNReLU, self).__init__(
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ bias_attr=bias,
+ dilation=dilation,
+ stride=stride,
+ padding=(stride - 1 + dilation * (kernel_size - 1)) // 2,
+ ),
+ norm_layer(out_channels),
+ paddle.nn.ReLU6(),
+ )
+
+
+class ConvBN(paddle.nn.Sequential):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ dilation=1,
+ stride=1,
+ norm_layer=paddle.nn.BatchNorm2D,
+ bias=False,
+ ):
+ super(ConvBN, self).__init__(
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ bias_attr=bias,
+ dilation=dilation,
+ stride=stride,
+ padding=(stride - 1 + dilation * (kernel_size - 1)) // 2,
+ ),
+ norm_layer(out_channels),
+ )
+
+
+class Conv(paddle.nn.Sequential):
+ def __init__(
+ self, in_channels, out_channels, kernel_size=3, dilation=1, stride=1, bias=False
+ ):
+ super(Conv, self).__init__(
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ bias_attr=bias,
+ dilation=dilation,
+ stride=stride,
+ padding=(stride - 1 + dilation * (kernel_size - 1)) // 2,
+ )
+ )
+
+
+class SeparableConvBNReLU(paddle.nn.Sequential):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ dilation=1,
+ norm_layer=paddle.nn.BatchNorm2D,
+ ):
+ super(SeparableConvBNReLU, self).__init__(
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=(stride - 1 + dilation * (kernel_size - 1)) // 2,
+ groups=in_channels,
+ bias_attr=False,
+ ),
+ norm_layer(out_channels),
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ bias_attr=False,
+ ),
+ paddle.nn.ReLU6(),
+ )
+
+
+class SeparableConvBN(paddle.nn.Sequential):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ dilation=1,
+ norm_layer=paddle.nn.BatchNorm2D,
+ ):
+ super(SeparableConvBN, self).__init__(
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=(stride - 1 + dilation * (kernel_size - 1)) // 2,
+ groups=in_channels,
+ bias_attr=False,
+ ),
+ norm_layer(out_channels),
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ bias_attr=False,
+ ),
+ )
+
+
+class SeparableConv(paddle.nn.Sequential):
+ def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, dilation=1):
+ super(SeparableConv, self).__init__(
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=(stride - 1 + dilation * (kernel_size - 1)) // 2,
+ groups=in_channels,
+ bias_attr=False,
+ ),
+ paddle.nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ bias_attr=False,
+ ),
+ )
+
+
+class Mlp(paddle.nn.Layer):
+ def __init__(
+ self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=paddle.nn.ReLU6,
+ drop=0.0,
+ ):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = paddle.nn.Conv2D(
+ in_channels=in_features,
+ out_channels=hidden_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias_attr=True,
+ )
+ self.act = act_layer()
+ self.fc2 = paddle.nn.Conv2D(
+ in_channels=hidden_features,
+ out_channels=out_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias_attr=True,
+ )
+ self.drop = paddle.nn.Dropout(p=drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class GlobalLocalAttention(paddle.nn.Layer):
+ def __init__(
+ self,
+ dim=256,
+ num_heads=16,
+ qkv_bias=False,
+ window_size=8,
+ relative_pos_embedding=True,
+ ):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // self.num_heads
+ self.scale = head_dim**-0.5
+ self.ws = window_size
+ self.qkv = Conv(dim, 3 * dim, kernel_size=1, bias=qkv_bias)
+ self.local1 = ConvBN(dim, dim, kernel_size=3)
+ self.local2 = ConvBN(dim, dim, kernel_size=1)
+ self.proj = SeparableConvBN(dim, dim, kernel_size=window_size)
+ self.attn_x = paddle.nn.AvgPool2D(
+ kernel_size=(window_size, 1),
+ stride=1,
+ padding=(window_size // 2 - 1, 0),
+ exclusive=False,
+ )
+ self.attn_y = paddle.nn.AvgPool2D(
+ kernel_size=(1, window_size),
+ stride=1,
+ padding=(0, window_size // 2 - 1),
+ exclusive=False,
+ )
+ self.relative_pos_embedding = relative_pos_embedding
+ if self.relative_pos_embedding:
+ self.relative_position_bias_table = (
+ paddle.base.framework.EagerParamBase.from_tensor(
+ tensor=paddle.zeros(
+ shape=[(2 * window_size - 1) * (2 * window_size - 1), num_heads]
+ )
+ )
+ )
+ coords_h = paddle.arange(end=self.ws)
+ coords_w = paddle.arange(end=self.ws)
+ coords = paddle.stack(x=paddle.meshgrid([coords_h, coords_w]))
+ coords_flatten = paddle.flatten(x=coords, start_axis=1)
+ relative_coords = (
+ coords_flatten[:, :, (None)] - coords_flatten[:, (None), :]
+ )
+ relative_coords = relative_coords.transpose(perm=[1, 2, 0]).contiguous()
+ relative_coords[:, :, (0)] += self.ws - 1
+ relative_coords[:, :, (1)] += self.ws - 1
+ relative_coords[:, :, (0)] *= 2 * self.ws - 1
+ relative_position_index = relative_coords.sum(axis=-1)
+ self.register_buffer(
+ name="relative_position_index", tensor=relative_position_index
+ )
+ init_TruncatedNormal = paddle.nn.initializer.TruncatedNormal(std=0.02)
+ init_TruncatedNormal(self.relative_position_bias_table)
+
+ def pad(self, x, ps):
+ _, _, H, W = tuple(x.shape)
+ if W % ps != 0:
+ x = paddle.nn.functional.pad(x=x, pad=(0, ps - W % ps), mode="reflect")
+ if H % ps != 0:
+ x = paddle.nn.functional.pad(
+ x=x,
+ pad=(0, 0, 0, ps - H % ps),
+ mode="reflect",
+ pad_from_left_axis=False,
+ )
+ return x
+
+ def pad_out(self, x):
+ x = paddle.nn.functional.pad(x=x, pad=(0, 1, 0, 1), mode="reflect")
+ return x
+
+ def forward(self, x):
+ B, C, H, W = tuple(x.shape)
+ local = self.local2(x) + self.local1(x)
+ x = self.pad(x, self.ws)
+ B, C, Hp, Wp = tuple(x.shape)
+ qkv = self.qkv(x)
+ q, k, v = einops.rearrange(
+ qkv,
+ "b (qkv h d) (hh ws1) (ww ws2) -> qkv (b hh ww) h (ws1 ws2) d",
+ h=self.num_heads,
+ d=C // self.num_heads,
+ hh=Hp // self.ws,
+ ww=Wp // self.ws,
+ qkv=3,
+ ws1=self.ws,
+ ws2=self.ws,
+ )
+ dots = q @ k.transpose(perm=dim2perm(k.ndim, -2, -1)) * self.scale
+ if self.relative_pos_embedding:
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)
+ ].view(self.ws * self.ws, self.ws * self.ws, -1)
+ relative_position_bias = relative_position_bias.transpose(
+ perm=[2, 0, 1]
+ ).contiguous()
+ dots += relative_position_bias.unsqueeze(axis=0)
+ attn = paddle.nn.functional.softmax(dots, axis=-1)
+ attn = attn @ v
+ attn = einops.rearrange(
+ attn,
+ "(b hh ww) h (ws1 ws2) d -> b (h d) (hh ws1) (ww ws2)",
+ h=self.num_heads,
+ d=C // self.num_heads,
+ hh=Hp // self.ws,
+ ww=Wp // self.ws,
+ ws1=self.ws,
+ ws2=self.ws,
+ )
+ attn = attn[:, :, :H, :W]
+ out = self.attn_x(
+ paddle.nn.functional.pad(x=attn, pad=(0, 0, 0, 1), mode="reflect")
+ ) + self.attn_y(
+ paddle.nn.functional.pad(x=attn, pad=(0, 1, 0, 0), mode="reflect")
+ )
+ out = out + local
+ out = self.pad_out(out)
+ out = self.proj(out)
+ out = out[:, :, :H, :W]
+ return out
+
+
+class Block(paddle.nn.Layer):
+ def __init__(
+ self,
+ dim=256,
+ num_heads=16,
+ mlp_ratio=4.0,
+ qkv_bias=False,
+ drop=0.0,
+ attn_drop=0.0,
+ drop_path=0.0,
+ act_layer=paddle.nn.ReLU6,
+ norm_layer=paddle.nn.BatchNorm2D,
+ window_size=8,
+ ):
+ super().__init__()
+ self.norm1 = norm_layer(dim)
+ self.attn = GlobalLocalAttention(
+ dim, num_heads=num_heads, qkv_bias=qkv_bias, window_size=window_size
+ )
+ self.drop_path = (
+ DropPath(drop_path) if drop_path > 0.0 else paddle.nn.Identity()
+ )
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ out_features=dim,
+ act_layer=act_layer,
+ drop=drop,
+ )
+ self.norm2 = norm_layer(dim)
+
+ def forward(self, x):
+ x = x + self.drop_path(self.attn(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class WF(paddle.nn.Layer):
+ def __init__(self, in_channels=128, decode_channels=128, eps=1e-08):
+ super(WF, self).__init__()
+ self.pre_conv = Conv(in_channels, decode_channels, kernel_size=1)
+ self.weights = paddle.base.framework.EagerParamBase.from_tensor(
+ tensor=paddle.ones(shape=[2], dtype="float32"), trainable=True
+ )
+ self.eps = eps
+ self.post_conv = ConvBNReLU(decode_channels, decode_channels, kernel_size=3)
+
+ def forward(self, x, res):
+ x = paddle.nn.functional.interpolate(
+ x=x, scale_factor=2, mode="bilinear", align_corners=False
+ )
+ weights = paddle.nn.ReLU()(self.weights)
+ fuse_weights = weights / (paddle.sum(x=weights, axis=0) + self.eps)
+ x = fuse_weights[0] * self.pre_conv(res) + fuse_weights[1] * x
+ x = self.post_conv(x)
+ return x
+
+
+class FeatureRefinementHead(paddle.nn.Layer):
+ def __init__(self, in_channels=64, decode_channels=64):
+ super().__init__()
+ self.pre_conv = Conv(in_channels, decode_channels, kernel_size=1)
+ self.weights = paddle.base.framework.EagerParamBase.from_tensor(
+ tensor=paddle.ones(shape=[2], dtype="float32"), trainable=True
+ )
+ self.eps = 1e-08
+ self.post_conv = ConvBNReLU(decode_channels, decode_channels, kernel_size=3)
+ self.pa = paddle.nn.Sequential(
+ paddle.nn.Conv2D(
+ in_channels=decode_channels,
+ out_channels=decode_channels,
+ kernel_size=3,
+ padding=1,
+ groups=decode_channels,
+ ),
+ paddle.nn.Sigmoid(),
+ )
+ self.ca = paddle.nn.Sequential(
+ paddle.nn.AdaptiveAvgPool2D(output_size=1),
+ Conv(decode_channels, decode_channels // 16, kernel_size=1),
+ paddle.nn.ReLU6(),
+ Conv(decode_channels // 16, decode_channels, kernel_size=1),
+ paddle.nn.Sigmoid(),
+ )
+ self.shortcut = ConvBN(decode_channels, decode_channels, kernel_size=1)
+ self.proj = SeparableConvBN(decode_channels, decode_channels, kernel_size=3)
+ self.act = paddle.nn.ReLU6()
+
+ def forward(self, x, res):
+ x = paddle.nn.functional.interpolate(
+ x=x, scale_factor=2, mode="bilinear", align_corners=False
+ )
+ weights = paddle.nn.ReLU()(self.weights)
+ fuse_weights = weights / (paddle.sum(x=weights, axis=0) + self.eps)
+ x = fuse_weights[0] * self.pre_conv(res) + fuse_weights[1] * x
+ x = self.post_conv(x)
+ shortcut = self.shortcut(x)
+ pa = self.pa(x) * x
+ ca = self.ca(x) * x
+ x = pa + ca
+ x = self.proj(x) + shortcut
+ x = self.act(x)
+ return x
+
+
+class AuxHead(paddle.nn.Layer):
+ def __init__(self, in_channels=64, num_classes=8):
+ super().__init__()
+ self.conv = ConvBNReLU(in_channels, in_channels)
+ self.drop = paddle.nn.Dropout(p=0.1)
+ self.conv_out = Conv(in_channels, num_classes, kernel_size=1)
+
+ def forward(self, x, h, w):
+ feat = self.conv(x)
+ feat = self.drop(feat)
+ feat = self.conv_out(feat)
+ feat = paddle.nn.functional.interpolate(
+ x=feat, size=(h, w), mode="bilinear", align_corners=False
+ )
+ return feat
+
+
+class Decoder(paddle.nn.Layer):
+ def __init__(
+ self,
+ encoder_channels=(64, 128, 256, 512),
+ decode_channels=64,
+ dropout=0.1,
+ window_size=8,
+ num_classes=6,
+ ):
+ super(Decoder, self).__init__()
+ self.pre_conv = ConvBN(encoder_channels[-1], decode_channels, kernel_size=1)
+ self.b4 = Block(dim=decode_channels, num_heads=8, window_size=window_size)
+ self.b3 = Block(dim=decode_channels, num_heads=8, window_size=window_size)
+ self.p3 = WF(encoder_channels[-2], decode_channels)
+ self.b2 = Block(dim=decode_channels, num_heads=8, window_size=window_size)
+ self.p2 = WF(encoder_channels[-3], decode_channels)
+ if self.training:
+ self.up4 = paddle.nn.UpsamplingBilinear2D(scale_factor=4)
+ self.up3 = paddle.nn.UpsamplingBilinear2D(scale_factor=2)
+ self.aux_head = AuxHead(decode_channels, num_classes)
+ self.p1 = FeatureRefinementHead(encoder_channels[-4], decode_channels)
+ self.segmentation_head = paddle.nn.Sequential(
+ ConvBNReLU(decode_channels, decode_channels),
+ paddle.nn.Dropout2D(p=dropout),
+ Conv(decode_channels, num_classes, kernel_size=1),
+ )
+ self.init_weight()
+
+ def forward(self, res1, res2, res3, res4, h, w):
+ if self.training:
+ x = self.b4(self.pre_conv(res4))
+ h4 = self.up4(x)
+ x = self.p3(x, res3)
+ x = self.b3(x)
+ h3 = self.up3(x)
+ x = self.p2(x, res2)
+ x = self.b2(x)
+ h2 = x
+ x = self.p1(x, res1)
+ x = self.segmentation_head(x)
+ x = paddle.nn.functional.interpolate(
+ x=x, size=(h, w), mode="bilinear", align_corners=False
+ )
+ ah = h4 + h3 + h2
+ ah = self.aux_head(ah, h, w)
+ return x, ah
+ else:
+ x = self.b4(self.pre_conv(res4))
+ x = self.p3(x, res3)
+ x = self.b3(x)
+ x = self.p2(x, res2)
+ x = self.b2(x)
+ x = self.p1(x, res1)
+ x = self.segmentation_head(x)
+ x = paddle.nn.functional.interpolate(
+ x=x, size=(h, w), mode="bilinear", align_corners=False
+ )
+ return x
+
+ def init_weight(self):
+ for m in self.children():
+ if isinstance(m, paddle.nn.Conv2D):
+ init_KaimingNormal = paddle.nn.initializer.KaimingNormal(
+ negative_slope=1, nonlinearity="leaky_relu"
+ )
+ init_KaimingNormal(m.weight)
+ if m.bias is not None:
+ init_Constant = paddle.nn.initializer.Constant(value=0)
+ init_Constant(m.bias)
+
+
+class create_model(paddle.nn.Layer):
+ def __init__(self, pretrained=True):
+ super(create_model, self).__init__()
+ resnet = paddle.vision.models.resnet18(pretrained=pretrained)
+ self.stage0 = paddle.nn.Sequential(
+ resnet.conv1, resnet.bn1, paddle.nn.ReLU(), resnet.maxpool
+ )
+ self.stage1 = resnet.layer1
+ self.stage2 = resnet.layer2
+ self.stage3 = resnet.layer3
+ self.stage4 = resnet.layer4
+ self.outputs = []
+ self.feature_info = type(
+ "FeatureInfo",
+ (object,),
+ {
+ "channels": lambda self: [64, 128, 256, 512],
+ "reduction": lambda self: [4, 8, 16, 32],
+ },
+ )()
+
+ def forward(self, x):
+ self.outputs = []
+ x = self.stage0(x)
+ x = self.stage1(x)
+ self.outputs.append(x)
+ x = self.stage2(x)
+ self.outputs.append(x)
+ x = self.stage3(x)
+ self.outputs.append(x)
+ x = self.stage4(x)
+ self.outputs.append(x)
+ return self.outputs
+
+
+class UNetFormer(paddle.nn.Layer):
+ def __init__(
+ self,
+ decode_channels=64,
+ dropout=0.1,
+ backbone_name="swsl_resnet18",
+ pretrained=True,
+ window_size=8,
+ num_classes=6,
+ ):
+ super().__init__()
+ self.backbone = create_model(
+ pretrained=pretrained,
+ )
+ encoder_channels = self.backbone.feature_info.channels()
+ self.decoder = Decoder(
+ encoder_channels, decode_channels, dropout, window_size, num_classes
+ )
+
+ def forward(self, x):
+ h, w = tuple(x.shape)[-2:]
+ res1, res2, res3, res4 = self.backbone(x)
+ if self.training:
+ x, ah = self.decoder(res1, res2, res3, res4, h, w)
+ return x, ah
+ else:
+ x = self.decoder(res1, res2, res3, res4, h, w)
+ return x
diff --git a/examples/unetformer/geoseg/models/__init__.py b/examples/unetformer/geoseg/models/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/examples/unetformer/paddle_utils.py b/examples/unetformer/paddle_utils.py
new file mode 100644
index 000000000..d8b9448f8
--- /dev/null
+++ b/examples/unetformer/paddle_utils.py
@@ -0,0 +1,84 @@
+import paddle
+
+
+def _Tensor_view(self, *args, **kwargs):
+ if args:
+ if len(args) == 1 and isinstance(args[0], (tuple, list)):
+ return paddle.reshape(self, args[0])
+ else:
+ return paddle.reshape(self, list(args))
+ elif kwargs:
+ return paddle.reshape(self, shape=list(kwargs.values())[0])
+
+
+setattr(paddle.Tensor, "view", _Tensor_view)
+
+
+def _Tensor_reshape(self, *args, **kwargs):
+ if args:
+ if len(args) == 1 and isinstance(args[0], (tuple, list)):
+ return paddle.reshape(self, args[0])
+ else:
+ return paddle.reshape(self, list(args))
+ elif kwargs:
+ assert "shape" in kwargs
+ return paddle.reshape(self, shape=kwargs["shape"])
+
+
+setattr(paddle.Tensor, "reshape", _Tensor_reshape)
+
+
+def device2int(device):
+ if isinstance(device, paddle.fluid.libpaddle.Place):
+ if device.is_gpu_place():
+ return device.gpu_device_id()
+ else:
+ return 0
+ elif isinstance(device, str):
+ device = device.replace("cuda", "gpu")
+ device = device.replace("gpu:", "")
+ try:
+ return int(device)
+ except ValueError:
+ return 0
+ else:
+ return 0
+
+
+def dim2perm(ndim, dim0, dim1):
+ perm = list(range(ndim))
+ perm[dim0], perm[dim1] = perm[dim1], perm[dim0]
+ return perm
+
+
+class PaddleFlag:
+ cudnn_enabled = True
+ cudnn_benchmark = False
+ matmul_allow_tf32 = False
+ cudnn_allow_tf32 = True
+ cudnn_deterministic = False
+
+
+def add_tensor_methods():
+ def _Tensor_view(self, *args, **kwargs):
+ if args:
+ if len(args) == 1 and isinstance(args[0], (tuple, list)):
+ return paddle.reshape(self, args[0])
+ else:
+ return paddle.reshape(self, list(args))
+ elif kwargs:
+ return paddle.reshape(self, shape=list(kwargs.values())[0])
+
+ setattr(paddle.Tensor, "view", _Tensor_view)
+
+ def _Tensor_reshape(self, *args, **kwargs):
+ if args:
+ if len(args) == 1 and isinstance(args[0], (tuple, list)):
+ return paddle.reshape(self, args[0])
+ else:
+ return paddle.reshape(self, list(args))
+ elif kwargs:
+ assert "shape" in kwargs
+ return paddle.reshape(self, shape=kwargs["shape"])
+
+ setattr(paddle.Tensor, "reshape", _Tensor_reshape)
diff --git a/examples/unetformer/tools/__init__.py b/examples/unetformer/tools/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/examples/unetformer/tools/cfg.py b/examples/unetformer/tools/cfg.py
new file mode 100644
index 000000000..20e4c1fac
--- /dev/null
+++ b/examples/unetformer/tools/cfg.py
@@ -0,0 +1,76 @@
+import pydoc
+import sys
+from importlib import import_module
+from pathlib import Path
+from typing import Union
+
+from addict import Dict
+
+
+class ConfigDict(Dict):
+ def __missing__(self, name):
+ raise KeyError(name)
+
+ def __getattr__(self, name):
+ try:
+ value = super().__getattr__(name)
+ except KeyError:
+ ex = AttributeError(
+ f"'{self.__class__.__name__}' object has no attribute '{name}'"
+ )
+ else:
+ return value
+ raise ex
+
+
+def py2dict(file_path: Union[str, Path]) -> dict:
+ """Convert python file to dictionary.
+ The main use - config parser.
+ file:
+ ```
+ a = 1
+ b = 3
+ c = range(10)
+ ```
+ will be converted to
+ {'a':1,
+ 'b':3,
+ 'c': range(10)
+ }
+ Args:
+ file_path: path to the original python file.
+ Returns: {key: value}, where key - all variables defined in the file and value is their value.
+ """
+ file_path = Path(file_path).absolute()
+ if file_path.suffix != ".py":
+ raise TypeError(
+ f"Only Py file can be parsed, but got {file_path.name} instead."
+ )
+ if not file_path.exists():
+ raise FileExistsError(f"There is no file at the path {file_path}")
+ module_name = file_path.stem
+ if "." in module_name:
+ raise ValueError("Dots are not allowed in config file path.")
+ config_dir = str(file_path.parent)
+ sys.path.insert(0, config_dir)
+ mod = import_module(module_name)
+ sys.path.pop(0)
+ cfg_dict = {
+ name: value for name, value in mod.__dict__.items() if not name.startswith("__")
+ }
+ return cfg_dict
+
+
+def py2cfg(file_path: Union[str, Path]) -> ConfigDict:
+ cfg_dict = py2dict(file_path)
+ return ConfigDict(cfg_dict)
+
+
+def object_from_dict(d, parent=None, **default_kwargs):
+ kwargs = d.copy()
+ object_type = kwargs.pop("type")
+ for name, value in default_kwargs.items():
+ kwargs.setdefault(name, value)
+ if parent is not None:
+ return getattr(parent, object_type)(**kwargs)
+ return pydoc.locate(object_type)(**kwargs)
diff --git a/examples/unetformer/tools/metric.py b/examples/unetformer/tools/metric.py
new file mode 100644
index 000000000..31c83097c
--- /dev/null
+++ b/examples/unetformer/tools/metric.py
@@ -0,0 +1,95 @@
+import numpy as np
+
+
+class Evaluator(object):
+ def __init__(self, num_class):
+ self.num_class = num_class
+ self.confusion_matrix = np.zeros((self.num_class,) * 2)
+ self.eps = 1e-08
+
+ def get_tp_fp_tn_fn(self):
+ tp = np.diag(self.confusion_matrix)
+ fp = self.confusion_matrix.sum(axis=0) - np.diag(self.confusion_matrix)
+ fn = self.confusion_matrix.sum(axis=1) - np.diag(self.confusion_matrix)
+ tn = np.diag(self.confusion_matrix).sum() - np.diag(self.confusion_matrix)
+ return tp, fp, tn, fn
+
+ def Precision(self):
+ tp, fp, tn, fn = self.get_tp_fp_tn_fn()
+ precision = tp / (tp + fp)
+ return precision
+
+ def Recall(self):
+ tp, fp, tn, fn = self.get_tp_fp_tn_fn()
+ recall = tp / (tp + fn)
+ return recall
+
+ def F1(self):
+ tp, fp, tn, fn = self.get_tp_fp_tn_fn()
+ Precision = tp / (tp + fp)
+ Recall = tp / (tp + fn)
+ F1 = 2.0 * Precision * Recall / (Precision + Recall)
+ return F1
+
+ def OA(self):
+ OA = np.diag(self.confusion_matrix).sum() / (
+ self.confusion_matrix.sum() + self.eps
+ )
+ return OA
+
+ def Intersection_over_Union(self):
+ tp, fp, tn, fn = self.get_tp_fp_tn_fn()
+ IoU = tp / (tp + fn + fp)
+ return IoU
+
+ def Dice(self):
+ tp, fp, tn, fn = self.get_tp_fp_tn_fn()
+ Dice = 2 * tp / (tp + fp + (tp + fn))
+ return Dice
+
+ def Pixel_Accuracy_Class(self):
+ Acc = np.diag(self.confusion_matrix) / (
+ self.confusion_matrix.sum(axis=0) + self.eps
+ )
+ return Acc
+
+ def Frequency_Weighted_Intersection_over_Union(self):
+ freq = np.sum(self.confusion_matrix, axis=1) / (
+ np.sum(self.confusion_matrix) + self.eps
+ )
+ iou = self.Intersection_over_Union()
+ FWIoU = (freq[freq > 0] * iou[freq > 0]).sum()
+ return FWIoU
+
+ def _generate_matrix(self, gt_image, pre_image):
+ mask = (gt_image >= 0) & (gt_image < self.num_class)
+ label = self.num_class * gt_image[mask].astype("int") + pre_image[mask]
+ count = np.bincount(label, minlength=self.num_class**2)
+ confusion_matrix = count.reshape(self.num_class, self.num_class)
+ return confusion_matrix
+
+ def add_batch(self, gt_image, pre_image):
+ assert (
+ gt_image.shape == pre_image.shape
+ ), "pre_image shape {}, gt_image shape {}".format(
+ pre_image.shape, gt_image.shape
+ )
+ self.confusion_matrix += self._generate_matrix(gt_image, pre_image)
+
+ def reset(self):
+ self.confusion_matrix = np.zeros((self.num_class,) * 2)
+
+
+if __name__ == "__main__":
+ gt = np.array([[0, 2, 1], [1, 2, 1], [1, 0, 1]])
+ pre = np.array([[0, 1, 1], [2, 0, 1], [1, 1, 1]])
+ eval = Evaluator(num_class=3)
+ eval.add_batch(gt, pre)
+ print(eval.confusion_matrix)
+ print(eval.get_tp_fp_tn_fn())
+ print(eval.Precision())
+ print(eval.Recall())
+ print(eval.Intersection_over_Union())
+ print(eval.OA())
+ print(eval.F1())
+ print(eval.Frequency_Weighted_Intersection_over_Union())
diff --git a/examples/unetformer/tools/utils.py b/examples/unetformer/tools/utils.py
new file mode 100644
index 000000000..1ddbdcb86
--- /dev/null
+++ b/examples/unetformer/tools/utils.py
@@ -0,0 +1,76 @@
+import collections
+import copy
+import re
+from typing import Dict
+from typing import List
+from typing import Union
+
+import paddle
+
+
+def merge_dicts(*dicts: dict) -> dict:
+ """Recursive dict merge.
+ Instead of updating only top-level keys,
+ ``merge_dicts`` recurses down into dicts nested
+ to an arbitrary depth, updating keys.
+
+ Args:
+ *dicts: several dictionaries to merge
+
+ Returns:
+ dict: deep-merged dictionary
+ """
+ assert len(dicts) > 1
+ dict_ = copy.deepcopy(dicts[0])
+ for merge_dict in dicts[1:]:
+ merge_dict = merge_dict or {}
+ for k in merge_dict:
+ if (
+ k in dict_
+ and isinstance(dict_[k], dict)
+ and isinstance(merge_dict[k], collections.Mapping)
+ ):
+ dict_[k] = merge_dicts(dict_[k], merge_dict[k])
+ else:
+ dict_[k] = merge_dict[k]
+ return dict_
+
+
+def process_model_params(
+ model: paddle.nn.Layer,
+ layerwise_params: Dict[str, dict] = None,
+ no_bias_weight_decay: bool = True,
+ lr_scaling: float = 1.0,
+) -> List[Union[paddle.base.framework.EagerParamBase.from_tensor, dict]]:
+ """Gains model parameters for ``torch.optim.Optimizer``.
+
+ Args:
+ model (torch.nn.Module): Model to process
+ layerwise_params (Dict): Order-sensitive dict where
+ each key is regex pattern and values are layer-wise options
+ for layers matching with a pattern
+ no_bias_weight_decay (bool): If true, removes weight_decay
+ for all ``bias`` parameters in the model
+ lr_scaling (float): layer-wise learning rate scaling,
+ if 1.0, learning rates will not be scaled
+
+ Returns:
+ iterable: parameters for an optimizer
+
+ Example::
+
+ """
+ params = list(model.named_parameters())
+ layerwise_params = layerwise_params or collections.OrderedDict()
+ model_params = []
+ for name, parameters in params:
+ options = {}
+ for pattern, pattern_options in layerwise_params.items():
+ if re.match(pattern, name) is not None:
+ options = merge_dicts(options, pattern_options)
+ if no_bias_weight_decay and name.endswith("bias"):
+ options["weight_decay"] = 0.0
+ if "lr" in options:
+ options["lr"] *= lr_scaling
+ model_params.append({"params": parameters, **options})
+ return model_params
diff --git a/examples/unetformer/tools/vaihingen_patch_split.py b/examples/unetformer/tools/vaihingen_patch_split.py
new file mode 100644
index 000000000..d59599cdf
--- /dev/null
+++ b/examples/unetformer/tools/vaihingen_patch_split.py
@@ -0,0 +1,299 @@
+import argparse
+import glob
+import multiprocessing as mp
+import multiprocessing.pool as mpp
+import os
+import random
+import time
+
+import albumentations as albu
+import cv2
+import numpy as np
+import paddle
+from paddle_utils import PaddleFlag
+from paddle_utils import add_tensor_methods
+from PIL import Image
+
+SEED = 42
+add_tensor_methods()
+
+
+def seed_everything(seed):
+ random.seed(seed)
+ os.environ["PYTHONHASHSEED"] = str(seed)
+ np.random.seed(seed)
+ paddle.seed(seed=seed)
+ paddle.seed(seed=seed)
+ PaddleFlag.cudnn_deterministic = True
+ PaddleFlag.cudnn_benchmark = True
+
+
+ImSurf = np.array([255, 255, 255])
+Building = np.array([255, 0, 0])
+LowVeg = np.array([255, 255, 0])
+Tree = np.array([0, 255, 0])
+Car = np.array([0, 255, 255])
+Clutter = np.array([0, 0, 255])
+Boundary = np.array([0, 0, 0])
+num_classes = 6
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--img-dir", default="data/vaihingen/train_images")
+ parser.add_argument("--mask-dir", default="data/vaihingen/train_masks")
+ parser.add_argument("--output-img-dir", default="data/vaihingen/train/images_1024")
+ parser.add_argument("--output-mask-dir", default="data/vaihingen/train/masks_1024")
+ parser.add_argument("--eroded", action="store_true")
+ parser.add_argument("--gt", action="store_true")
+ parser.add_argument("--mode", type=str, default="train")
+ parser.add_argument("--val-scale", type=float, default=1.0)
+ parser.add_argument("--split-size", type=int, default=1024)
+ parser.add_argument("--stride", type=int, default=512)
+ return parser.parse_args()
+
+
+def get_img_mask_padded(image, mask, patch_size, mode):
+ img, mask = np.array(image), np.array(mask)
+ oh, ow = tuple(img.shape)[0], tuple(img.shape)[1]
+ rh, rw = oh % patch_size, ow % patch_size
+ width_pad = 0 if rw == 0 else patch_size - rw
+ height_pad = 0 if rh == 0 else patch_size - rh
+ h, w = oh + height_pad, ow + width_pad
+ pad_img = albu.PadIfNeeded(
+ min_height=h,
+ min_width=w,
+ position="bottom_right",
+ border_mode=cv2.BORDER_CONSTANT,
+ value=0,
+ )(image=img)
+ pad_mask = albu.PadIfNeeded(
+ min_height=h,
+ min_width=w,
+ position="bottom_right",
+ border_mode=cv2.BORDER_CONSTANT,
+ value=6,
+ )(image=mask)
+ img_pad, mask_pad = pad_img["image"], pad_mask["image"]
+ img_pad = cv2.cvtColor(np.array(img_pad), cv2.COLOR_RGB2BGR)
+ mask_pad = cv2.cvtColor(np.array(mask_pad), cv2.COLOR_RGB2BGR)
+ return img_pad, mask_pad
+
+
+def pv2rgb(mask):
+ h, w = tuple(mask.shape)[0], tuple(mask.shape)[1]
+ mask_rgb = np.zeros(shape=(h, w, 3), dtype=np.uint8)
+ mask_convert = mask[(np.newaxis), :, :]
+ mask_rgb[np.all(mask_convert == 3, axis=0)] = [0, 255, 0]
+ mask_rgb[np.all(mask_convert == 0, axis=0)] = [255, 255, 255]
+ mask_rgb[np.all(mask_convert == 1, axis=0)] = [255, 0, 0]
+ mask_rgb[np.all(mask_convert == 2, axis=0)] = [255, 255, 0]
+ mask_rgb[np.all(mask_convert == 4, axis=0)] = [0, 204, 255]
+ mask_rgb[np.all(mask_convert == 5, axis=0)] = [0, 0, 255]
+ return mask_rgb
+
+
+def car_color_replace(mask):
+ mask = cv2.cvtColor(np.array(mask.copy()), cv2.COLOR_RGB2BGR)
+ mask[np.all(mask == [0, 255, 255], axis=-1)] = [0, 204, 255]
+ return mask
+
+
+def rgb_to_2D_label(_label):
+ _label = _label.transpose(2, 0, 1)
+ label_seg = np.zeros(tuple(_label.shape)[1:], dtype=np.uint8)
+ label_seg[np.all(_label.transpose([1, 2, 0]) == ImSurf, axis=-1)] = 0
+ label_seg[np.all(_label.transpose([1, 2, 0]) == Building, axis=-1)] = 1
+ label_seg[np.all(_label.transpose([1, 2, 0]) == LowVeg, axis=-1)] = 2
+ label_seg[np.all(_label.transpose([1, 2, 0]) == Tree, axis=-1)] = 3
+ label_seg[np.all(_label.transpose([1, 2, 0]) == Car, axis=-1)] = 4
+ label_seg[np.all(_label.transpose([1, 2, 0]) == Clutter, axis=-1)] = 5
+ label_seg[np.all(_label.transpose([1, 2, 0]) == Boundary, axis=-1)] = 6
+ return label_seg
+
+
+def image_augment(image, mask, patch_size, mode="train", val_scale=1.0):
+ image_list = []
+ mask_list = []
+ image_width, image_height = image.size[1], image.size[0]
+ mask_width, mask_height = mask.size[1], mask.size[0]
+ assert image_height == mask_height and image_width == mask_width
+ if mode == "train":
+ h_vlip = paddle.vision.transforms.RandomHorizontalFlip(prob=1.0)
+ v_vlip = paddle.vision.transforms.RandomVerticalFlip(prob=1.0)
+ image_h_vlip, mask_h_vlip = h_vlip(image.copy()), h_vlip(mask.copy())
+ image_v_vlip, mask_v_vlip = v_vlip(image.copy()), v_vlip(mask.copy())
+ image_list_train = [image, image_h_vlip, image_v_vlip]
+ mask_list_train = [mask, mask_h_vlip, mask_v_vlip]
+ for i in range(len(image_list_train)):
+ image_tmp, mask_tmp = get_img_mask_padded(
+ image_list_train[i], mask_list_train[i], patch_size, mode
+ )
+ mask_tmp = rgb_to_2D_label(mask_tmp.copy())
+ image_list.append(image_tmp)
+ mask_list.append(mask_tmp)
+ else:
+ rescale = paddle.vision.transforms.Resize(
+ size=(int(image_width * val_scale), int(image_height * val_scale))
+ )
+ image, mask = rescale(image.copy()), rescale(mask.copy())
+ image, mask = get_img_mask_padded(image.copy(), mask.copy(), patch_size, mode)
+ mask = rgb_to_2D_label(mask.copy())
+ image_list.append(image)
+ mask_list.append(mask)
+ return image_list, mask_list
+
+
+def randomsizedcrop(image, mask):
+ h, w = tuple(image.shape)[0], tuple(image.shape)[1]
+ crop = albu.RandomSizedCrop(
+ min_max_height=(int(3 * h // 8), int(h // 2)), width=h, height=w
+ )(image=image.copy(), mask=mask.copy())
+ img_crop, mask_crop = crop["image"], crop["mask"]
+ return img_crop, mask_crop
+
+
+def car_aug(image, mask):
+ assert tuple(image.shape)[:2] == tuple(mask.shape)
+ v_flip = albu.VerticalFlip(p=1.0)(image=image.copy(), mask=mask.copy())
+ h_flip = albu.HorizontalFlip(p=1.0)(image=image.copy(), mask=mask.copy())
+ rotate_90 = albu.RandomRotate90(p=1.0)(image=image.copy(), mask=mask.copy())
+ image_vflip, mask_vflip = v_flip["image"], v_flip["mask"]
+ image_hflip, mask_hflip = h_flip["image"], h_flip["mask"]
+ image_rotate, mask_rotate = rotate_90["image"], rotate_90["mask"]
+ image_list = [image, image_vflip, image_hflip, image_rotate]
+ mask_list = [mask, mask_vflip, mask_hflip, mask_rotate]
+ return image_list, mask_list
+
+
+def vaihingen_format(inp):
+ (
+ img_path,
+ mask_path,
+ imgs_output_dir,
+ masks_output_dir,
+ eroded,
+ gt,
+ mode,
+ val_scale,
+ split_size,
+ stride,
+ ) = inp
+ img_filename = os.path.splitext(os.path.basename(img_path))[0]
+ mask_filename = os.path.splitext(os.path.basename(mask_path))[0]
+ if eroded:
+ mask_path = mask_path[:-4] + "_noBoundary.tif"
+ img = Image.open(img_path).convert("RGB")
+ mask = Image.open(mask_path).convert("RGB")
+ if gt:
+ mask_ = car_color_replace(mask)
+ out_origin_mask_path = os.path.join(
+ masks_output_dir + "/origin/", "{}.tif".format(mask_filename)
+ )
+ cv2.imwrite(out_origin_mask_path, mask_)
+ image_list, mask_list = image_augment(
+ image=img.copy(),
+ mask=mask.copy(),
+ patch_size=split_size,
+ mode=mode,
+ val_scale=val_scale,
+ )
+ assert img_filename == mask_filename and len(image_list) == len(mask_list)
+ for m in range(len(image_list)):
+ k = 0
+ img = image_list[m]
+ mask = mask_list[m]
+ assert (
+ tuple(img.shape)[0] == tuple(mask.shape)[0]
+ and tuple(img.shape)[1] == tuple(mask.shape)[1]
+ )
+ if gt:
+ mask = pv2rgb(mask)
+ for y in range(0, tuple(img.shape)[0], stride):
+ for x in range(0, tuple(img.shape)[1], stride):
+ img_tile = img[y : y + split_size, x : x + split_size]
+ mask_tile = mask[y : y + split_size, x : x + split_size]
+ if (
+ tuple(img_tile.shape)[0] == split_size
+ and tuple(img_tile.shape)[1] == split_size
+ and tuple(mask_tile.shape)[0] == split_size
+ and tuple(mask_tile.shape)[1] == split_size
+ ):
+ image_crop, mask_crop = randomsizedcrop(img_tile, mask_tile)
+ bins = np.array(range(num_classes + 1))
+ class_pixel_counts, _ = np.histogram(mask_crop, bins=bins)
+ cf = class_pixel_counts / (
+ tuple(mask_crop.shape)[0] * tuple(mask_crop.shape)[1]
+ )
+ if cf[4] > 0.1 and mode == "train":
+ car_imgs, car_masks = car_aug(image_crop, mask_crop)
+ for i in range(len(car_imgs)):
+ out_img_path = os.path.join(
+ imgs_output_dir,
+ "{}_{}_{}_{}.tif".format(img_filename, m, k, i),
+ )
+ cv2.imwrite(out_img_path, car_imgs[i])
+ out_mask_path = os.path.join(
+ masks_output_dir,
+ "{}_{}_{}_{}.png".format(mask_filename, m, k, i),
+ )
+ cv2.imwrite(out_mask_path, car_masks[i])
+ else:
+ out_img_path = os.path.join(
+ imgs_output_dir, "{}_{}_{}.tif".format(img_filename, m, k)
+ )
+ cv2.imwrite(out_img_path, img_tile)
+ out_mask_path = os.path.join(
+ masks_output_dir, "{}_{}_{}.png".format(mask_filename, m, k)
+ )
+ cv2.imwrite(out_mask_path, mask_tile)
+ k += 1
+
+
+if __name__ == "__main__":
+ seed_everything(SEED)
+ args = parse_args()
+ imgs_dir = args.img_dir
+ masks_dir = args.mask_dir
+ imgs_output_dir = args.output_img_dir
+ masks_output_dir = args.output_mask_dir
+ gt = args.gt
+ eroded = args.eroded
+ mode = args.mode
+ val_scale = args.val_scale
+ split_size = args.split_size
+ stride = args.stride
+ img_paths = glob.glob(os.path.join(imgs_dir, "*.tif"))
+ mask_paths_raw = glob.glob(os.path.join(masks_dir, "*.tif"))
+ if eroded:
+ mask_paths = [(p[:-15] + ".tif") for p in mask_paths_raw]
+ else:
+ mask_paths = mask_paths_raw
+ paddle.sort(x=img_paths), paddle.argsort(x=img_paths)
+ paddle.sort(x=mask_paths), paddle.argsort(x=mask_paths)
+ if not os.path.exists(imgs_output_dir):
+ os.makedirs(imgs_output_dir)
+ if not os.path.exists(masks_output_dir):
+ os.makedirs(masks_output_dir)
+ if gt:
+ os.makedirs(masks_output_dir + "/origin")
+ inp = [
+ (
+ img_path,
+ mask_path,
+ imgs_output_dir,
+ masks_output_dir,
+ eroded,
+ gt,
+ mode,
+ val_scale,
+ split_size,
+ stride,
+ )
+ for img_path, mask_path in zip(img_paths, mask_paths)
+ ]
+ t0 = time.time()
+ mpp.Pool(processes=mp.cpu_count()).map(vaihingen_format, inp)
+ t1 = time.time()
+ split_time = t1 - t0
+ print("images spliting spends: {} s".format(split_time))
diff --git a/examples/unetformer/train_supervision.py b/examples/unetformer/train_supervision.py
new file mode 100644
index 000000000..1040c460e
--- /dev/null
+++ b/examples/unetformer/train_supervision.py
@@ -0,0 +1,300 @@
+import argparse
+import os
+import random
+from pathlib import Path
+
+import numpy as np
+import paddle
+from paddle_utils import PaddleFlag
+from tools.cfg import py2cfg
+from tools.metric import Evaluator
+
+
+def seed_everything(seed):
+ random.seed(seed)
+ os.environ["PYTHONHASHSEED"] = str(seed)
+ np.random.seed(seed)
+ paddle.seed(seed=seed)
+ PaddleFlag.cudnn_deterministic = True
+ PaddleFlag.cudnn_benchmark = True
+
+
+def get_args():
+ parser = argparse.ArgumentParser()
+ arg = parser.add_argument
+ arg("-c", "--config_path", type=Path, help="Path to the config.", required=True)
+ return parser.parse_args()
+
+
+class Supervision_Train(paddle.nn.Layer):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.net = config.net
+ self.loss = config.loss
+ self.metrics_train = Evaluator(num_class=config.num_classes)
+ self.metrics_val = Evaluator(num_class=config.num_classes)
+ self.log_history = []
+ self.prog_bar_metrics = []
+
+ @classmethod
+ def load_from_checkpoint(cls, checkpoint_path, config):
+ model = cls(config)
+ state_dict = paddle.load(checkpoint_path)
+ model.set_state_dict(state_dict)
+ print(f"Loaded model weights from {checkpoint_path}")
+ return model
+
+ def forward(self, x):
+ seg_pre = self.net(x)
+ return seg_pre
+
+ def training_step(self, batch, batch_idx):
+ img, mask = batch["img"], batch["gt_semantic_seg"]
+ prediction = self.net(img)
+ loss = self.loss(prediction, mask)
+ if self.config.use_aux_loss:
+ pre_mask = paddle.nn.functional.softmax(prediction[0], axis=1)
+ else:
+ pre_mask = paddle.nn.functional.softmax(prediction, axis=1)
+ pre_mask = pre_mask.argmax(axis=1)
+ for i in range(tuple(mask.shape)[0]):
+ self.metrics_train.add_batch(mask[i].cpu().numpy(), pre_mask[i].numpy())
+ return {"loss": loss}
+
+ def on_train_epoch_end(self):
+ if "vaihingen" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_train.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_train.F1()[:-1])
+ elif "potsdam" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_train.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_train.F1()[:-1])
+ elif "whubuilding" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_train.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_train.F1()[:-1])
+ elif "massbuilding" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_train.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_train.F1()[:-1])
+ elif "cropland" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_train.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_train.F1()[:-1])
+ else:
+ mIoU = np.nanmean(self.metrics_train.Intersection_over_Union())
+ F1 = np.nanmean(self.metrics_train.F1())
+ OA = np.nanmean(self.metrics_train.OA())
+ iou_per_class = self.metrics_train.Intersection_over_Union()
+ eval_value = {"mIoU": mIoU, "F1": F1, "OA": OA}
+ print("train:", eval_value)
+ iou_value = {}
+ for class_name, iou in zip(self.config.classes, iou_per_class):
+ iou_value[class_name] = iou
+ self.metrics_train.reset()
+ log_dict = {"train_mIoU": mIoU, "train_F1": F1, "train_OA": OA}
+ print(f"Logging: {log_dict}")
+ self.log_dict(log_dict, prog_bar=True)
+ return log_dict
+
+ def validation_step(self, batch, batch_idx):
+ img, mask = batch["img"], batch["gt_semantic_seg"]
+ prediction = self.forward(img)
+ pre_mask = paddle.nn.functional.softmax(prediction, axis=1)
+ pre_mask = pre_mask.argmax(axis=1)
+ for i in range(tuple(mask.shape)[0]):
+ self.metrics_val.add_batch(mask[i].cpu().numpy(), pre_mask[i].cpu().numpy())
+ loss_val = self.loss(prediction, mask)
+ return {"loss_val": loss_val}
+
+ def on_validation_epoch_end(self):
+ if "vaihingen" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_val.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_val.F1()[:-1])
+ elif "potsdam" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_val.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_val.F1()[:-1])
+ elif "whubuilding" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_val.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_val.F1()[:-1])
+ elif "massbuilding" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_val.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_val.F1()[:-1])
+ elif "cropland" in self.config.log_name:
+ mIoU = np.nanmean(self.metrics_val.Intersection_over_Union()[:-1])
+ F1 = np.nanmean(self.metrics_val.F1()[:-1])
+ else:
+ mIoU = np.nanmean(self.metrics_val.Intersection_over_Union())
+ F1 = np.nanmean(self.metrics_val.F1())
+ OA = np.nanmean(self.metrics_val.OA())
+ iou_per_class = self.metrics_val.Intersection_over_Union()
+ eval_value = {"mIoU": mIoU, "F1": F1, "OA": OA}
+ print("val:", eval_value)
+ iou_value = {}
+ for class_name, iou in zip(self.config.classes, iou_per_class):
+ iou_value[class_name] = iou
+ print(iou_value)
+ self.metrics_val.reset()
+ log_dict = {"val_mIoU": mIoU, "val_F1": F1, "val_OA": OA}
+ self.log_dict(log_dict, prog_bar=True)
+ return log_dict
+
+ def configure_optimizers(self):
+ return self.config.optimizer, self.config.lr_scheduler
+
+ def train_dataloader(self):
+ return self.config.train_loader
+
+ def val_dataloader(self):
+ return self.config.val_loader
+
+ def log_dict(self, log_dict, prog_bar=False):
+ self.log_history.append(log_dict)
+ if prog_bar:
+ self.prog_bar_metrics = log_dict
+ metrics_str = ", ".join([f"{k}: {v:.4f}" for k, v in log_dict.items()])
+ print(f"[Metrics] {metrics_str}")
+
+
+class ModelCheckpoint:
+ def __init__(self, save_top_k, monitor, save_last, mode, dirpath, filename):
+ self.save_top_k = save_top_k
+ self.monitor = monitor
+ self.save_last = save_last
+ self.monitor_mode = mode
+ self.dirpath = dirpath
+ self.filename = filename
+ self.best_metric = -float("inf") if mode == "max" else float("inf")
+ self.best_path = ""
+ self.current_epoch = 0
+
+ def set_current_epoch(self, epoch):
+ self.current_epoch = epoch
+
+ def on_validation_epoch_end(self, trainer, model, val_log):
+ current_metric = val_log[self.monitor]
+ save_best = False
+ if self.monitor_mode == "max" and current_metric > self.best_metric:
+ self.best_metric = current_metric
+ save_best = True
+ elif self.monitor_mode == "min" and current_metric < self.best_metric:
+ self.best_metric = current_metric
+ save_best = True
+ if save_best:
+ self._remove_old_checkpoints()
+
+ self.best_path = os.path.join(
+ self.dirpath, f"{self.filename}_epoch{self.current_epoch}_best.pdparams"
+ )
+ paddle.save(model.state_dict(), self.best_path)
+ print(f"Saved best model to {self.best_path}")
+
+ if self.save_last:
+ last_path = os.path.join(self.dirpath, "last.pdparams")
+ paddle.save(model.state_dict(), last_path)
+
+ def _remove_old_checkpoints(self):
+ if self.save_top_k <= 0:
+ return
+
+ all_files = [
+ f
+ for f in os.listdir(self.dirpath)
+ if f.endswith(".pdparams") and self.filename in f
+ ]
+
+ all_files.sort(
+ key=lambda x: os.path.getmtime(os.path.join(self.dirpath, x)), reverse=True
+ )
+
+ while len(all_files) >= self.save_top_k:
+ file_to_remove = all_files.pop()
+ os.remove(os.path.join(self.dirpath, file_to_remove))
+ print(f"Removed old checkpoint: {file_to_remove}")
+
+
+class CSVLogger:
+ def __init__(self, save_dir, name):
+ self.save_dir = os.path.join(save_dir, name)
+ os.makedirs(self.save_dir, exist_ok=True)
+ self.log_file = os.path.join(self.save_dir, "metrics.csv")
+
+ if not os.path.exists(self.log_file):
+ with open(self.log_file, "w") as f:
+ f.write(
+ "epoch,train_loss,train_mIoU,train_F1,train_OA,val_loss,val_mIoU,val_F1,val_OA\n"
+ )
+
+ def log_metrics(self, epoch, train_log, val_log):
+ with open(self.log_file, "a") as f:
+ line = f"{epoch},{train_log.get('loss', '')},{train_log.get('train_mIoU', '')},{train_log.get('train_F1', '')},{train_log.get('train_OA', '')},"
+ line += f"{val_log.get('loss_val', '')},{val_log.get('val_mIoU', '')},{val_log.get('val_F1', '')},{val_log.get('val_OA', '')}\n"
+ f.write(line)
+
+
+def main():
+ args = get_args()
+ config = py2cfg(args.config_path)
+ seed_everything(42)
+ checkpoint_callback = ModelCheckpoint(
+ save_top_k=config.save_top_k,
+ monitor=config.monitor,
+ save_last=config.save_last,
+ mode=config.monitor_mode,
+ dirpath=config.weights_path,
+ filename=config.weights_name,
+ )
+
+ logger = CSVLogger("lightning_logs", name=config.log_name)
+
+ model = Supervision_Train(config)
+
+ if config.pretrained_ckpt_path:
+ state_dict = paddle.load(config.pretrained_ckpt_path)
+ model.set_state_dict(state_dict)
+
+ paddle.set_device("gpu")
+
+ optimizer, lr_scheduler = model.configure_optimizers()
+
+ train_loader = model.train_dataloader()
+ val_loader = model.val_dataloader()
+
+ for epoch in range(config.max_epoch):
+ print(f"Epoch {epoch+1}/{config.max_epoch}")
+ model.train()
+ train_losses = []
+ for batch_idx, batch in enumerate(train_loader):
+ output = model.training_step(batch, batch_idx)
+ loss = output["loss"]
+ train_losses.append(loss.item())
+ loss.backward()
+ optimizer.step()
+ optimizer.clear_grad()
+ if batch_idx % 10 == 0:
+ print(
+ f" Batch {batch_idx}/{len(train_loader)}, Loss: {loss.item():.4f}"
+ )
+
+ train_log = model.on_train_epoch_end()
+ train_log["loss"] = np.mean(train_losses)
+ if (epoch + 1) % config.check_val_every_n_epoch == 0:
+ model.eval()
+ val_losses = []
+ for batch_idx, batch in enumerate(val_loader):
+ output = model.validation_step(batch, batch_idx)
+ val_losses.append(output["loss_val"].item())
+ val_log = model.on_validation_epoch_end()
+ val_log["loss_val"] = np.mean(val_losses)
+ checkpoint_callback.on_validation_epoch_end(None, model, val_log)
+ logger.log_metrics(epoch, train_log, val_log)
+ if lr_scheduler:
+ lr_scheduler.step()
+ if config.resume_ckpt_path and epoch == 0:
+ state = paddle.load(config.resume_ckpt_path)
+ model.set_state_dict(state["model_state_dict"])
+ optimizer.set_state_dict(state["optimizer_state_dict"])
+ if lr_scheduler and "lr_scheduler_state_dict" in state:
+ lr_scheduler.set_state_dict(state["lr_scheduler_state_dict"])
+ print(f"Resumed training from checkpoint: {config.resume_ckpt_path}")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/unetformer/vaihingen_test.py b/examples/unetformer/vaihingen_test.py
new file mode 100644
index 000000000..a5418150f
--- /dev/null
+++ b/examples/unetformer/vaihingen_test.py
@@ -0,0 +1,125 @@
+import argparse
+import multiprocessing as mp
+import os
+import time
+from pathlib import Path
+
+import cv2
+import numpy as np
+import paddle
+from paddle_utils import add_tensor_methods
+from tqdm import tqdm
+from train_supervision import Evaluator
+from train_supervision import Supervision_Train
+from train_supervision import py2cfg
+from train_supervision import random
+
+add_tensor_methods()
+
+
+def seed_everything(seed):
+ random.seed(seed)
+ os.environ["PYTHONHASHSEED"] = str(seed)
+ np.random.seed(seed)
+ paddle.seed(seed=seed)
+
+
+def label2rgb(mask):
+ h, w = tuple(mask.shape)[0], tuple(mask.shape)[1]
+ mask_rgb = np.zeros(shape=(h, w, 3), dtype=np.uint8)
+ mask_convert = mask[(np.newaxis), :, :]
+ mask_rgb[np.all(mask_convert == 3, axis=0)] = [0, 255, 0]
+ mask_rgb[np.all(mask_convert == 0, axis=0)] = [255, 255, 255]
+ mask_rgb[np.all(mask_convert == 1, axis=0)] = [255, 0, 0]
+ mask_rgb[np.all(mask_convert == 2, axis=0)] = [255, 255, 0]
+ mask_rgb[np.all(mask_convert == 4, axis=0)] = [0, 204, 255]
+ mask_rgb[np.all(mask_convert == 5, axis=0)] = [0, 0, 255]
+ return mask_rgb
+
+
+def img_writer(inp):
+ mask, mask_id, rgb = inp
+ if rgb:
+ mask_name_tif = mask_id + ".png"
+ mask_tif = label2rgb(mask)
+ cv2.imwrite(mask_name_tif, mask_tif)
+ else:
+ mask_png = mask.astype(np.uint8)
+ mask_name_png = mask_id + ".png"
+ cv2.imwrite(mask_name_png, mask_png)
+
+
+def get_args():
+ parser = argparse.ArgumentParser()
+ arg = parser.add_argument
+ arg("-c", "--config_path", type=Path, required=True, help="Path to config")
+ arg("-o", "--output_path", type=Path, required=True, help="Output path for masks")
+ arg("--rgb", help="Output RGB images", action="store_true")
+ return parser.parse_args()
+
+
+def main():
+ seed_everything(42)
+ args = get_args()
+ config = py2cfg(args.config_path)
+ args.output_path.mkdir(exist_ok=True, parents=True)
+ model = Supervision_Train.load_from_checkpoint(
+ os.path.join(config.weights_path, config.test_weights_name + ".pdparams"),
+ config=config,
+ )
+ model.to(device="gpu")
+ model.eval()
+ evaluator = Evaluator(num_class=config.num_classes)
+ evaluator.reset()
+ test_dataset = config.test_dataset
+ test_loader = paddle.io.DataLoader(
+ dataset=test_dataset,
+ batch_size=2,
+ num_workers=4,
+ drop_last=False,
+ shuffle=False,
+ )
+
+ results = []
+ with paddle.no_grad():
+ for batch in tqdm(test_loader):
+ images = batch["img"]
+ images = images.astype("float32")
+ raw_predictions = model(images)
+
+ raw_predictions = paddle.nn.functional.softmax(raw_predictions, axis=1)
+ predictions = raw_predictions.argmax(axis=1)
+
+ image_ids = batch["img_id"]
+ masks_true = batch["gt_semantic_seg"]
+
+ for i in range(len(image_ids)):
+ mask = predictions[i].numpy()
+ evaluator.add_batch(pre_image=mask, gt_image=masks_true[i].numpy())
+ mask_name = image_ids[i]
+ results.append((mask, str(args.output_path / mask_name), args.rgb))
+
+ iou_per_class = evaluator.Intersection_over_Union()
+ f1_per_class = evaluator.F1()
+ OA = evaluator.OA()
+
+ for class_name, class_iou, class_f1 in zip(
+ config.classes, iou_per_class, f1_per_class
+ ):
+ print(f"F1_{class_name}: {class_f1:.4f}, IOU_{class_name}: {class_iou:.4f}")
+
+ print(
+ f"F1: {np.nanmean(f1_per_class[:-1]):.4f}, "
+ f"mIOU: {np.nanmean(iou_per_class[:-1]):.4f}, "
+ f"OA: {OA:.4f}"
+ )
+
+ t0 = time.time()
+ with mp.Pool(processes=mp.cpu_count()) as pool:
+ pool.map(img_writer, results)
+ t1 = time.time()
+ print(f"Images writing time: {t1 - t0:.2f} seconds")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/mkdocs.yml b/mkdocs.yml
index 2b5b4e5d8..2734d2a4d 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -113,6 +113,7 @@ nav:
- Pang-Weather: zh/examples/pangu_weather.md
- FengWu: zh/examples/fengwu.md
- FuXi: zh/examples/fuxi.md
+ - UNetFormer: zh/examples/unetformer.md
- WGAN_GP: zh/examples/wgan_gp.md
- 化学科学(AI for Chemistry):
- Moflow: zh/examples/moflow.md