From f79a3f9f07487ca7b4254264e0dd07e77daa1bf6 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 7 Feb 2025 20:26:33 +0800
Subject: [PATCH 01/49] Add files via upload
---
examples/demo/conf/stafnet.yaml | 136 ++++++++++++++++++++++++++++++++
examples/demo/demo.py | 130 ++++++++++++++++++++++++++++++
2 files changed, 266 insertions(+)
create mode 100644 examples/demo/conf/stafnet.yaml
create mode 100644 examples/demo/demo.py
diff --git a/examples/demo/conf/stafnet.yaml b/examples/demo/conf/stafnet.yaml
new file mode 100644
index 0000000000..238bcc3870
--- /dev/null
+++ b/examples/demo/conf/stafnet.yaml
@@ -0,0 +1,136 @@
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: outputs_chip_heat/${now:%Y-%m-%d}/${now:%H-%M-%S}/${hydra.job.override_dirname}
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ config:
+ override_dirname:
+ exclude_keys:
+ - TRAIN.checkpoint_path
+ - TRAIN.pretrained_model_path
+ - EVAL.pretrained_model_path
+ - mode
+ - output_dir
+ - log_freq
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: train # running mode: train/eval
+seed: 42
+output_dir: ${hydra:run.dir}
+log_freq: 20
+# dataset setting
+STAFNet_DATA_PATH: "/data6/home/yinhang2021/workspace/SATFNet/data/2020-2023_new/train_data.pkl" #
+DATASET:
+ label_keys: ["label"]
+ data_dir: "/data6/home/yinhang2021/workspace/SATFNet/data/2020-2023_new/train_data.pkl"
+ STAFNet_DATA_args: {
+ "data_dir": "/data6/home/yinhang2021/workspace/SATFNet/data/2020-2023_new/train_data.pkl",
+ "batch_size": 1,
+ "shuffle": True,
+ "num_workers": 0,
+ "training": True
+ }
+
+
+
+# "data_dir": "data/2020-2023_new/train_data.pkl",
+# "batch_size": 32,
+# "shuffle": True,
+# "num_workers": 0,
+# "training": True
+# model settings
+# MODEL: #
+
+
+MODEL:
+ input_keys: ["aq_train_data","mete_train_data",]
+ output_keys: ["label"]
+ configs:
+ output_attention: True
+ seq_len: 72
+ label_len: 24
+ pred_len: 48
+ aq_gat_node_features: 7
+ aq_gat_node_num: 35
+ mete_gat_node_features: 7
+ mete_gat_node_num: 18
+ gat_hidden_dim: 32
+ gat_edge_dim: 3
+ gat_embed_dim: 32
+ e_layers: 1
+ enc_in: 7
+ dec_in: 7
+ c_out: 7
+ d_model: 16
+ embed: "fixed"
+ freq: "t"
+ dropout: 0.05
+ factor: 3
+ n_heads: 4
+ d_ff: 32
+ num_kernels: 6
+ top_k: 4
+ # configs: {
+ # "task_name": "forecast",
+ # "output_attention": False,
+ # "seq_len": 72,
+ # "label_len": 24,
+ # "pred_len": 48,
+
+ # "aq_gat_node_features" : 7,
+ # "aq_gat_node_num": 35,
+
+ # "mete_gat_node_features" : 7,
+ # "mete_gat_node_num": 18,
+
+ # "gat_hidden_dim": 32,
+ # "gat_edge_dim": 3,
+ # "gat_embed_dim": 32,
+
+ # "e_layers": 1,
+ # "enc_in": 7,
+ # "dec_in": 7,
+ # "c_out": 7,
+ # "d_model": 16 ,
+ # "embed": "fixed",
+ # "freq": "t",
+ # "dropout": 0.05,
+ # "factor": 3,
+ # "n_heads": 4,
+
+ # "d_ff": 32 ,
+ # "num_kernels": 6,
+ # "top_k": 4
+ # }
+
+# training settings
+TRAIN: #
+ epochs: 100 #
+ iters_per_epoch: 400 #
+ save_freq: 10 #
+ eval_during_train: true #
+ eval_freq: 1000 #
+ batch_size: 1 #
+ lr_scheduler: #
+ epochs: ${TRAIN.epochs} #
+ iters_per_epoch: ${TRAIN.iters_per_epoch} #
+ learning_rate: 0.001 #
+ step_size: 10 #
+ gamma: 0.9 #
+ pretrained_model_path: null #
+ checkpoint_path: null #
+
+EVAL:
+ pretrained_model_path: null #
+ compute_metric_by_batch: false
+ eval_with_no_grad: true
+ batch_size: 1
\ No newline at end of file
diff --git a/examples/demo/demo.py b/examples/demo/demo.py
new file mode 100644
index 0000000000..8dd5eeb052
--- /dev/null
+++ b/examples/demo/demo.py
@@ -0,0 +1,130 @@
+
+
+import ppsci
+from ppsci.utils import logger
+from omegaconf import DictConfig
+import hydra
+import paddle
+from ppsci.data.dataset.stafnet_dataset import gat_lstmcollate_fn
+import multiprocessing
+
+def train(cfg: DictConfig):
+ # set model
+ model = ppsci.arch.STAFNet(**cfg.MODEL)
+ train_dataloader_cfg = {
+ "dataset": {
+ "name": "STAFNetDataset",
+ "file_path": cfg.DATASET.data_dir,
+ "input_keys": cfg.MODEL.input_keys,
+ "label_keys": cfg.MODEL.output_keys,
+ # "weight_dict": {"eta": 100},
+ "seq_len": cfg.MODEL.configs.seq_len,
+ "pred_len": cfg.MODEL.configs.pred_len,
+
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "collate_fn": gat_lstmcollate_fn,
+ }
+ eval_dataloader_cfg= {
+ "dataset": {
+ "name": "STAFNetDataset",
+ "file_path": cfg.STAFNet_DATA_PATH,
+ "input_keys": cfg.MODEL.input_keys,
+ "label_keys": cfg.MODEL.output_keys,
+ # "weight_dict": {"eta": 100},
+ "seq_len": cfg.MODEL.configs.seq_len,
+ "pred_len": cfg.MODEL.configs.pred_len,
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "collate_fn": gat_lstmcollate_fn,
+ }
+
+ sup_constraint = ppsci.constraint.SupervisedConstraint(
+ train_dataloader_cfg,
+ loss=ppsci.loss.MSELoss("mean"),
+ name="STAFNet_Sup",
+ # output_expr={"pred": lambda out: out["pred"]},
+ )
+ constraint = {sup_constraint.name: sup_constraint}
+ sup_validator = ppsci.validate.SupervisedValidator(
+ eval_dataloader_cfg,
+ loss=ppsci.loss.MSELoss("mean"),
+ metric={"MSE": ppsci.metric.MSE()},
+ name="Sup_Validator",
+ )
+ validator = {sup_validator.name: sup_validator}
+
+ # lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
+
+ # set optimizer
+ lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
+ LEARNING_RATE = cfg.TRAIN.lr_scheduler.learning_rate
+ optimizer = ppsci.optimizer.Adam(LEARNING_RATE)(model)
+ output_dir = cfg.output_dir
+ ITERS_PER_EPOCH = len(sup_constraint.data_loader)
+
+
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ constraint,
+ output_dir,
+ optimizer,
+ lr_scheduler,
+ cfg.TRAIN.epochs,
+ ITERS_PER_EPOCH,
+ eval_during_train=cfg.TRAIN.eval_during_train,
+ seed=cfg.seed,
+ validator=validator,
+ compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,
+ eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
+ )
+
+ # train model
+ solver.train()
+
+ return
+
+def evaluate(cfg: DictConfig):
+ """
+ Validate after training an epoch
+
+ :param epoch: Integer, current training epoch.
+ :return: A log that contains information about validation
+ """
+ pass
+
+
+@hydra.main(version_base=None, config_path="./conf", config_name="stafnet.yaml")
+def main(cfg: DictConfig):
+ if cfg.mode == "train":
+ train(cfg)
+ elif cfg.mode == "eval":
+ evaluate(cfg)
+ else:
+ raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
+
+
+
+
+if __name__ == "__main__":
+ # set random seed for reproducibility
+ ppsci.utils.misc.set_random_seed(42)
+ # set output directory
+ OUTPUT_DIR = "./output_example"
+ # initialize logger
+ logger.init_logger("ppsci", f"{OUTPUT_DIR}/train.log", "info")
+ multiprocessing.set_start_method("spawn")
+
+ main()
\ No newline at end of file
From 68b23d1fa5f755d6d79cf93e8047ef83f0e62b95 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 7 Feb 2025 20:39:48 +0800
Subject: [PATCH 02/49] Add files via upload
---
ppsci/data/dataset/stafnet_dataset.py | 187 ++++++++++++++++++++++++++
1 file changed, 187 insertions(+)
create mode 100644 ppsci/data/dataset/stafnet_dataset.py
diff --git a/ppsci/data/dataset/stafnet_dataset.py b/ppsci/data/dataset/stafnet_dataset.py
new file mode 100644
index 0000000000..5fed301d7f
--- /dev/null
+++ b/ppsci/data/dataset/stafnet_dataset.py
@@ -0,0 +1,187 @@
+import numpy as np
+import paddle
+import paddle.nn as nn
+import pgl
+from scipy.spatial.distance import cdist
+import pandas
+from paddle.io import Dataset, DataLoader
+from paddle import io
+from typing import Dict
+from typing import Optional
+from typing import Tuple
+
+def gat_lstmcollate_fn(data):
+ aq_train_data = []
+ mete_train_data = []
+ aq_g_list = []
+ mete_g_list = []
+ edge_index = []
+ edge_attr = []
+ pos = []
+ label = []
+ for unit in data:
+ aq_train_data.append(unit[0]['aq_train_data'])
+ mete_train_data.append(unit[0]['mete_train_data'])
+ aq_g_list = aq_g_list + unit[0]['aq_g_list']
+ mete_g_list = mete_g_list + unit[0]['mete_g_list']
+ label.append(unit[1])
+ label = paddle.stack(x=label)
+ x = label
+ perm_1 = list(range(x.ndim))
+ perm_1[1] = 2
+ perm_1[2] = 1
+ label = paddle.transpose(x=x, perm=perm_1)
+ label = paddle.flatten(x=label, start_axis=0, stop_axis=1)
+ return {'aq_train_data': paddle.stack(x=aq_train_data),
+ 'mete_train_data': paddle.stack(x=mete_train_data),
+ 'aq_G': pgl.graph.Graph.batch(aq_g_list),
+ 'mete_G': pgl.graph.Graph.batch(mete_g_list)
+ }, label
+
+
+class pygmmdataLoader(DataLoader):
+ """
+ MNIST data loading demo using BaseDataLoader
+ """
+
+ def __init__(self, args, data_dir, batch_size, shuffle=True,
+ num_workers=1, training=True, T=24, t=12, collate_fn=gat_lstmcollate_fn
+ ):
+ self.T = T
+ self.t = t
+ self.dataset = STAFNetDataset(args=args, file_path=file_path)
+ # if get_world_size() > 1:
+ # sampler = paddle.io.DistributedBatchSampler(dataset=self.
+ # dataset, shuffle=shuffle, batch_size=1)
+ # else:
+ # sampler = None
+ super().__init__(self.dataset, batch_size=batch_size, shuffle=shuffle, num_workers = num_workers,
+ collate_fn=collate_fn)
+
+class STAFNetDataset(io.Dataset):
+ """Dataset class for STAFNet data.
+
+ Args:
+ file_path (str): Path to the dataset file.
+ input_keys (Optional[Tuple[str, ...]]): Tuple of input keys. Defaults to None.
+ label_keys (Optional[Tuple[str, ...]]): Tuple of label keys. Defaults to None.
+ seq_len (int): Sequence length. Defaults to 72.
+ pred_len (int): Prediction length. Defaults to 48.
+ use_edge_attr (bool): Whether to use edge attributes. Defaults to True.
+
+ Examples:
+ >>> from ppsci.data.dataset import STAFNetDataset
+
+ >>> dataset = STAFNetDataset(file_path='example.pkl') # doctest: +SKIP
+
+ >>> # get the length of the dataset
+ >>> dataset_size = len(dataset) # doctest: +SKIP
+ >>> # get the first sample of the data
+ >>> first_sample = dataset[0] # doctest: +SKIP
+ >>> print("First sample:", first_sample) # doctest: +SKIP
+ """
+
+ def __init__(self,
+ file_path: str,
+ input_keys: Optional[Tuple[str, ...]] = None,
+ label_keys: Optional[Tuple[str, ...]] = None,
+ seq_len: int = 72,
+ pred_len: int = 48,
+ use_edge_attr: bool = True,):
+ """
+ root: 数据集保存的地方。
+ 会产生两个文件夹:
+ raw_dir(downloaded dataset) 和 processed_dir(processed data)。
+ """
+
+ self.file_path = file_path
+ self.input_keys = input_keys
+ self.label_keys = label_keys
+ self.use_edge_attr = use_edge_attr
+
+ self.seq_len = seq_len
+ self.pred_len = pred_len
+
+
+ super().__init__( )
+ if file_path.endswith('.pkl'):
+ with open(file_path, 'rb') as f:
+ self.data = pandas.read_pickle(f)
+ self.metedata = self.data['metedata']
+ self.AQdata = self.data['AQdata']
+ self.AQStation_imformation = self.data['AQStation_imformation']
+ self.meteStation_imformation = self.data['meteStation_imformation']
+ mete_coords = np.array(self.meteStation_imformation.loc[:, ['经度','纬度']]).astype('float64')
+ AQ_coords = np.array(self.AQStation_imformation.iloc[:, -2:]).astype('float64')
+ self.aq_edge_index, self.aq_edge_attr, self.aq_node_coords = (self.get_edge_attr(np.array(self.AQStation_imformation.iloc[:, -2:]).astype('float64')))
+ (self.mete_edge_index, self.mete_edge_attr, self.mete_node_coords) = (self.get_edge_attr(np.array(self.meteStation_imformation.loc[:, ['经度', '纬度']]).astype('float64')))
+
+ self.lut = self.find_nearest_point(AQ_coords, mete_coords)
+ # self.AQdata = np.concatenate((self.AQdata, self.metedata[:, self.lut, -7:]), axis=2)
+
+
+ def __len__(self):
+ return len(self.AQdata) - self.seq_len - self.pred_len
+
+ def __getitem__(self, idx):
+ input_data = {}
+ aq_train_data = paddle.to_tensor(data=self.AQdata[idx:idx + self.seq_len + self.pred_len]).astype(dtype='float32')
+ mete_train_data = paddle.to_tensor(data=self.metedata[idx:idx + self.seq_len + self.pred_len]).astype(dtype='float32')
+ aq_g_list = [pgl.Graph(num_nodes=s.shape[0],
+ edges=self.aq_edge_index,
+ node_feat={
+ "feature": s,
+ "pos": self.aq_node_coords.astype(dtype='float32')
+ },
+ edge_feat={
+ "edge_feature": self.aq_edge_attr.astype(dtype='float32')
+ })for s in aq_train_data[:self.seq_len]]
+
+ mete_g_list = [pgl.Graph(num_nodes=s.shape[0],
+ edges=self.mete_edge_index,
+ node_feat={
+ "feature": s,
+ "pos": self.mete_node_coords.astype(dtype='float32')
+ },
+ edge_feat={
+ "edge_feature": self.mete_edge_attr.astype(dtype='float32')
+ })for s in mete_train_data[:self.seq_len]]
+
+ # aq_g_list = [pgl.Graph(x=s, edge_index=self.aq_edge_index, edge_attr=self.aq_edge_attr.astype(dtype='float32'), pos=self.aq_node_coords.astype(dtype='float32')) for s in aq_train_data[:self.seq_len]]
+ # mete_g_list = [pgl.Graph((x=s, edge_index=self.
+ # mete_edge_index, edge_attr=self.mete_edge_attr.astype(dtype=
+ # 'float32'), pos=self.mete_node_coords.astype(dtype='float32')) for
+ # s in mete_train_data[:self.seq_len]]
+
+
+ label = aq_train_data[-self.pred_len:, :, -7:]
+ data = {'aq_train_data': aq_train_data, 'mete_train_data': mete_train_data,
+ # 'aq_g_list': aq_g_list, 'mete_g_list': mete_g_list
+ }
+ input_item = {'aq_train_data': aq_train_data, 'mete_train_data': mete_train_data,
+ # 'aq_g_list': aq_g_list, 'mete_g_list': mete_g_list
+ }
+ label_item = {self.label_keys[0]: aq_train_data[-self.pred_len:, :, -7:]}
+
+ return input_item, label_item, {}
+ # return data, label,
+
+ def get_edge_attr(self, node_coords, threshold=0.2):
+ # node_coords = paddle.to_tensor(data=node_coords)
+ dist_matrix = cdist(node_coords, node_coords)
+ edge_index = np.where(dist_matrix < threshold)
+ # edge_index = paddle.to_tensor(data=edge_index, dtype='int64')
+ start_nodes, end_nodes = edge_index
+ edge_lengths = dist_matrix[start_nodes, end_nodes]
+ edge_directions = node_coords[end_nodes] - node_coords[start_nodes]
+ edge_attr = paddle.to_tensor(data=np.concatenate((edge_lengths[:,
+ np.newaxis], edge_directions), axis=1))
+ node_coords = paddle.to_tensor(data=node_coords)
+ return edge_index, edge_attr, node_coords
+
+ def find_nearest_point(self, A, B):
+ nearest_indices = []
+ for a in A:
+ distances = [np.linalg.norm(a - b) for b in B]
+ nearest_indices.append(np.argmin(distances))
+ return nearest_indices
\ No newline at end of file
From d9d2b542a9704680a631b1637aeb0e91c570793f Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 7 Feb 2025 20:41:23 +0800
Subject: [PATCH 03/49] Update __init__.py
---
ppsci/data/dataset/__init__.py | 2 ++
1 file changed, 2 insertions(+)
diff --git a/ppsci/data/dataset/__init__.py b/ppsci/data/dataset/__init__.py
index 40d14c0f61..1547fd26b0 100644
--- a/ppsci/data/dataset/__init__.py
+++ b/ppsci/data/dataset/__init__.py
@@ -45,6 +45,7 @@
from ppsci.data.dataset.radar_dataset import RadarDataset
from ppsci.data.dataset.sevir_dataset import SEVIRDataset
from ppsci.data.dataset.spherical_swe_dataset import SphericalSWEDataset
+from ppsci.data.dataset.stafnet_dataset import STAFNetDataset
from ppsci.data.dataset.trphysx_dataset import CylinderDataset
from ppsci.data.dataset.trphysx_dataset import LorenzDataset
from ppsci.data.dataset.trphysx_dataset import RosslerDataset
@@ -91,6 +92,7 @@
"FWIDataset",
"DrivAerNetDataset",
"IFMMoeDataset",
+ "STAFNetDataset",
]
From bfa3e697413e730d596ef1dfa7f313fa351ac62c Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 7 Feb 2025 20:46:31 +0800
Subject: [PATCH 04/49] Add files via upload
---
ppsci/arch/stafnet.py | 575 ++++++++++++++++++++++++++++++++++++++++++
1 file changed, 575 insertions(+)
create mode 100644 ppsci/arch/stafnet.py
diff --git a/ppsci/arch/stafnet.py b/ppsci/arch/stafnet.py
new file mode 100644
index 0000000000..583f2ceba3
--- /dev/null
+++ b/ppsci/arch/stafnet.py
@@ -0,0 +1,575 @@
+import paddle
+import paddle.nn as nn
+import os
+import numpy as np
+import math
+from math import sqrt
+# from Embed import DataEmbedding
+import argparse
+from ppsci.arch import base
+from tqdm import tqdm
+from pgl.nn.conv import GATv2Conv
+from typing import TYPE_CHECKING
+from typing import Dict
+from typing import Tuple
+
+class Inception_Block_V1(paddle.nn.Layer):
+
+ def __init__(self, in_channels, out_channels, num_kernels=6,
+ init_weight=True):
+ super(Inception_Block_V1, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_kernels = num_kernels
+ kernels = []
+ for i in range(self.num_kernels):
+ kernels.append(paddle.nn.Conv2D(in_channels=in_channels,
+ out_channels=out_channels, kernel_size=2 * i + 1, padding=i))
+ self.kernels = paddle.nn.LayerList(sublayers=kernels)
+ if init_weight:
+ self._initialize_weights()
+
+ def _initialize_weights(self):
+ for m in self.sublayers():
+ if isinstance(m, paddle.nn.Conv2D):
+
+ init_kaimingNormal = paddle.nn.initializer.KaimingNormal(fan_in=None,
+ negative_slope=0.0, nonlinearity='relu')
+ init_kaimingNormal(m.weight)
+
+ if m.bias is not None:
+ init_Constant = paddle.nn.initializer.Constant(value=0)
+ init_Constant(m.bias)
+
+ def forward(self, x):
+ res_list = []
+ for i in range(self.num_kernels):
+ res_list.append(self.kernels[i](x))
+ res = paddle.stack(x=res_list, axis=-1).mean(axis=-1)
+ return res
+
+class AttentionLayer(paddle.nn.Layer):
+
+ def __init__(self, attention, d_model, n_heads, d_keys=None, d_values=None
+ ):
+ super(AttentionLayer, self).__init__()
+ d_keys = d_keys or d_model // n_heads
+ d_values = d_values or d_model // n_heads
+ self.inner_attention = attention
+ self.query_projection = paddle.nn.Linear(in_features=d_model,
+ out_features=d_keys * n_heads)
+ self.key_projection = paddle.nn.Linear(in_features=d_model,
+ out_features=d_keys * n_heads)
+ self.value_projection = paddle.nn.Linear(in_features=d_model,
+ out_features=d_values * n_heads)
+ self.out_projection = paddle.nn.Linear(in_features=d_values *
+ n_heads, out_features=d_model)
+ self.n_heads = n_heads
+
+ def forward(self, queries, keys, values, attn_mask):
+ B, L, _ = tuple(queries.shape)
+ _, S, _ = tuple(keys.shape)
+ H = self.n_heads
+ queries = self.query_projection(queries).reshape((B, L, H, -1))
+ keys = self.key_projection(keys).reshape((B, S, H, -1))
+ values = self.value_projection(values).reshape((B, S, H, -1))
+ out, attn = self.inner_attention(queries, keys, values, attn_mask)
+ out = out.reshape((B, L, -1))
+ return self.out_projection(out), attn
+
+class ProbAttention(paddle.nn.Layer):
+
+ def __init__(self, mask_flag=True, factor=5, scale=None,
+ attention_dropout=0.1, output_attention=False):
+ super(ProbAttention, self).__init__()
+ self.factor = factor
+ self.scale = scale
+ self.mask_flag = mask_flag
+ self.output_attention = output_attention
+ self.dropout = paddle.nn.Dropout(p=attention_dropout)
+
+ def _prob_QK(self, Q, K, sample_k, n_top):
+ B, H, L_K, E = tuple(K.shape)
+ _, _, L_Q, _ = tuple(Q.shape)
+ K_expand = K.unsqueeze(axis=-3).expand(shape=[B, H, L_Q, L_K, E])
+ index_sample = paddle.randint(low=0, high=L_K, shape=[L_Q, sample_k])
+ # index_sample = torch.randint(L_K, (L_Q, sample_k))
+ K_sample = K_expand[:, :, paddle.arange(end=L_Q).unsqueeze(axis=1), index_sample, :]
+
+ x = K_sample
+ perm_5 = list(range(x.ndim))
+ perm_5[-2] = -1
+ perm_5[-1] = -2
+ Q_K_sample = paddle.matmul(x=Q.unsqueeze(axis=-2), y=x.transpose(
+ perm=perm_5)).squeeze()
+ M = Q_K_sample.max(-1)[0] - paddle.divide(x=Q_K_sample.sum(axis=-1),
+ y=paddle.to_tensor(L_K,dtype ='float32') )
+ M_top = M.topk(k=n_top, sorted=False)[1]
+ Q_reduce = Q[paddle.arange(end=B)[:, None, None], paddle.arange(end
+ =H)[None, :, None], M_top, :]
+ x = K
+ perm_6 = list(range(x.ndim))
+ perm_6[-2] = -1
+ perm_6[-1] = -2
+ Q_K = paddle.matmul(x=Q_reduce, y=x.transpose(perm=perm_6))
+ return Q_K, M_top
+
+ def _get_initial_context(self, V, L_Q):
+ B, H, L_V, D = tuple(V.shape)
+ if not self.mask_flag:
+ V_sum = V.mean(axis=-2)
+ contex = V_sum.unsqueeze(axis=-2).expand(shape=[B, H, L_Q,
+ tuple(V_sum.shape)[-1]]).clone()
+ else:
+ assert L_Q == L_V
+ contex = V.cumsum(axis=-2)
+ return contex
+
+ def _update_context(self, context_in, V, scores, index, L_Q, attn_mask):
+ B, H, L_V, D = tuple(V.shape)
+ if self.mask_flag:
+ attn_mask = ProbMask(B, H, L_Q, index, scores, device=V.place)
+ scores.masked_fill_(mask=attn_mask.mask, value=-np.inf)
+ attn = paddle.nn.functional.softmax(x=scores, axis=-1)
+ context_in[paddle.arange(end=B)[:, None, None], paddle.arange(end=H
+ )[None, :, None], index, :] = paddle.matmul(x=attn, y=V).astype(
+ dtype=context_in.dtype)
+ if self.output_attention:
+ attns = (paddle.ones(shape=[B, H, L_Q, L_V]) / L_V).astype(dtype
+ =attn.dtype).to(attn.place)
+ attns[paddle.arange(end=B)[:, None, None], paddle.arange(end=H)
+ [None, :, None], index, :] = attn
+ return context_in, attns
+ else:
+ return context_in, None
+
+ def forward(self, queries, keys, values, attn_mask):
+ B, L_Q, H, D = tuple(queries.shape)
+ _, L_K, _, _ = tuple(keys.shape)
+ x = queries
+ perm_7 = list(range(x.ndim))
+ perm_7[2] = 1
+ perm_7[1] = 2
+ queries = x.transpose(perm=perm_7)
+ x = keys
+ perm_8 = list(range(x.ndim))
+ perm_8[2] = 1
+ perm_8[1] = 2
+ keys = x.transpose(perm=perm_8)
+ x = values
+ perm_9 = list(range(x.ndim))
+ perm_9[2] = 1
+ perm_9[1] = 2
+ values = x.transpose(perm=perm_9)
+ U_part = self.factor * np.ceil(np.log(L_K)).astype('int').item()
+ u = self.factor * np.ceil(np.log(L_Q)).astype('int').item()
+ U_part = U_part if U_part < L_K else L_K
+ u = u if u < L_Q else L_Q
+ scores_top, index = self._prob_QK(queries, keys, sample_k=U_part,
+ n_top=u)
+ scale = self.scale or 1.0 / sqrt(D)
+ if scale is not None:
+ scores_top = scores_top * scale
+ context = self._get_initial_context(values, L_Q)
+ context, attn = self._update_context(context, values, scores_top,
+ index, L_Q, attn_mask)
+ return context, attn
+
+
+def FFT_for_Period(x, k=2):
+ xf = paddle.fft.rfft(x=x, axis=1)
+ frequency_list = paddle.abs(xf).mean(axis=0).mean(axis=-1)
+ frequency_list[0] = 0
+ _, top_list = paddle.topk(k=k, x=frequency_list)
+ top_list = top_list.detach().cpu().numpy()
+ period = tuple(x.shape)[1] // top_list
+ return period, paddle.index_select(paddle.abs(xf).mean(axis=-1), paddle.to_tensor(top_list), axis=1)
+
+
+class TimesBlock(paddle.nn.Layer):
+
+ def __init__(self, configs):
+ super(TimesBlock, self).__init__()
+ self.seq_len = configs.seq_len
+ self.pred_len = configs.pred_len
+ self.k = configs.top_k
+ self.conv = paddle.nn.Sequential(Inception_Block_V1(configs.d_model,
+ configs.d_ff, num_kernels=configs.num_kernels), paddle.nn.GELU(
+ ), Inception_Block_V1(configs.d_ff, configs.d_model,
+ num_kernels=configs.num_kernels))
+
+ def forward(self, x):
+ B, T, N = tuple(x.shape)
+ period_list, period_weight = FFT_for_Period(x, self.k)
+ res = []
+ for i in range(self.k):
+ period = period_list[i]
+ if (self.seq_len + self.pred_len) % period != 0:
+ length = ((self.seq_len + self.pred_len) // period + 1
+ ) * period
+ padding = paddle.zeros(shape=[tuple(x.shape)[0], length - (
+ self.seq_len + self.pred_len), tuple(x.shape)[2]])
+ out = paddle.concat(x=[x, padding], axis=1)
+ else:
+ length = self.seq_len + self.pred_len
+ out = x
+ out = out.reshape((B, length // period, period, N)).transpose(perm=[0, 3, 1, 2])
+ out = self.conv(out)
+ out = out.transpose(perm=[0, 2, 3, 1]).reshape((B, -1, N))
+ res.append(out[:, :self.seq_len + self.pred_len, :])
+ res = paddle.stack(x=res, axis=-1)
+ period_weight_raw = period_weight
+ period_weight = paddle.nn.functional.softmax(x=period_weight, axis=1)
+ # print(period_weight.unsqueeze(axis=1).unsqueeze(axis=1).shape)
+ # period_weight = period_weight.unsqueeze(axis=1).unsqueeze(axis=1
+ # ).repeat(1, T, N, 1)
+ period_weight = paddle.tile(period_weight.unsqueeze(axis=1).unsqueeze(axis=1
+ ), (1, T, N, 1))
+ res = paddle.sum(x=res * period_weight, axis=-1)
+ res = res + x
+ return res, period_list, period_weight_raw
+
+
+
+
+def compared_version(ver1, ver2):
+ """
+ :param ver1
+ :param ver2
+ :return: ver1< = >ver2 False/True
+ """
+ list1 = str(ver1).split('.')
+ list2 = str(ver2).split('.')
+ for i in (range(len(list1)) if len(list1) < len(list2) else range(len(
+ list2))):
+ if int(list1[i]) == int(list2[i]):
+ pass
+ elif int(list1[i]) < int(list2[i]):
+ return -1
+ else:
+ return 1
+ if len(list1) == len(list2):
+ return True
+ elif len(list1) < len(list2):
+ return False
+ else:
+ return True
+
+
+class PositionalEmbedding(paddle.nn.Layer):
+
+ def __init__(self, d_model, max_len=5000):
+ super(PositionalEmbedding, self).__init__()
+ pe = paddle.zeros(shape=[max_len, d_model]).astype(dtype='float32')
+ pe.stop_gradient = True
+ position = paddle.arange(start=0, end=max_len).astype(dtype='float32'
+ ).unsqueeze(axis=1)
+ div_term = (paddle.arange(start=0, end=d_model, step=2).astype(
+ dtype='float32') * -(math.log(10000.0) / d_model)).exp()
+ pe[:, 0::2] = paddle.sin(x=position * div_term)
+ pe[:, 1::2] = paddle.cos(x=position * div_term)
+ pe = pe.unsqueeze(axis=0)
+ self.register_buffer(name='pe', tensor=pe)
+
+ def forward(self, x):
+ return self.pe[:, :x.shape[1]]
+
+
+class TokenEmbedding(paddle.nn.Layer):
+
+ def __init__(self, c_in, d_model):
+ super(TokenEmbedding, self).__init__()
+ padding = 1 if compared_version(paddle.__version__, '1.5.0') else 2
+ self.tokenConv = paddle.nn.Conv1D(in_channels=c_in, out_channels=
+ d_model, kernel_size=3, padding=padding, padding_mode=
+ 'circular', bias_attr=False)
+ for m in self.sublayers():
+ if isinstance(m, paddle.nn.Conv1D):
+ init_KaimingNormal = paddle.nn.initializer.KaimingNormal(
+ nonlinearity='leaky_relu')
+ init_KaimingNormal(m.weight)
+
+ def forward(self, x):
+ x = self.tokenConv(x.transpose(perm=[0, 2, 1]))
+ perm_13 = list(range(x.ndim))
+ perm_13[1] = 2
+ perm_13[2] = 1
+ x = x.transpose(perm=perm_13)
+ return x
+
+
+class FixedEmbedding(paddle.nn.Layer):
+
+ def __init__(self, c_in, d_model):
+ super(FixedEmbedding, self).__init__()
+ w = paddle.zeros(shape=[c_in, d_model]).astype(dtype='float32')
+ w.stop_gradient = True
+ position = paddle.arange(start=0, end=c_in).astype(dtype='float32'
+ ).unsqueeze(axis=1)
+ div_term = (paddle.arange(start=0, end=d_model, step=2).astype(
+ dtype='float32') * -(math.log(10000.0) / d_model)).exp()
+ w[:, 0::2] = paddle.sin(x=position * div_term)
+ w[:, 1::2] = paddle.cos(x=position * div_term)
+ self.emb = paddle.nn.Embedding(num_embeddings=c_in, embedding_dim=
+ d_model)
+ out_3 = paddle.create_parameter(shape=w.shape, dtype=w.numpy().
+ dtype, default_initializer=paddle.nn.initializer.Assign(w))
+ out_3.stop_gradient = not False
+ self.emb.weight = out_3
+
+ def forward(self, x):
+ return self.emb(x).detach()
+
+
+class TemporalEmbedding(paddle.nn.Layer):
+
+ def __init__(self, d_model, embed_type='fixed', freq='h'):
+ super(TemporalEmbedding, self).__init__()
+ minute_size = 4
+ hour_size = 24
+ weeknum_size = 53
+ weekday_size = 7
+ day_size = 32
+ month_size = 13
+ Embed = (FixedEmbedding if embed_type == 'fixed' else paddle.nn.
+ Embedding)
+ if freq == 't':
+ self.minute_embed = Embed(minute_size, d_model)
+ self.hour_embed = Embed(hour_size, d_model)
+ self.weekday_embed = Embed(weekday_size, d_model)
+ self.weeknum_embed = Embed(weeknum_size, d_model)
+ self.day_embed = Embed(day_size, d_model)
+ self.month_embed = Embed(month_size, d_model)
+ self.Temporal_feature = ['month', 'day', 'week', 'weekday', 'hour']
+
+ def forward(self, x):
+ x = x.astype(dtype='int64')
+ for idx, freq in enumerate(self.Temporal_feature):
+ if freq == 'year':
+ pass
+ elif freq == 'month':
+ month_x = self.month_embed(x[:, :, idx])
+ elif freq == 'day':
+ day_x = self.day_embed(x[:, :, idx])
+ elif freq == 'week':
+ weeknum_x = self.weeknum_embed(x[:, :, idx])
+ elif freq == 'weekday':
+ weekday_x = self.weekday_embed(x[:, :, idx])
+ elif freq == 'hour':
+ hour_x = self.hour_embed(x[:, :, idx])
+ return hour_x + weekday_x + weeknum_x + day_x + month_x
+
+
+class TimeFeatureEmbedding(paddle.nn.Layer):
+
+ def __init__(self, d_model, embed_type='timeF', freq='h'):
+ super(TimeFeatureEmbedding, self).__init__()
+ freq_map = {'h': 4, 't': 5, 's': 6, 'm': 1, 'a': 1, 'w': 2, 'd': 3,
+ 'b': 3}
+ d_inp = freq_map[freq]
+ self.embed = paddle.nn.Linear(in_features=d_inp, out_features=
+ d_model, bias_attr=False)
+
+ def forward(self, x):
+ return self.embed(x)
+
+
+class DataEmbedding(paddle.nn.Layer):
+
+ def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1
+ ):
+ super(DataEmbedding, self).__init__()
+ self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)
+ self.position_embedding = PositionalEmbedding(d_model=d_model)
+ self.temporal_embedding = TemporalEmbedding(d_model=d_model,
+ embed_type=embed_type, freq=freq
+ ) if embed_type != 'timeF' else TimeFeatureEmbedding(d_model=
+ d_model, embed_type=embed_type, freq=freq)
+ self.dropout = paddle.nn.Dropout(p=dropout)
+
+ def forward(self, x, x_mark):
+ x = self.value_embedding(x) #+ self.temporal_embedding(x_mark) + self.position_embedding(x)
+ return self.dropout(x)
+
+
+
+class DataEmbedding_wo_pos(paddle.nn.Layer):
+
+ def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1
+ ):
+ super(DataEmbedding_wo_pos, self).__init__()
+ self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)
+ self.position_embedding = PositionalEmbedding(d_model=d_model)
+ self.temporal_embedding = TemporalEmbedding(d_model=d_model,
+ embed_type=embed_type, freq=freq
+ ) if embed_type != 'timeF' else TimeFeatureEmbedding(d_model=
+ d_model, embed_type=embed_type, freq=freq)
+ self.dropout = paddle.nn.Dropout(p=dropout)
+
+ def forward(self, x, x_mark):
+ x = self.value_embedding(x) + self.temporal_embedding(x_mark)
+ return self.dropout(x)
+
+class GAT_Encoder(paddle.nn.Layer):
+
+ def __init__(self, input_dim, hid_dim, edge_dim, gnn_embed_dim, dropout):
+ super(GAT_Encoder, self).__init__()
+ self.input_dim = input_dim
+ self.hid_dim = hid_dim
+ self.relu = paddle.nn.ReLU()
+ self.dropout = paddle.nn.Dropout(p=dropout)
+ self.conv1 = GATv2Conv(input_dim, hid_dim, )
+ self.conv2 = GATv2Conv(hid_dim, hid_dim * 2, )
+ self.conv3 = GATv2Conv(hid_dim * 2, gnn_embed_dim,)
+
+ def forward(self,graph, feature, ):
+ x = self.conv1(graph, feature )
+ x = self.relu(x)
+ # x = x.relu()
+ x = self.conv2(graph, x)
+ x = self.relu(x)
+ x = self.conv3(graph, x)
+ x = self.dropout(x)
+
+ return x
+
+
+class STAFNet(base.Arch):
+
+ def __init__(
+ self,
+ input_keys: Tuple[str, ...],
+ output_keys: Tuple[str, ...],
+ configs, **kwargs):
+ super(STAFNet, self).__init__()
+ # configs = argparse.Namespace(**configs)
+ self.input_keys = input_keys
+ self.output_keys = output_keys
+ self.device = str('cuda').replace('cuda', 'gpu')
+ self.configs = configs
+ if hasattr(configs, 'output_attention'):
+ self.output_attention = configs.output_attention
+ else:
+ self.output_attention = False
+ self.seq_len = configs.seq_len
+ self.label_len = configs.label_len
+ self.pred_len = configs.pred_len
+ self.dec_in = configs.dec_in
+ self.gat_embed_dim = configs.enc_in
+ self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model,
+ configs.embed, configs.freq, configs.dropout)
+ self.aq_gat_node_num = configs.aq_gat_node_num
+ self.aq_gat_node_features = configs.aq_gat_node_features
+ self.aq_GAT = GAT_Encoder(configs.aq_gat_node_features, configs.
+ gat_hidden_dim, configs.gat_edge_dim, self.gat_embed_dim,
+ configs.dropout).to(self.device)
+ self.mete_gat_node_num = configs.mete_gat_node_num
+ self.mete_gat_node_features = configs.mete_gat_node_features
+ self.mete_GAT = GAT_Encoder(configs.mete_gat_node_features, configs
+ .gat_hidden_dim, configs.gat_edge_dim, self.gat_embed_dim,
+ configs.dropout).to(self.device)
+ self.pos_fc = paddle.nn.Linear(in_features=2, out_features=configs.
+ gat_embed_dim, bias_attr=True)
+ self.fusion_Attention = AttentionLayer(ProbAttention(False, configs
+ .factor, attention_dropout=configs.dropout, output_attention=
+ self.output_attention), configs.gat_embed_dim, configs.n_heads)
+ self.model = paddle.nn.LayerList(sublayers=[TimesBlock(configs) for
+ _ in range(configs.e_layers)])
+ self.layer = configs.e_layers
+ self.layer_norm = paddle.nn.LayerNorm(normalized_shape=configs.d_model)
+ self.predict_linear = paddle.nn.Linear(in_features=self.seq_len,
+ out_features=self.pred_len + self.seq_len)
+ self.projection = paddle.nn.Linear(in_features=configs.d_model,
+ out_features=configs.c_out, bias_attr=True)
+
+
+ def aq_gat(self, G):
+ # x = G.x[:, -self.aq_gat_node_features:].to(self.device)
+ # edge_index = G.edge_index.to(self.device)
+ # edge_attr = G.edge_attr.to(self.device)
+ g_batch = G.num_graph
+ batch_size = int(g_batch/self.seq_len)
+ gat_output = self.aq_GAT(G, G.node_feat["feature"][:, -self.aq_gat_node_features:])
+ gat_output = gat_output.reshape((batch_size, self.seq_len, self.
+ aq_gat_node_num, self.gat_embed_dim))
+ gat_output = paddle.flatten(x=gat_output, start_axis=0, stop_axis=1)
+ return gat_output
+
+ def mete_gat(self, G):
+ # x = G.x[:, -self.mete_gat_node_features:].to(self.device)
+ # edge_index = G.edge_index.to(self.device)
+ # edge_attr = G.edge_attr.to(self.device)
+ g_batch = G.num_graph
+ batch_size = int(g_batch/self.seq_len)
+ gat_output = self.mete_GAT(G, G.node_feat["feature"][:, -self.mete_gat_node_features:])
+ gat_output = gat_output.reshape((batch_size, self.seq_len, self.
+ mete_gat_node_num, self.gat_embed_dim))
+ gat_output = paddle.flatten(x=gat_output, start_axis=0, stop_axis=1)
+ return gat_output
+
+ def norm_pos(self, A, B):
+ # paddle.mean(x)
+ A_mean = paddle.mean(A, axis=0)
+ A_std = paddle.std(A, axis=0)
+
+ A_norm = (A - A_mean) / A_std
+ B_norm = (B - A_mean) / A_std
+ return A_norm, B_norm
+
+ def forward(self, Data, mask=None):
+ # aq_G = Data['aq_G']
+ # mete_G = Data['mete_G']
+ # aq_gat_output = self.aq_gat(aq_G)
+ # mete_gat_output = self.mete_gat(mete_G)
+ # aq_pos, mete_pos = self.norm_pos(aq_G.node_feat["pos"], mete_G.node_feat["pos"])
+
+
+ # aq_pos = self.pos_fc(aq_pos).reshape((-1, self.aq_gat_node_num, self.
+ # gat_embed_dim))
+ # mete_pos = self.pos_fc(mete_pos).reshape((-1, self.mete_gat_node_num,
+ # self.gat_embed_dim))
+ # fusion_out, attn = self.fusion_Attention(aq_pos, mete_pos, mete_gat_output, attn_mask=None)
+ # aq_gat_output = aq_gat_output + fusion_out
+ # aq_gat_output = aq_gat_output.reshape((-1, self.seq_len, self.
+ # aq_gat_node_num, self.gat_embed_dim))
+ # x = aq_gat_output
+ # perm_0 = list(range(x.ndim))
+ # perm_0[1] = 2
+ # perm_0[2] = 1
+ # aq_gat_output = paddle.transpose(x=x, perm=perm_0)
+ # aq_gat_output = paddle.flatten(x=aq_gat_output, start_axis=0,
+ # stop_axis=1)
+
+ train_data = Data['aq_train_data']
+ batch_size = train_data.shape[0]
+ x = train_data
+ perm_1 = list(range(x.ndim))
+ perm_1[1] = 2
+ perm_1[2] = 1
+ train_data = paddle.transpose(x=x, perm=perm_1)
+ train_data = paddle.flatten(x=train_data, start_axis=0, stop_axis=1)
+ x_enc = train_data[:, :self.seq_len, -self.dec_in:]
+ x_mark_enc = train_data[:, :self.seq_len, 1:6]
+
+ means = x_enc.mean(axis=1, keepdim=True).detach()
+ x_enc = x_enc - means
+ stdev = paddle.sqrt(x=paddle.var(x=x_enc, axis=1, keepdim=True,
+ unbiased=False) + 1e-05)
+ x_enc /= stdev
+ # enc_out = self.enc_embedding(aq_gat_output, x_mark_enc)
+ enc_out = self.enc_embedding(x_enc, x_mark_enc)
+ enc_out = self.predict_linear(enc_out.transpose(perm=[0, 2, 1])
+ ).transpose(perm=[0, 2, 1])
+ for i in range(self.layer):
+ enc_out, period_list, period_weight = self.model[i](enc_out)
+ enc_out = self.layer_norm(enc_out)
+ dec_out = self.projection(enc_out)
+ dec_out = dec_out * paddle.tile( stdev[:, 0, :].unsqueeze(axis=1), (1, self.pred_len + self.seq_len, 1))
+ dec_out = dec_out + paddle.tile(means[:, 0, :].unsqueeze(axis=1), (1, self.pred_len + self.seq_len, 1))
+ # dec_out = dec_out * stdev[:, 0, :].unsqueeze(axis=1).repeat(1, self
+ # .pred_len + self.seq_len, 1)
+ # dec_out = dec_out + means[:, 0, :].unsqueeze(axis=1).repeat(1, self
+ # .pred_len + self.seq_len, 1)
+
+
+ return {self.output_keys[0]: dec_out[ :,-self.pred_len:, -7:].reshape((batch_size, self.pred_len,-1,7))}
From 57dc7c222043b87d7fe621ba571d3cd1db2e6ad6 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 7 Feb 2025 20:59:50 +0800
Subject: [PATCH 05/49] Update __init__.py
---
ppsci/arch/__init__.py | 2 ++
1 file changed, 2 insertions(+)
diff --git a/ppsci/arch/__init__.py b/ppsci/arch/__init__.py
index 19f6e81a9e..b770ad0f36 100644
--- a/ppsci/arch/__init__.py
+++ b/ppsci/arch/__init__.py
@@ -61,6 +61,7 @@
from ppsci.utils import logger # isort:skip
from ppsci.arch.regdgcnn import RegDGCNN # isort:skip
from ppsci.arch.ifm_mlp import IFMMLP # isort:skip
+from ppsci.arch.stafnet import STAFNet # isort:skip
__all__ = [
"MoFlowNet",
@@ -111,6 +112,7 @@
"VelocityGenerator",
"RegDGCNN",
"IFMMLP",
+ "STAFNet",
]
From ab1ae03ca06a344a128a1e164e9927fe317b16b4 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Tue, 11 Feb 2025 23:17:56 +0800
Subject: [PATCH 06/49] Update demo.py
---
examples/demo/demo.py | 67 +++++++++++++++++++++++++++++--------------
1 file changed, 45 insertions(+), 22 deletions(-)
diff --git a/examples/demo/demo.py b/examples/demo/demo.py
index 8dd5eeb052..5ced50ca79 100644
--- a/examples/demo/demo.py
+++ b/examples/demo/demo.py
@@ -1,5 +1,3 @@
-
-
import ppsci
from ppsci.utils import logger
from omegaconf import DictConfig
@@ -17,9 +15,8 @@ def train(cfg: DictConfig):
"file_path": cfg.DATASET.data_dir,
"input_keys": cfg.MODEL.input_keys,
"label_keys": cfg.MODEL.output_keys,
- # "weight_dict": {"eta": 100},
- "seq_len": cfg.MODEL.configs.seq_len,
- "pred_len": cfg.MODEL.configs.pred_len,
+ "seq_len": cfg.MODEL.seq_len,
+ "pred_len": cfg.MODEL.pred_len,
},
"batch_size": cfg.TRAIN.batch_size,
@@ -33,12 +30,11 @@ def train(cfg: DictConfig):
eval_dataloader_cfg= {
"dataset": {
"name": "STAFNetDataset",
- "file_path": cfg.STAFNet_DATA_PATH,
+ "file_path": cfg.EVAL.eval_data_path,
"input_keys": cfg.MODEL.input_keys,
"label_keys": cfg.MODEL.output_keys,
- # "weight_dict": {"eta": 100},
- "seq_len": cfg.MODEL.configs.seq_len,
- "pred_len": cfg.MODEL.configs.pred_len,
+ "seq_len": cfg.MODEL.seq_len,
+ "pred_len": cfg.MODEL.pred_len,
},
"batch_size": cfg.TRAIN.batch_size,
"sampler": {
@@ -53,7 +49,6 @@ def train(cfg: DictConfig):
train_dataloader_cfg,
loss=ppsci.loss.MSELoss("mean"),
name="STAFNet_Sup",
- # output_expr={"pred": lambda out: out["pred"]},
)
constraint = {sup_constraint.name: sup_constraint}
sup_validator = ppsci.validate.SupervisedValidator(
@@ -63,9 +58,7 @@ def train(cfg: DictConfig):
name="Sup_Validator",
)
validator = {sup_validator.name: sup_validator}
-
- # lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
-
+
# set optimizer
lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
LEARNING_RATE = cfg.TRAIN.lr_scheduler.learning_rate
@@ -73,8 +66,6 @@ def train(cfg: DictConfig):
output_dir = cfg.output_dir
ITERS_PER_EPOCH = len(sup_constraint.data_loader)
-
-
# initialize solver
solver = ppsci.solver.Solver(
model,
@@ -94,8 +85,6 @@ def train(cfg: DictConfig):
# train model
solver.train()
- return
-
def evaluate(cfg: DictConfig):
"""
Validate after training an epoch
@@ -103,7 +92,44 @@ def evaluate(cfg: DictConfig):
:param epoch: Integer, current training epoch.
:return: A log that contains information about validation
"""
- pass
+ model = ppsci.arch.STAFNet(**cfg.MODEL)
+ eval_dataloader_cfg= {
+ "dataset": {
+ "name": "STAFNetDataset",
+ "file_path": cfg.EVAL.eval_data_path,
+ "input_keys": cfg.MODEL.input_keys,
+ "label_keys": cfg.MODEL.output_keys,
+ "seq_len": cfg.MODEL.seq_len,
+ "pred_len": cfg.MODEL.pred_len,
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "collate_fn": gat_lstmcollate_fn,
+ }
+ sup_validator = ppsci.validate.SupervisedValidator(
+ eval_dataloader_cfg,
+ loss=ppsci.loss.MSELoss("mean"),
+ metric={"MSE": ppsci.metric.MSE()},
+ name="Sup_Validator",
+ )
+ validator = {sup_validator.name: sup_validator}
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ validator=validator,
+ cfg=cfg,
+ pretrained_model_path=cfg.EVAL.pretrained_model_path,
+ compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,
+ eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
+ )
+
+ # evaluate model
+ solver.eval()
@hydra.main(version_base=None, config_path="./conf", config_name="stafnet.yaml")
@@ -115,9 +141,6 @@ def main(cfg: DictConfig):
else:
raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
-
-
-
if __name__ == "__main__":
# set random seed for reproducibility
ppsci.utils.misc.set_random_seed(42)
@@ -127,4 +150,4 @@ def main(cfg: DictConfig):
logger.init_logger("ppsci", f"{OUTPUT_DIR}/train.log", "info")
multiprocessing.set_start_method("spawn")
- main()
\ No newline at end of file
+ main()
From d257a490987c22ff55eea0c78a4e0ebf8927ed16 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Tue, 11 Feb 2025 23:18:14 +0800
Subject: [PATCH 07/49] Update stafnet.yaml
---
examples/demo/conf/stafnet.yaml | 155 +++++++++++---------------------
1 file changed, 52 insertions(+), 103 deletions(-)
diff --git a/examples/demo/conf/stafnet.yaml b/examples/demo/conf/stafnet.yaml
index 238bcc3870..0de02e49b1 100644
--- a/examples/demo/conf/stafnet.yaml
+++ b/examples/demo/conf/stafnet.yaml
@@ -1,3 +1,12 @@
+defaults:
+ - ppsci_default
+ - TRAIN: train_default
+ - TRAIN/ema: ema_default
+ - TRAIN/swa: swa_default
+ - EVAL: eval_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
hydra:
run:
# dynamic output directory according to running time and override name
@@ -5,15 +14,6 @@ hydra:
job:
name: ${mode} # name of logfile
chdir: false # keep current working directory unchanged
- config:
- override_dirname:
- exclude_keys:
- - TRAIN.checkpoint_path
- - TRAIN.pretrained_model_path
- - EVAL.pretrained_model_path
- - mode
- - output_dir
- - log_freq
callbacks:
init_callback:
_target_: ppsci.utils.callbacks.InitCallback
@@ -28,109 +28,58 @@ seed: 42
output_dir: ${hydra:run.dir}
log_freq: 20
# dataset setting
-STAFNet_DATA_PATH: "/data6/home/yinhang2021/workspace/SATFNet/data/2020-2023_new/train_data.pkl" #
+STAFNet_DATA_PATH: "/data6/home/yinhang2021/dataset/chongqing_1921/train_data.pkl" #
DATASET:
label_keys: ["label"]
- data_dir: "/data6/home/yinhang2021/workspace/SATFNet/data/2020-2023_new/train_data.pkl"
- STAFNet_DATA_args: {
- "data_dir": "/data6/home/yinhang2021/workspace/SATFNet/data/2020-2023_new/train_data.pkl",
- "batch_size": 1,
- "shuffle": True,
- "num_workers": 0,
- "training": True
- }
+ data_dir: "/data6/home/yinhang2021/dataset/chongqing_1921/train_data.pkl"
-
-# "data_dir": "data/2020-2023_new/train_data.pkl",
-# "batch_size": 32,
-# "shuffle": True,
-# "num_workers": 0,
-# "training": True
-# model settings
-# MODEL: #
-
-
MODEL:
input_keys: ["aq_train_data","mete_train_data",]
output_keys: ["label"]
- configs:
- output_attention: True
- seq_len: 72
- label_len: 24
- pred_len: 48
- aq_gat_node_features: 7
- aq_gat_node_num: 35
- mete_gat_node_features: 7
- mete_gat_node_num: 18
- gat_hidden_dim: 32
- gat_edge_dim: 3
- gat_embed_dim: 32
- e_layers: 1
- enc_in: 7
- dec_in: 7
- c_out: 7
- d_model: 16
- embed: "fixed"
- freq: "t"
- dropout: 0.05
- factor: 3
- n_heads: 4
- d_ff: 32
- num_kernels: 6
- top_k: 4
- # configs: {
- # "task_name": "forecast",
- # "output_attention": False,
- # "seq_len": 72,
- # "label_len": 24,
- # "pred_len": 48,
-
- # "aq_gat_node_features" : 7,
- # "aq_gat_node_num": 35,
-
- # "mete_gat_node_features" : 7,
- # "mete_gat_node_num": 18,
-
- # "gat_hidden_dim": 32,
- # "gat_edge_dim": 3,
- # "gat_embed_dim": 32,
-
- # "e_layers": 1,
- # "enc_in": 7,
- # "dec_in": 7,
- # "c_out": 7,
- # "d_model": 16 ,
- # "embed": "fixed",
- # "freq": "t",
- # "dropout": 0.05,
- # "factor": 3,
- # "n_heads": 4,
-
- # "d_ff": 32 ,
- # "num_kernels": 6,
- # "top_k": 4
- # }
-
+ output_attention: True
+ seq_len: 72
+ pred_len: 48
+ aq_gat_node_features: 7
+ aq_gat_node_num: 35
+ mete_gat_node_features: 7
+ mete_gat_node_num: 18
+ gat_hidden_dim: 32
+ gat_edge_dim: 3
+ e_layers: 1
+ enc_in: 7
+ dec_in: 7
+ c_out: 7
+ d_model: 16
+ embed: "fixed"
+ freq: "t"
+ dropout: 0.05
+ factor: 3
+ n_heads: 4
+ d_ff: 32
+ num_kernels: 6
+ top_k: 4
+
# training settings
-TRAIN: #
- epochs: 100 #
- iters_per_epoch: 400 #
- save_freq: 10 #
- eval_during_train: true #
- eval_freq: 1000 #
- batch_size: 1 #
- lr_scheduler: #
- epochs: ${TRAIN.epochs} #
- iters_per_epoch: ${TRAIN.iters_per_epoch} #
- learning_rate: 0.001 #
- step_size: 10 #
- gamma: 0.9 #
- pretrained_model_path: null #
- checkpoint_path: null #
+TRAIN:
+ epochs: 100
+ iters_per_epoch: 400
+ save_freq: 10
+ eval_during_train: true
+ eval_freq: 10
+ batch_size: 1
+ lr_scheduler:
+ epochs: ${TRAIN.epochs}
+ iters_per_epoch: ${TRAIN.iters_per_epoch}
+ learning_rate: 0.001
+ step_size: 10
+ gamma: 0.9
+ pretrained_model_path: null
+ checkpoint_path: null
EVAL:
- pretrained_model_path: null #
+ eval_data_path: "/data6/home/yinhang2021/dataset/chongqing_1921/val_data.pkl"
+ pretrained_model_path: null
compute_metric_by_batch: false
eval_with_no_grad: true
- batch_size: 1
\ No newline at end of file
+ batch_size: 1
From b43c7f53e02e837e6f928fdc07827e922c47bcfe Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Tue, 11 Feb 2025 23:19:10 +0800
Subject: [PATCH 08/49] Update stafnet.py
---
ppsci/arch/stafnet.py | 205 +++++++++++++++++++++++++++++++-----------
1 file changed, 151 insertions(+), 54 deletions(-)
diff --git a/ppsci/arch/stafnet.py b/ppsci/arch/stafnet.py
index 583f2ceba3..a5b3e00371 100644
--- a/ppsci/arch/stafnet.py
+++ b/ppsci/arch/stafnet.py
@@ -1,13 +1,9 @@
import paddle
import paddle.nn as nn
-import os
import numpy as np
import math
from math import sqrt
-# from Embed import DataEmbedding
-import argparse
from ppsci.arch import base
-from tqdm import tqdm
from pgl.nn.conv import GATv2Conv
from typing import TYPE_CHECKING
from typing import Dict
@@ -187,16 +183,39 @@ def FFT_for_Period(x, k=2):
class TimesBlock(paddle.nn.Layer):
-
- def __init__(self, configs):
+ """Times Block for Spatio-Temporal Attention Fusion Network.
+
+ Args:
+ seq_len (int): Sequence length.
+ pred_len (int): Prediction length.
+ top_k (int): Number of top frequencies to consider.
+ num_kernels (int): Number of kernels in Inception block.
+ d_model (int): Dimension of the model.
+ d_ff (int): Dimension of feedforward network.
+
+ Examples:
+ >>> from ppsci.arch.stafnet import TimesBlock
+ >>> block = TimesBlock(seq_len=72, pred_len=48, top_k=2, num_kernels=32, d_model=512, d_ff=2048)
+ >>> x = paddle.rand([32, 72, 512]) # [batch_size, seq_len, d_model]
+ >>> output = block(x)
+ >>> print(output.shape)
+ [32, 120, 512]
+ """
+ def __init__(self,
+ seq_len: int,
+ pred_len: int,
+ top_k: int,
+ num_kernels: int,
+ d_model: int,
+ d_ff: int, ):
super(TimesBlock, self).__init__()
- self.seq_len = configs.seq_len
- self.pred_len = configs.pred_len
- self.k = configs.top_k
- self.conv = paddle.nn.Sequential(Inception_Block_V1(configs.d_model,
- configs.d_ff, num_kernels=configs.num_kernels), paddle.nn.GELU(
- ), Inception_Block_V1(configs.d_ff, configs.d_model,
- num_kernels=configs.num_kernels))
+ self.seq_len = seq_len
+ self.pred_len = pred_len
+ self.k = top_k
+ self.conv = paddle.nn.Sequential(Inception_Block_V1(d_model,
+ d_ff, num_kernels=num_kernels), paddle.nn.GELU(
+ ), Inception_Block_V1(d_ff, d_model,
+ num_kernels=num_kernels))
def forward(self, x):
B, T, N = tuple(x.shape)
@@ -220,9 +239,6 @@ def forward(self, x):
res = paddle.stack(x=res, axis=-1)
period_weight_raw = period_weight
period_weight = paddle.nn.functional.softmax(x=period_weight, axis=1)
- # print(period_weight.unsqueeze(axis=1).unsqueeze(axis=1).shape)
- # period_weight = period_weight.unsqueeze(axis=1).unsqueeze(axis=1
- # ).repeat(1, T, N, 1)
period_weight = paddle.tile(period_weight.unsqueeze(axis=1).unsqueeze(axis=1
), (1, T, N, 1))
res = paddle.sum(x=res * period_weight, axis=-1)
@@ -435,53 +451,134 @@ def forward(self,graph, feature, ):
class STAFNet(base.Arch):
-
+ """Spatio-Temporal Attention Fusion Network (STAFNet).
+
+ STAFNet is a neural network architecture for spatio-temporal data prediction, combining attention mechanisms and convolutional neural networks to capture spatio-temporal dependencies.
+
+ Args:
+ input_keys (Tuple[str, ...]): Keys of input variables.
+ output_keys (Tuple[str, ...]): Keys of output variables.
+ seq_len (int): Sequence length.
+ pred_len (int): Prediction length.
+ aq_gat_node_num (int): Number of nodes in the air quality GAT.
+ aq_gat_node_features (int): Number of features for each node in the air quality GAT.
+ mete_gat_node_num (int): Number of nodes in the meteorological GAT.
+ mete_gat_node_features (int): Number of features for each node in the meteorological GAT.
+ gat_hidden_dim (int): Hidden dimension of the GAT.
+ gat_edge_dim (int): Edge dimension of the GAT.
+ d_model (int): Dimension of the model.
+ n_heads (int): Number of attention heads.
+ e_layers (int): Number of encoder layers.
+ enc_in (int): Encoder input dimension.
+ dec_in (int): Decoder input dimension.
+ freq (str): Frequency for positional encoding.
+ embed (str): Embedding type.
+ d_ff (int): Dimension of feedforward network.
+ top_k (int): Number of top frequencies to consider.
+ num_kernels (int): Number of kernels in Inception block.
+ dropout (float): Dropout rate.
+ output_attention (bool): Whether to output attention.
+ factor (int): Factor for attention mechanism.
+ c_out (int): Output channels.
+
+ Examples:
+ >>> from ppsci.arch import STAFNet
+ >>> model = STAFNet(
+ ... input_keys=('x', 'y', 'z'),
+ ... output_keys=('u', 'v'),
+ ... seq_len=72,
+ ... pred_len=48,
+ ... aq_gat_node_num=10,
+ ... aq_gat_node_features=16,
+ ... mete_gat_node_num=10,
+ ... mete_gat_node_features=16,
+ ... gat_hidden_dim=32,
+ ... gat_edge_dim=8,
+ ... d_model=512,
+ ... n_heads=8,
+ ... e_layers=3,
+ ... enc_in=7,
+ ... dec_in=7,
+ ... freq='h',
+ ... embed='fixed',
+ ... d_ff=2048,
+ ... top_k=5,
+ ... num_kernels=32,
+ ... dropout=0.1,
+ ... output_attention=False,
+ ... factor=5,
+ ... c_out=7,
+ ... )
+ >>> input_dict = {"x": paddle.rand([32, 72, 7]),
+ ... "y": paddle.rand([32, 72, 7]),
+ ... "z": paddle.rand([32, 72, 7])}
+ >>> output_dict = model(input_dict)
+ >>> print(output_dict["u"].shape)
+ [32, 48, 7]
+ >>> print(output_dict["v"].shape)
+ [32, 48, 7]
+ """
+
def __init__(
- self,
+ self,
input_keys: Tuple[str, ...],
output_keys: Tuple[str, ...],
- configs, **kwargs):
+ seq_len: int,
+ pred_len: int,
+ aq_gat_node_num: int,
+ aq_gat_node_features: int,
+ mete_gat_node_num: int,
+ mete_gat_node_features: int,
+ gat_hidden_dim: int,
+ gat_edge_dim: int,
+ d_model: int,
+ n_heads: int,
+ e_layers: int,
+ enc_in: int,
+ dec_in: int,
+ freq: str,
+ embed: str,
+ d_ff: int,
+ top_k: int,
+ num_kernels: int,
+ dropout: float,
+ output_attention: bool,
+ factor: int,
+ c_out: int,
+ ):
super(STAFNet, self).__init__()
- # configs = argparse.Namespace(**configs)
self.input_keys = input_keys
self.output_keys = output_keys
self.device = str('cuda').replace('cuda', 'gpu')
- self.configs = configs
- if hasattr(configs, 'output_attention'):
- self.output_attention = configs.output_attention
- else:
- self.output_attention = False
- self.seq_len = configs.seq_len
- self.label_len = configs.label_len
- self.pred_len = configs.pred_len
- self.dec_in = configs.dec_in
- self.gat_embed_dim = configs.enc_in
- self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model,
- configs.embed, configs.freq, configs.dropout)
- self.aq_gat_node_num = configs.aq_gat_node_num
- self.aq_gat_node_features = configs.aq_gat_node_features
- self.aq_GAT = GAT_Encoder(configs.aq_gat_node_features, configs.
- gat_hidden_dim, configs.gat_edge_dim, self.gat_embed_dim,
- configs.dropout).to(self.device)
- self.mete_gat_node_num = configs.mete_gat_node_num
- self.mete_gat_node_features = configs.mete_gat_node_features
- self.mete_GAT = GAT_Encoder(configs.mete_gat_node_features, configs
- .gat_hidden_dim, configs.gat_edge_dim, self.gat_embed_dim,
- configs.dropout).to(self.device)
- self.pos_fc = paddle.nn.Linear(in_features=2, out_features=configs.
- gat_embed_dim, bias_attr=True)
- self.fusion_Attention = AttentionLayer(ProbAttention(False, configs
- .factor, attention_dropout=configs.dropout, output_attention=
- self.output_attention), configs.gat_embed_dim, configs.n_heads)
- self.model = paddle.nn.LayerList(sublayers=[TimesBlock(configs) for
- _ in range(configs.e_layers)])
- self.layer = configs.e_layers
- self.layer_norm = paddle.nn.LayerNorm(normalized_shape=configs.d_model)
+ self.output_attention = output_attention
+ self.seq_len = seq_len
+ self.pred_len = pred_len
+ self.dec_in = dec_in
+ self.gat_embed_dim = enc_in
+ self.enc_embedding = DataEmbedding(enc_in, d_model,
+ embed, freq, dropout)
+ self.aq_gat_node_num = aq_gat_node_num
+ self.aq_gat_node_features = aq_gat_node_features
+ self.aq_GAT = GAT_Encoder(aq_gat_node_features,
+ gat_hidden_dim, gat_edge_dim, self.gat_embed_dim,
+ dropout).to(self.device)
+ self.mete_gat_node_num = mete_gat_node_num
+ self.mete_gat_node_features = mete_gat_node_features
+ self.mete_GAT = GAT_Encoder(mete_gat_node_features, gat_hidden_dim, gat_edge_dim, self.gat_embed_dim,
+ dropout).to(self.device)
+ self.pos_fc = paddle.nn.Linear(in_features=2, out_features=
+ self.gat_embed_dim, bias_attr=True)
+ self.fusion_Attention = AttentionLayer(ProbAttention(False, factor, attention_dropout=dropout, output_attention=
+ self.output_attention), self.gat_embed_dim, n_heads)
+ self.model = paddle.nn.LayerList(sublayers=[TimesBlock( seq_len, pred_len, top_k, num_kernels,d_model,d_ff) for
+ _ in range(e_layers)])
+ self.layer = e_layers
+ self.layer_norm = paddle.nn.LayerNorm(normalized_shape=d_model)
self.predict_linear = paddle.nn.Linear(in_features=self.seq_len,
out_features=self.pred_len + self.seq_len)
- self.projection = paddle.nn.Linear(in_features=configs.d_model,
- out_features=configs.c_out, bias_attr=True)
-
+ self.projection = paddle.nn.Linear(in_features=d_model,
+ out_features=c_out, bias_attr=True)
+ self.output_attention = output_attention
def aq_gat(self, G):
# x = G.x[:, -self.aq_gat_node_features:].to(self.device)
From 757477a15f0f2d4b00d24abfe7ccf72cff4c6506 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Tue, 11 Feb 2025 23:23:43 +0800
Subject: [PATCH 09/49] Update stafnet_dataset.py
---
ppsci/data/dataset/stafnet_dataset.py | 8 +-------
1 file changed, 1 insertion(+), 7 deletions(-)
diff --git a/ppsci/data/dataset/stafnet_dataset.py b/ppsci/data/dataset/stafnet_dataset.py
index 5fed301d7f..94cf6e2e7a 100644
--- a/ppsci/data/dataset/stafnet_dataset.py
+++ b/ppsci/data/dataset/stafnet_dataset.py
@@ -88,12 +88,6 @@ def __init__(self,
seq_len: int = 72,
pred_len: int = 48,
use_edge_attr: bool = True,):
- """
- root: 数据集保存的地方。
- 会产生两个文件夹:
- raw_dir(downloaded dataset) 和 processed_dir(processed data)。
- """
-
self.file_path = file_path
self.input_keys = input_keys
self.label_keys = label_keys
@@ -184,4 +178,4 @@ def find_nearest_point(self, A, B):
for a in A:
distances = [np.linalg.norm(a - b) for b in B]
nearest_indices.append(np.argmin(distances))
- return nearest_indices
\ No newline at end of file
+ return nearest_indices
From 711cd36d97c483f688b9c62e270d57596c988357 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 14 Feb 2025 21:48:35 +0800
Subject: [PATCH 10/49] Update stafnet.yaml
---
examples/demo/conf/stafnet.yaml | 9 ++++-----
1 file changed, 4 insertions(+), 5 deletions(-)
diff --git a/examples/demo/conf/stafnet.yaml b/examples/demo/conf/stafnet.yaml
index 0de02e49b1..63f649ccaf 100644
--- a/examples/demo/conf/stafnet.yaml
+++ b/examples/demo/conf/stafnet.yaml
@@ -28,15 +28,14 @@ seed: 42
output_dir: ${hydra:run.dir}
log_freq: 20
# dataset setting
-STAFNet_DATA_PATH: "/data6/home/yinhang2021/dataset/chongqing_1921/train_data.pkl" #
DATASET:
label_keys: ["label"]
- data_dir: "/data6/home/yinhang2021/dataset/chongqing_1921/train_data.pkl"
+ data_dir: ./dataset/train_data.pkl
MODEL:
- input_keys: ["aq_train_data","mete_train_data",]
- output_keys: ["label"]
+ input_keys: [aq_train_data, mete_train_data]
+ output_keys: [label]
output_attention: True
seq_len: 72
pred_len: 48
@@ -78,7 +77,7 @@ TRAIN:
checkpoint_path: null
EVAL:
- eval_data_path: "/data6/home/yinhang2021/dataset/chongqing_1921/val_data.pkl"
+ eval_data_path: ./dataset/val_data.pkl
pretrained_model_path: null
compute_metric_by_batch: false
eval_with_no_grad: true
From a79ad1d6e3439f859f8ed4cf9076008c56e66604 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 14 Feb 2025 22:16:05 +0800
Subject: [PATCH 11/49] Update demo.py
---
examples/demo/demo.py | 39 ++-------------------------------------
1 file changed, 2 insertions(+), 37 deletions(-)
diff --git a/examples/demo/demo.py b/examples/demo/demo.py
index 5ced50ca79..e079fb09bc 100644
--- a/examples/demo/demo.py
+++ b/examples/demo/demo.py
@@ -17,24 +17,6 @@ def train(cfg: DictConfig):
"label_keys": cfg.MODEL.output_keys,
"seq_len": cfg.MODEL.seq_len,
"pred_len": cfg.MODEL.pred_len,
-
- },
- "batch_size": cfg.TRAIN.batch_size,
- "sampler": {
- "name": "BatchSampler",
- "drop_last": False,
- "shuffle": True,
- },
- "collate_fn": gat_lstmcollate_fn,
- }
- eval_dataloader_cfg= {
- "dataset": {
- "name": "STAFNetDataset",
- "file_path": cfg.EVAL.eval_data_path,
- "input_keys": cfg.MODEL.input_keys,
- "label_keys": cfg.MODEL.output_keys,
- "seq_len": cfg.MODEL.seq_len,
- "pred_len": cfg.MODEL.pred_len,
},
"batch_size": cfg.TRAIN.batch_size,
"sampler": {
@@ -51,18 +33,10 @@ def train(cfg: DictConfig):
name="STAFNet_Sup",
)
constraint = {sup_constraint.name: sup_constraint}
- sup_validator = ppsci.validate.SupervisedValidator(
- eval_dataloader_cfg,
- loss=ppsci.loss.MSELoss("mean"),
- metric={"MSE": ppsci.metric.MSE()},
- name="Sup_Validator",
- )
- validator = {sup_validator.name: sup_validator}
- # set optimizer
+ # set optimizer
lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
- LEARNING_RATE = cfg.TRAIN.lr_scheduler.learning_rate
- optimizer = ppsci.optimizer.Adam(LEARNING_RATE)(model)
+ optimizer = ppsci.optimizer.Adam(lr_scheduler)(model)
output_dir = cfg.output_dir
ITERS_PER_EPOCH = len(sup_constraint.data_loader)
@@ -131,7 +105,6 @@ def evaluate(cfg: DictConfig):
# evaluate model
solver.eval()
-
@hydra.main(version_base=None, config_path="./conf", config_name="stafnet.yaml")
def main(cfg: DictConfig):
if cfg.mode == "train":
@@ -142,12 +115,4 @@ def main(cfg: DictConfig):
raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
if __name__ == "__main__":
- # set random seed for reproducibility
- ppsci.utils.misc.set_random_seed(42)
- # set output directory
- OUTPUT_DIR = "./output_example"
- # initialize logger
- logger.init_logger("ppsci", f"{OUTPUT_DIR}/train.log", "info")
- multiprocessing.set_start_method("spawn")
-
main()
From af964348bd8ecc8377d8c6e7634f1dd6ff0a1875 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 14 Feb 2025 22:18:05 +0800
Subject: [PATCH 12/49] Update stafnet.yaml
---
examples/demo/conf/stafnet.yaml | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/examples/demo/conf/stafnet.yaml b/examples/demo/conf/stafnet.yaml
index 63f649ccaf..2ed4965865 100644
--- a/examples/demo/conf/stafnet.yaml
+++ b/examples/demo/conf/stafnet.yaml
@@ -29,7 +29,7 @@ output_dir: ${hydra:run.dir}
log_freq: 20
# dataset setting
DATASET:
- label_keys: ["label"]
+ label_keys: [label]
data_dir: ./dataset/train_data.pkl
From 86a9c0bb16497c2f924f86dd09df50a463004283 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 14 Feb 2025 22:19:16 +0800
Subject: [PATCH 13/49] Update demo.py
---
examples/demo/demo.py | 6 ------
1 file changed, 6 deletions(-)
diff --git a/examples/demo/demo.py b/examples/demo/demo.py
index e079fb09bc..eefff0fbbd 100644
--- a/examples/demo/demo.py
+++ b/examples/demo/demo.py
@@ -60,12 +60,6 @@ def train(cfg: DictConfig):
solver.train()
def evaluate(cfg: DictConfig):
- """
- Validate after training an epoch
-
- :param epoch: Integer, current training epoch.
- :return: A log that contains information about validation
- """
model = ppsci.arch.STAFNet(**cfg.MODEL)
eval_dataloader_cfg= {
"dataset": {
From 792796a956dbc9bcfe3ca6d664af3cac93c129be Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Thu, 5 Jun 2025 21:47:00 +0800
Subject: [PATCH 14/49] Delete examples/demo directory
---
examples/demo/conf/stafnet.yaml | 84 ------------------------
examples/demo/demo.py | 112 --------------------------------
2 files changed, 196 deletions(-)
delete mode 100644 examples/demo/conf/stafnet.yaml
delete mode 100644 examples/demo/demo.py
diff --git a/examples/demo/conf/stafnet.yaml b/examples/demo/conf/stafnet.yaml
deleted file mode 100644
index 2ed4965865..0000000000
--- a/examples/demo/conf/stafnet.yaml
+++ /dev/null
@@ -1,84 +0,0 @@
-defaults:
- - ppsci_default
- - TRAIN: train_default
- - TRAIN/ema: ema_default
- - TRAIN/swa: swa_default
- - EVAL: eval_default
- - INFER: infer_default
- - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
- - _self_
-hydra:
- run:
- # dynamic output directory according to running time and override name
- dir: outputs_chip_heat/${now:%Y-%m-%d}/${now:%H-%M-%S}/${hydra.job.override_dirname}
- job:
- name: ${mode} # name of logfile
- chdir: false # keep current working directory unchanged
- callbacks:
- init_callback:
- _target_: ppsci.utils.callbacks.InitCallback
- sweep:
- # output directory for multirun
- dir: ${hydra.run.dir}
- subdir: ./
-
-# general settings
-mode: train # running mode: train/eval
-seed: 42
-output_dir: ${hydra:run.dir}
-log_freq: 20
-# dataset setting
-DATASET:
- label_keys: [label]
- data_dir: ./dataset/train_data.pkl
-
-
-MODEL:
- input_keys: [aq_train_data, mete_train_data]
- output_keys: [label]
- output_attention: True
- seq_len: 72
- pred_len: 48
- aq_gat_node_features: 7
- aq_gat_node_num: 35
- mete_gat_node_features: 7
- mete_gat_node_num: 18
- gat_hidden_dim: 32
- gat_edge_dim: 3
- e_layers: 1
- enc_in: 7
- dec_in: 7
- c_out: 7
- d_model: 16
- embed: "fixed"
- freq: "t"
- dropout: 0.05
- factor: 3
- n_heads: 4
- d_ff: 32
- num_kernels: 6
- top_k: 4
-
-# training settings
-TRAIN:
- epochs: 100
- iters_per_epoch: 400
- save_freq: 10
- eval_during_train: true
- eval_freq: 10
- batch_size: 1
- lr_scheduler:
- epochs: ${TRAIN.epochs}
- iters_per_epoch: ${TRAIN.iters_per_epoch}
- learning_rate: 0.001
- step_size: 10
- gamma: 0.9
- pretrained_model_path: null
- checkpoint_path: null
-
-EVAL:
- eval_data_path: ./dataset/val_data.pkl
- pretrained_model_path: null
- compute_metric_by_batch: false
- eval_with_no_grad: true
- batch_size: 1
diff --git a/examples/demo/demo.py b/examples/demo/demo.py
deleted file mode 100644
index eefff0fbbd..0000000000
--- a/examples/demo/demo.py
+++ /dev/null
@@ -1,112 +0,0 @@
-import ppsci
-from ppsci.utils import logger
-from omegaconf import DictConfig
-import hydra
-import paddle
-from ppsci.data.dataset.stafnet_dataset import gat_lstmcollate_fn
-import multiprocessing
-
-def train(cfg: DictConfig):
- # set model
- model = ppsci.arch.STAFNet(**cfg.MODEL)
- train_dataloader_cfg = {
- "dataset": {
- "name": "STAFNetDataset",
- "file_path": cfg.DATASET.data_dir,
- "input_keys": cfg.MODEL.input_keys,
- "label_keys": cfg.MODEL.output_keys,
- "seq_len": cfg.MODEL.seq_len,
- "pred_len": cfg.MODEL.pred_len,
- },
- "batch_size": cfg.TRAIN.batch_size,
- "sampler": {
- "name": "BatchSampler",
- "drop_last": False,
- "shuffle": True,
- },
- "collate_fn": gat_lstmcollate_fn,
- }
-
- sup_constraint = ppsci.constraint.SupervisedConstraint(
- train_dataloader_cfg,
- loss=ppsci.loss.MSELoss("mean"),
- name="STAFNet_Sup",
- )
- constraint = {sup_constraint.name: sup_constraint}
-
- # set optimizer
- lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
- optimizer = ppsci.optimizer.Adam(lr_scheduler)(model)
- output_dir = cfg.output_dir
- ITERS_PER_EPOCH = len(sup_constraint.data_loader)
-
- # initialize solver
- solver = ppsci.solver.Solver(
- model,
- constraint,
- output_dir,
- optimizer,
- lr_scheduler,
- cfg.TRAIN.epochs,
- ITERS_PER_EPOCH,
- eval_during_train=cfg.TRAIN.eval_during_train,
- seed=cfg.seed,
- validator=validator,
- compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,
- eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
- )
-
- # train model
- solver.train()
-
-def evaluate(cfg: DictConfig):
- model = ppsci.arch.STAFNet(**cfg.MODEL)
- eval_dataloader_cfg= {
- "dataset": {
- "name": "STAFNetDataset",
- "file_path": cfg.EVAL.eval_data_path,
- "input_keys": cfg.MODEL.input_keys,
- "label_keys": cfg.MODEL.output_keys,
- "seq_len": cfg.MODEL.seq_len,
- "pred_len": cfg.MODEL.pred_len,
- },
- "batch_size": cfg.TRAIN.batch_size,
- "sampler": {
- "name": "BatchSampler",
- "drop_last": False,
- "shuffle": True,
- },
- "collate_fn": gat_lstmcollate_fn,
- }
- sup_validator = ppsci.validate.SupervisedValidator(
- eval_dataloader_cfg,
- loss=ppsci.loss.MSELoss("mean"),
- metric={"MSE": ppsci.metric.MSE()},
- name="Sup_Validator",
- )
- validator = {sup_validator.name: sup_validator}
-
- # initialize solver
- solver = ppsci.solver.Solver(
- model,
- validator=validator,
- cfg=cfg,
- pretrained_model_path=cfg.EVAL.pretrained_model_path,
- compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,
- eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
- )
-
- # evaluate model
- solver.eval()
-
-@hydra.main(version_base=None, config_path="./conf", config_name="stafnet.yaml")
-def main(cfg: DictConfig):
- if cfg.mode == "train":
- train(cfg)
- elif cfg.mode == "eval":
- evaluate(cfg)
- else:
- raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
-
-if __name__ == "__main__":
- main()
From db2f09362eeb1c0db7981b7da6b199c9e09a9859 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Thu, 5 Jun 2025 21:47:25 +0800
Subject: [PATCH 15/49] Add files via upload
---
examples/stafnet/conf/stafnet.yaml | 85 ++++++++++++++++++
examples/stafnet/stafnet.py | 138 +++++++++++++++++++++++++++++
2 files changed, 223 insertions(+)
create mode 100644 examples/stafnet/conf/stafnet.yaml
create mode 100644 examples/stafnet/stafnet.py
diff --git a/examples/stafnet/conf/stafnet.yaml b/examples/stafnet/conf/stafnet.yaml
new file mode 100644
index 0000000000..39db3eb235
--- /dev/null
+++ b/examples/stafnet/conf/stafnet.yaml
@@ -0,0 +1,85 @@
+defaults:
+ - ppsci_default
+ - TRAIN: train_default
+ - TRAIN/ema: ema_default
+ - TRAIN/swa: swa_default
+ - EVAL: eval_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: outputs_stafnet/${now:%Y-%m-%d}/${now:%H-%M-%S}/${hydra.job.override_dirname}
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: train # running mode: train/eval
+seed: 42
+output_dir: ${hydra:run.dir}
+log_freq: 20
+# dataset setting
+DATASET:
+ label_keys: [label]
+ data_dir: ./dataset/train_data.pkl
+
+
+MODEL:
+ input_keys: [aq_train_data, mete_train_data]
+ output_keys: [label]
+ output_attention: True
+ seq_len: 72
+ pred_len: 48
+ aq_gat_node_features: 7
+ aq_gat_node_num: 35
+ mete_gat_node_features: 7
+ mete_gat_node_num: 18
+ gat_hidden_dim: 32
+ gat_edge_dim: 3
+ e_layers: 2
+ enc_in: 7
+ dec_in: 7
+ c_out: 7
+ d_model: 32
+ embed: "fixed"
+ freq: "t"
+ dropout: 0.05
+ factor: 3
+ n_heads: 4
+ d_ff: 64
+ num_kernels: 6
+ top_k: 4
+
+# training settings
+TRAIN:
+ epochs: 100
+ iters_per_epoch: 400
+ save_freq: 10
+ eval_during_train: true
+ eval_freq: 10
+ batch_size: 32
+ learning_rate: 0.0001
+ lr_scheduler:
+ epochs: ${TRAIN.epochs}
+ iters_per_epoch: ${TRAIN.iters_per_epoch}
+ learning_rate: 0.0005
+ step_size: 20
+ gamma: 0.95
+ pretrained_model_path: null
+ checkpoint_path: null
+
+EVAL:
+ eval_data_path: ./dataset/new_val_data.pkl
+ pretrained_model_path: null
+ compute_metric_by_batch: false
+ eval_with_no_grad: true
+ batch_size: 32
\ No newline at end of file
diff --git a/examples/stafnet/stafnet.py b/examples/stafnet/stafnet.py
new file mode 100644
index 0000000000..c7fd72f2d4
--- /dev/null
+++ b/examples/stafnet/stafnet.py
@@ -0,0 +1,138 @@
+import ppsci
+from ppsci.utils import logger
+from omegaconf import DictConfig
+import hydra
+import paddle
+from ppsci.data.dataset.stafnet_dataset import gat_lstmcollate_fn
+import multiprocessing
+
+def train(cfg: DictConfig):
+ # set model
+ model = ppsci.arch.STAFNet(**cfg.MODEL)
+ train_dataloader_cfg = {
+ "dataset": {
+ "name": "STAFNetDataset",
+ "file_path": cfg.DATASET.data_dir,
+ "input_keys": cfg.MODEL.input_keys,
+ "label_keys": cfg.MODEL.output_keys,
+ "seq_len": cfg.MODEL.seq_len,
+ "pred_len": cfg.MODEL.pred_len,
+
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "num_workers": 0
+ }
+ eval_dataloader_cfg= {
+ "dataset": {
+ "name": "STAFNetDataset",
+ "file_path": cfg.EVAL.eval_data_path,
+ "input_keys": cfg.MODEL.input_keys,
+ "label_keys": cfg.MODEL.output_keys,
+ "seq_len": cfg.MODEL.seq_len,
+ "pred_len": cfg.MODEL.pred_len,
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "num_workers": 0
+ }
+
+ sup_constraint = ppsci.constraint.SupervisedConstraint(
+ train_dataloader_cfg,
+ loss=ppsci.loss.MSELoss("mean"),
+ name="STAFNet_Sup",
+ )
+ constraint = {sup_constraint.name: sup_constraint}
+ sup_validator = ppsci.validate.SupervisedValidator(
+ eval_dataloader_cfg,
+ loss=ppsci.loss.MSELoss("mean"),
+ metric={"MSE": ppsci.metric.MSE()},
+ name="Sup_Validator",
+ )
+ validator = {sup_validator.name: sup_validator}
+
+ # set optimizer
+ lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
+ optimizer = ppsci.optimizer.Adam(lr_scheduler)(model)
+ ITERS_PER_EPOCH = len(sup_constraint.data_loader)
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ constraint,
+ cfg.output_dir,
+ optimizer,
+ lr_scheduler,
+ cfg.TRAIN.epochs,
+ ITERS_PER_EPOCH,
+ eval_during_train=cfg.TRAIN.eval_during_train,
+ seed=cfg.seed,
+ validator=validator,
+ compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,
+ eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
+ )
+
+ # train model
+ solver.train()
+
+def evaluate(cfg: DictConfig):
+ model = ppsci.arch.STAFNet(**cfg.MODEL)
+ eval_dataloader_cfg= {
+ "dataset": {
+ "name": "STAFNetDataset",
+ "file_path": cfg.EVAL.eval_data_path,
+ "input_keys": cfg.MODEL.input_keys,
+ "label_keys": cfg.MODEL.output_keys,
+ "seq_len": cfg.MODEL.seq_len,
+ "pred_len": cfg.MODEL.pred_len,
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "num_workers": 0
+ }
+ sup_validator = ppsci.validate.SupervisedValidator(
+ eval_dataloader_cfg,
+ loss=ppsci.loss.MSELoss("mean"),
+ metric={"MSE": ppsci.metric.MSE()},
+ name="Sup_Validator",
+ )
+ validator = {sup_validator.name: sup_validator}
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ validator=validator,
+ cfg=cfg,
+ pretrained_model_path=cfg.EVAL.pretrained_model_path,
+ compute_metric_by_batch=cfg.EVAL.compute_metric_by_batch,
+ eval_with_no_grad=cfg.EVAL.eval_with_no_grad,
+ )
+
+ # evaluate model
+ solver.eval()
+
+
+@hydra.main(version_base=None, config_path="./conf", config_name="stafnet.yaml")
+def main(cfg: DictConfig):
+ if cfg.mode == "train":
+ train(cfg)
+ elif cfg.mode == "eval":
+ evaluate(cfg)
+ else:
+ raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
+
+if __name__ == "__main__":
+ multiprocessing.set_start_method("spawn")
+ main()
\ No newline at end of file
From 862cbfbfaadee16ebc1736dc566b14ee2faa9405 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Thu, 5 Jun 2025 21:48:07 +0800
Subject: [PATCH 16/49] Add files via upload
---
ppsci/arch/stafnet.py | 35 -----------------------------------
1 file changed, 35 deletions(-)
diff --git a/ppsci/arch/stafnet.py b/ppsci/arch/stafnet.py
index a5b3e00371..7fbb16d306 100644
--- a/ppsci/arch/stafnet.py
+++ b/ppsci/arch/stafnet.py
@@ -581,9 +581,6 @@ def __init__(
self.output_attention = output_attention
def aq_gat(self, G):
- # x = G.x[:, -self.aq_gat_node_features:].to(self.device)
- # edge_index = G.edge_index.to(self.device)
- # edge_attr = G.edge_attr.to(self.device)
g_batch = G.num_graph
batch_size = int(g_batch/self.seq_len)
gat_output = self.aq_GAT(G, G.node_feat["feature"][:, -self.aq_gat_node_features:])
@@ -593,9 +590,6 @@ def aq_gat(self, G):
return gat_output
def mete_gat(self, G):
- # x = G.x[:, -self.mete_gat_node_features:].to(self.device)
- # edge_index = G.edge_index.to(self.device)
- # edge_attr = G.edge_attr.to(self.device)
g_batch = G.num_graph
batch_size = int(g_batch/self.seq_len)
gat_output = self.mete_GAT(G, G.node_feat["feature"][:, -self.mete_gat_node_features:])
@@ -605,7 +599,6 @@ def mete_gat(self, G):
return gat_output
def norm_pos(self, A, B):
- # paddle.mean(x)
A_mean = paddle.mean(A, axis=0)
A_std = paddle.std(A, axis=0)
@@ -614,29 +607,6 @@ def norm_pos(self, A, B):
return A_norm, B_norm
def forward(self, Data, mask=None):
- # aq_G = Data['aq_G']
- # mete_G = Data['mete_G']
- # aq_gat_output = self.aq_gat(aq_G)
- # mete_gat_output = self.mete_gat(mete_G)
- # aq_pos, mete_pos = self.norm_pos(aq_G.node_feat["pos"], mete_G.node_feat["pos"])
-
-
- # aq_pos = self.pos_fc(aq_pos).reshape((-1, self.aq_gat_node_num, self.
- # gat_embed_dim))
- # mete_pos = self.pos_fc(mete_pos).reshape((-1, self.mete_gat_node_num,
- # self.gat_embed_dim))
- # fusion_out, attn = self.fusion_Attention(aq_pos, mete_pos, mete_gat_output, attn_mask=None)
- # aq_gat_output = aq_gat_output + fusion_out
- # aq_gat_output = aq_gat_output.reshape((-1, self.seq_len, self.
- # aq_gat_node_num, self.gat_embed_dim))
- # x = aq_gat_output
- # perm_0 = list(range(x.ndim))
- # perm_0[1] = 2
- # perm_0[2] = 1
- # aq_gat_output = paddle.transpose(x=x, perm=perm_0)
- # aq_gat_output = paddle.flatten(x=aq_gat_output, start_axis=0,
- # stop_axis=1)
-
train_data = Data['aq_train_data']
batch_size = train_data.shape[0]
x = train_data
@@ -663,10 +633,5 @@ def forward(self, Data, mask=None):
dec_out = self.projection(enc_out)
dec_out = dec_out * paddle.tile( stdev[:, 0, :].unsqueeze(axis=1), (1, self.pred_len + self.seq_len, 1))
dec_out = dec_out + paddle.tile(means[:, 0, :].unsqueeze(axis=1), (1, self.pred_len + self.seq_len, 1))
- # dec_out = dec_out * stdev[:, 0, :].unsqueeze(axis=1).repeat(1, self
- # .pred_len + self.seq_len, 1)
- # dec_out = dec_out + means[:, 0, :].unsqueeze(axis=1).repeat(1, self
- # .pred_len + self.seq_len, 1)
-
return {self.output_keys[0]: dec_out[ :,-self.pred_len:, -7:].reshape((batch_size, self.pred_len,-1,7))}
From 726a02627753c19f9c29cc3cfe0e3e119ea31768 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Thu, 5 Jun 2025 21:49:28 +0800
Subject: [PATCH 17/49] Add files via upload
---
ppsci/data/dataset/stafnet_dataset.py | 44 +++++----------------------
1 file changed, 7 insertions(+), 37 deletions(-)
diff --git a/ppsci/data/dataset/stafnet_dataset.py b/ppsci/data/dataset/stafnet_dataset.py
index 94cf6e2e7a..1cb6e78adc 100644
--- a/ppsci/data/dataset/stafnet_dataset.py
+++ b/ppsci/data/dataset/stafnet_dataset.py
@@ -50,11 +50,7 @@ def __init__(self, args, data_dir, batch_size, shuffle=True,
self.T = T
self.t = t
self.dataset = STAFNetDataset(args=args, file_path=file_path)
- # if get_world_size() > 1:
- # sampler = paddle.io.DistributedBatchSampler(dataset=self.
- # dataset, shuffle=shuffle, batch_size=1)
- # else:
- # sampler = None
+
super().__init__(self.dataset, batch_size=batch_size, shuffle=shuffle, num_workers = num_workers,
collate_fn=collate_fn)
@@ -88,6 +84,8 @@ def __init__(self,
seq_len: int = 72,
pred_len: int = 48,
use_edge_attr: bool = True,):
+
+
self.file_path = file_path
self.input_keys = input_keys
self.label_keys = label_keys
@@ -111,7 +109,7 @@ def __init__(self,
(self.mete_edge_index, self.mete_edge_attr, self.mete_node_coords) = (self.get_edge_attr(np.array(self.meteStation_imformation.loc[:, ['经度', '纬度']]).astype('float64')))
self.lut = self.find_nearest_point(AQ_coords, mete_coords)
- # self.AQdata = np.concatenate((self.AQdata, self.metedata[:, self.lut, -7:]), axis=2)
+
def __len__(self):
@@ -121,44 +119,16 @@ def __getitem__(self, idx):
input_data = {}
aq_train_data = paddle.to_tensor(data=self.AQdata[idx:idx + self.seq_len + self.pred_len]).astype(dtype='float32')
mete_train_data = paddle.to_tensor(data=self.metedata[idx:idx + self.seq_len + self.pred_len]).astype(dtype='float32')
- aq_g_list = [pgl.Graph(num_nodes=s.shape[0],
- edges=self.aq_edge_index,
- node_feat={
- "feature": s,
- "pos": self.aq_node_coords.astype(dtype='float32')
- },
- edge_feat={
- "edge_feature": self.aq_edge_attr.astype(dtype='float32')
- })for s in aq_train_data[:self.seq_len]]
-
- mete_g_list = [pgl.Graph(num_nodes=s.shape[0],
- edges=self.mete_edge_index,
- node_feat={
- "feature": s,
- "pos": self.mete_node_coords.astype(dtype='float32')
- },
- edge_feat={
- "edge_feature": self.mete_edge_attr.astype(dtype='float32')
- })for s in mete_train_data[:self.seq_len]]
-
- # aq_g_list = [pgl.Graph(x=s, edge_index=self.aq_edge_index, edge_attr=self.aq_edge_attr.astype(dtype='float32'), pos=self.aq_node_coords.astype(dtype='float32')) for s in aq_train_data[:self.seq_len]]
- # mete_g_list = [pgl.Graph((x=s, edge_index=self.
- # mete_edge_index, edge_attr=self.mete_edge_attr.astype(dtype=
- # 'float32'), pos=self.mete_node_coords.astype(dtype='float32')) for
- # s in mete_train_data[:self.seq_len]]
-
label = aq_train_data[-self.pred_len:, :, -7:]
data = {'aq_train_data': aq_train_data, 'mete_train_data': mete_train_data,
- # 'aq_g_list': aq_g_list, 'mete_g_list': mete_g_list
}
- input_item = {'aq_train_data': aq_train_data, 'mete_train_data': mete_train_data,
- # 'aq_g_list': aq_g_list, 'mete_g_list': mete_g_list
+ input_item = {'aq_train_data': aq_train_data, 'mete_train_data': mete_train_data
}
label_item = {self.label_keys[0]: aq_train_data[-self.pred_len:, :, -7:]}
return input_item, label_item, {}
- # return data, label,
+
def get_edge_attr(self, node_coords, threshold=0.2):
# node_coords = paddle.to_tensor(data=node_coords)
@@ -178,4 +148,4 @@ def find_nearest_point(self, A, B):
for a in A:
distances = [np.linalg.norm(a - b) for b in B]
nearest_indices.append(np.argmin(distances))
- return nearest_indices
+ return nearest_indices
\ No newline at end of file
From 5ccc90886e3efa618778a0fe60ca3ba3e484eb11 Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Thu, 5 Jun 2025 22:16:01 +0800
Subject: [PATCH 18/49] Add files via upload
---
docs/zh/examples/stafnet.md | 169 ++++++++++++++++++++++++++++++++++++
1 file changed, 169 insertions(+)
create mode 100644 docs/zh/examples/stafnet.md
diff --git a/docs/zh/examples/stafnet.md b/docs/zh/examples/stafnet.md
new file mode 100644
index 0000000000..225e97642b
--- /dev/null
+++ b/docs/zh/examples/stafnet.md
@@ -0,0 +1,169 @@
+# STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction
+
+| 预训练模型 | 指标 |
+| ------------------------------------------------------------ | ---------------------- |
+| [stafnet.pdparams](https://paddle-org.bj.bcebos.com/paddlescience/models/stafnet/stafnet.pdparams) | AQI_MAE(1-48h) : 26.72 |
+
+=== "模型训练命令"
+
+````
+``` sh
+python stafnet.py TRAIN_DIR="Your train dataset path" eval_data_path="Your evaluate dataset path"
+```
+````
+
+=== "模型评估命令"
+
+````
+``` sh
+python stafnet.py mode=eval EVAL.pretrained_model_path="https://paddle-org.bj.bcebos.com/paddlescience/models/stafnet/stafnet.pdparams" EVAL.pretrained_model_path="https://paddle-org.bj.bcebos.com/paddlescience/datasets/stafnet/val_data.pkl"
+```
+````
+
+## 1. 背景介绍
+
+近些年,全球城市化和工业化不可避免地导致了严重的空气污染问题。心脏病、哮喘和肺癌等非传染性疾病的高发与暴露于空气污染直接相关。因此,空气质量预测已成为公共卫生、国民经济和城市管理的研究热点。目前已经建立了大量监测站来监测空气质量,并将其地理位置和历史观测数据合并为时空数据。然而,由于空气污染形成和扩散的高度复杂性,空气质量预测仍然面临着一些挑战。
+
+首先,空气中污染物的排放和扩散会导致邻近地区的空气质量迅速恶化,这一现象在托布勒地理第一定律中被描述为空间依赖关系,建立空间关系模型对于预测空气质量至关重要。然而,由于空气监测站的地理分布稀疏,要捕捉数据中内在的空间关联具有挑战性。其次,空气质量受到多源复杂因素的影响,尤其是气象条件。例如,长时间的小风或静风会抑制空气污染物的扩散,而自然降雨则在清除和冲刷空气污染物方面发挥作用。然而,空气质量站和气象站位于不同区域,导致多模态特征不对齐。融合不对齐的多模态特征并获取互补信息以准确预测空气质量是另一个挑战。最后但并非最不重要的一点是,空气质量的变化具有明显的多周期性特征。利用这一特点对提高空气质量预测的准确性非常重要,但也具有挑战性。
+
+针对空气质量预测提出了许多研究。早期的方法侧重于学习单个观测站观测数据的时间模式,而放弃了观测站之间的空间关系。最近,由于图神经网络(GNN)在处理非欧几里得图结构方面的有效性,越来越多的方法采用 GNN 来模拟空间依赖关系。这些方法将车站位置作为上下文特征,隐含地建立空间依赖关系模型,没有充分利用车站位置和车站之间关系所包含的宝贵空间信息。此外,现有的时空 GNN 缺乏在错位图中融合多个特征的能力。因此,大多数方法都需要额外的插值算法,以便在早期阶段将气象特征与 AQ 特征进行对齐和连接。这种方法消除了空气质量站和气象站之间的空间和结构信息,还可能引入噪声导致误差累积。此外,在空气质量预测中利用多周期性的问题仍未得到探索。
+
+该案例研究时空图网络网络在空气质量预测方向上的应用。
+
+## 2. 模型原理
+
+STAFNet是一个新颖的多模式预报框架--时空感知融合网络来预测空气质量。STAFNet 由三个主要部分组成:空间感知 GNN、跨图融合关注机制和 TimesNet 。具体来说,为了捕捉各站点之间的空间关系,我们首先引入了空间感知 GNN,将空间信息明确纳入信息传递和节点表示中。为了全面表示气象影响,我们随后提出了一种基于交叉图融合关注机制的多模态融合策略,在不同类型站点的数量和位置不一致的情况下,将气象数据整合到 AQ 数据中。受多周期分析的启发,我们采用 TimesNet 将时间序列数据分解为不同频率的周期信号,并分别提取时间特征。
+
+本章节仅对 STAFNet的模型原理进行简单地介绍,详细的理论推导请阅读 STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction
+
+模型的总体结构如图所示:
+
+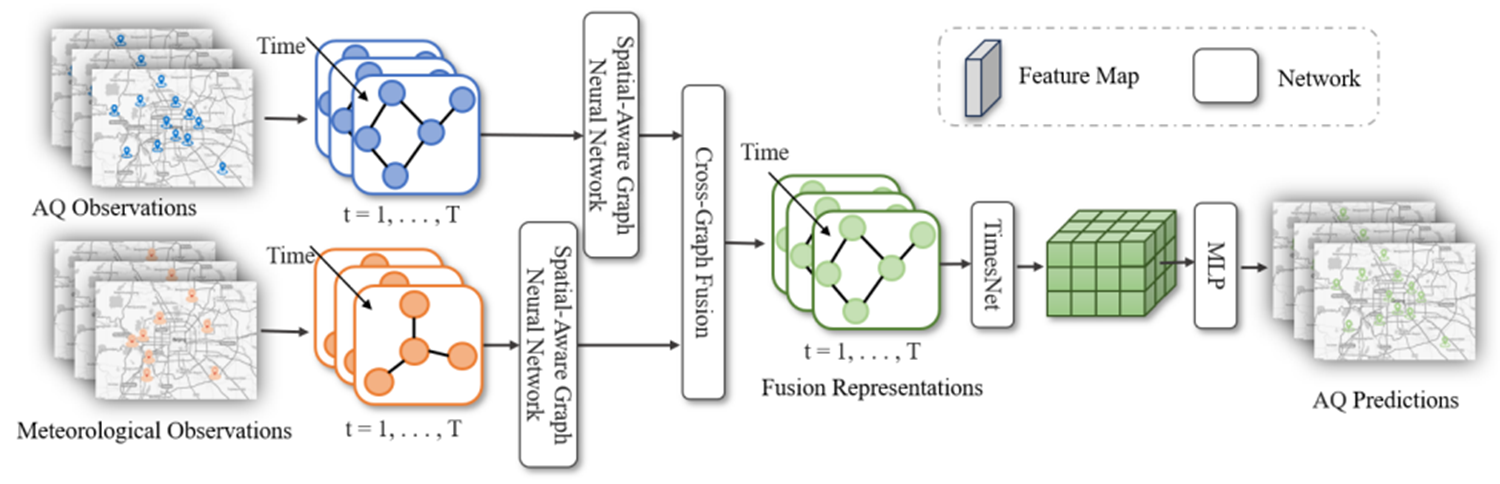
+
+STAFNet网络模型
+
+STAFNet 包含三个模块,分别将空间信息、气象信息和历史信息融合到空气质量特征表征中。首先模型的输入:过去T个时刻的**空气质量**数据和**气象**数据,使用两个空间感知 GNN(SAGNN),利用监测站之间的空间关系分别提取空气质量和气象信息。然后,跨图融合注意(CGF)将气象信息融合到空气质量表征中。最后,我们采用 TimesNet 模型来描述空气质量序列的时间动态,并生成多步骤预测。这一推理过程可表述如下,
+
+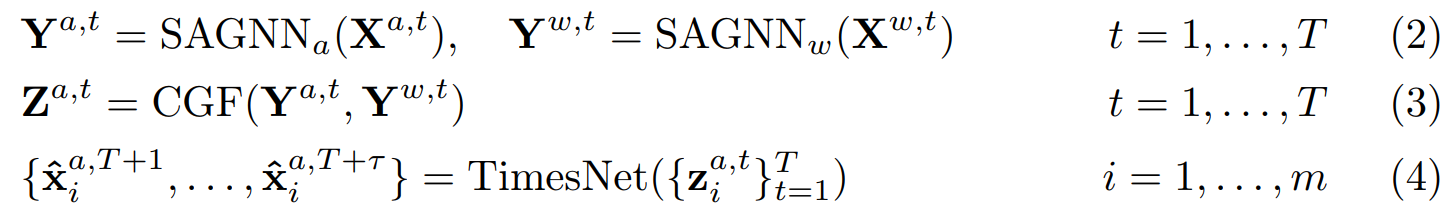
+
+## 3. 模型构建
+
+### 3.1 数据集介绍
+
+数据集采用了STAFNet处理好的北京空气质量数据集。数据集都包含:
+
+(1)空气质量观测值(即 PM2.5、PM10、O3、NO2、SO2 和 CO);
+
+(2)气象观测值(即温度、气压、湿度、风速和风向);
+
+(3)站点位置(即经度和纬度)。
+
+所有空气质量和气象观测数据每小时记录一次。数据集的收集时间为 2021 年 1 月 24 日至 2023 年 1 月 19 日,按 9:1的比例将数据分为训练集和测试集。空气质量观测数据来自国家城市空气质量实时发布平台,气象观测数据来自中国气象局。数据集的具体细节如下表所示:
+
+ 
北京空气质量数据集
+
+具体的数据集可从https://quotsoft.net/air/下载。
+
+运行本问题代码前请下载[数据集](https://paddle-org.bj.bcebos.com/paddlescience/datasets/stafnet/val_data.pkl), 下载后分别存放在路径:
+
+```
+./dataset
+```
+
+### 3.2 模型搭建
+
+在STAFNet模型中,输入过去72小时35个站点的空气质量数据,预测这35个站点未来48小时的空气质量。在本问题中,我们使用神经网络 `stafnet` 作为模型,其接收图结构数据,输出预测结果。
+
+```
+--8<--
+examples/stafnet/stafnet.py:11
+--8<--
+```
+
+### 3.4 参数和超参数设定
+
+其中超参数`cfg.MODEL.gat_hidden_dim`、`cfg.MODEL.e_layers`、`cfg.MODEL.d_model`、`cfg.MODEL.top_k`等默认设定如下:
+
+```
+--8<--
+examples/stafnet/conf/stafnet.yaml:38:62
+--8<--
+```
+
+### 3.5 优化器构建
+
+训练过程会调用优化器来更新模型参数,此处选择较为常用的 `Adam` 优化器。
+
+```
+--8<--
+examples/stafnet/stafnet.py:64
+--8<--
+```
+
+其中学习率相关的设定如下:
+
+```
+--8<--
+examples/stafnet/conf/stafnet.yaml:73:78
+--8<--
+```
+
+### 3.6 约束构建
+
+在本案例中,我们使用监督数据集对模型进行训练,因此需要构建监督约束。
+
+在定义约束之前,我们需要指定数据集的路径等相关配置,将这些信息存放到对应的 YAML 文件中,如下所示。
+
+```
+--8<--
+examples/stafnet/conf/stafnet.yaml:31:34
+--8<--
+```
+
+最后构建监督约束,如下所示。
+
+```
+--8<--
+examples/stafnet/stafnet.py:53:59
+--8<--
+```
+
+### 3.7 评估器构建
+
+在训练过程中通常会按一定轮数间隔,用验证集(测试集)评估当前模型的训练情况,因此使用 `ppsci.validate.SupervisedValidator` 构建评估器,构建过程与 [约束构建](https://github.com/PaddlePaddle/PaddleScience/blob/develop/docs/zh/examples/cfdgcn.md#34) 类似,只需把数据目录改为测试集的目录,并在配置文件中设置 `EVAL.batch_size=1` 即可。
+
+```
+--8<--
+examples/stafnet/stafnet.py:30:53
+--8<--
+```
+
+评估指标为预测结果和真实结果的MSE 值,因此需自定义指标计算函数,如下所示。
+
+```
+--8<--
+examples/stafnet/stafnet.py:30:53
+--8<--
+```
+
+### 3.8 模型训练
+
+由于本问题为时序预测问题,因此可以使用PaddleScience内置的`psci.loss.MAELoss('mean')`作为训练过程的损失函数。同时选择使用随机梯度下降法对网络进行优化。完成述设置之后,只需要将上述实例化的对象按顺序传递给 `ppsci.solver.Solver`,然后启动训练。具体代码如下:
+
+```
+--8<--
+examples/stafnet/stafnet.py:125:140
+--8<--
+```
+
+## 4. 完整代码
+
+```python
+--8<--
+examples/stafnet/stafnet.py
+--8<--
+```
+
+## 5. 参考资料
+
+- [STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction]([STAFNet: Spatiotemporal-Aware Fusion Network for Air Quality Prediction | SpringerLink](https://link.springer.com/chapter/10.1007/978-3-031-78186-5_22))
From 0319c7154edd2922d0fc47cb6bc19683d13a77eb Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 6 Jun 2025 17:42:12 +0800
Subject: [PATCH 19/49] Add files via upload
---
README.md | 114 ++++++++++++++---------------------------------------
mkdocs.yml | 25 +-----------
2 files changed, 31 insertions(+), 108 deletions(-)
diff --git a/README.md b/README.md
index 5834ca7da5..fca272bd02 100644
--- a/README.md
+++ b/README.md
@@ -1,31 +1,22 @@
# PaddleScience
-
> *Developed with [PaddlePaddle](https://www.paddlepaddle.org.cn/)*
[](https://pypi.org/project/paddlesci/)
-[](https://anaconda.org/PaddleScience/paddlescience)
[](https://pypi.org/project/paddlesci/)
[](https://paddlescience-docs.readthedocs.io/zh-cn/latest/)
[](https://github.com/psf/black)
[](https://hydra.cc/)
[](https://github.com/PaddlePaddle/PaddleScience/blob/develop/LICENSE)
-[](https://anaconda.org/PaddleScience/paddlescience)
-[📘 使用文档](https://paddlescience-docs.readthedocs.io/zh-cn/latest/) |
-[🛠️ 安装使用](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/install_setup/) |
-[📘 快速开始](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/quickstart/) |
-[👀 案例列表](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/allen_cahn/) |
-[🆕 最近更新](https://paddlescience-docs.readthedocs.io/zh-cn/latest/#_4) |
-[🤔 问题反馈](https://github.com/PaddlePaddle/PaddleScience/issues/new/choose)
+[**PaddleScience使用文档**](https://paddlescience-docs.readthedocs.io/zh-cn/latest/)
-
-🔥 [飞桨AI for Science共创计划2期](https://aistudio.baidu.com/activitydetail/1502019365),免费提供海量算力等资源,欢迎报名。
+🔥 [IJCAI 2024: 任意三维几何外形车辆的风阻快速预测竞赛](https://competition.atomgit.com/competitionInfo?id=7f3f276465e9e845fd3a811d2d6925b5),track A, B, C 代码:
-🔥 [飞桨AI for Science前沿讲座系列课程 & 代码入门与实操课程进行中](https://mp.weixin.qq.com/s/n-vGnGM9di_3IByTC56hUw),清华、北大、中科院等高校机构知名学者分享前沿研究成果,火热报名中。
-
+- [paddle实现](../jointContribution/IJCAI_2024/README.md)
+- [pytorch实现](https://competition.atomgit.com/competitionInfo?id=7f3f276465e9e845fd3a811d2d6925b5)(点击**排行榜**可查看各个赛道前10名的代码)
## 👀简介
@@ -53,16 +44,12 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 光孤子 | [Optical soliton](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nlsmb) | 机理驱动 | MLP | 无监督学习 | - | [Paper](https://doi.org/10.1007/s11071-023-08824-w)|
| 光纤怪波 | [Optical rogue wave](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nlsmb) | 机理驱动 | MLP | 无监督学习 | - | [Paper](https://doi.org/10.1007/s11071-023-08824-w)|
| 域分解 | [XPINN](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/xpinns) | 机理驱动 | MLP | 无监督学习 | - | [Paper](https://doi.org/10.4208/cicp.OA-2020-0164)|
-| 布鲁塞尔扩散系统 | [3D-Brusselator](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/brusselator3d) | 数据驱动 | LNO | 监督学习 | - | [Paper](https://arxiv.org/abs/2303.10528)|
-| 符号回归 | [Transformer4SR](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/transformer4sr.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2312.04070)|
-| 算子学习 | [隐空间神经算子LNO](https://github.com/L-I-M-I-T/LatentNeuralOperator) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2406.03923)|
技术科学(AI for Technology)
| 问题类型 | 案例名称 | 优化算法 | 模型类型 | 训练方式 | 数据集 | 参考资料 |
|-----|---------|-----|---------|----|---------|---------|
-| 汽车表面阻力预测 | [DrivAerNet](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/drivaernet/) | 数据驱动 | RegDGCNN | 监督学习 | [Data](https://dataset.bj.bcebos.com/PaddleScience/DNNFluid-Car/DrivAer%2B%2B/data.tar) | [Paper](https://www.researchgate.net/publication/378937154_DrivAerNet_A_Parametric_Car_Dataset_for_Data-Driven_Aerodynamic_Design_and_Graph-Based_Drag_Prediction) |
| 一维线性对流问题 | [1D 线性对流](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/adv_cvit/) | 数据驱动 | ViT | 监督学习 | [Data](https://github.com/Zhengyu-Huang/Operator-Learning/tree/main/data) | [Paper](https://arxiv.org/abs/2405.13998) |
| 非定常不可压流体 | [2D 方腔浮力驱动流](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ns_cvit/) | 数据驱动 | ViT | 监督学习 | [Data](https://huggingface.co/datasets/pdearena/NavierStokes-2D) | [Paper](https://arxiv.org/abs/2405.13998) |
| 定常不可压流体 | [Re3200 2D 定常方腔流](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ldc2d_steady) | 机理驱动 | MLP | 无监督学习 | - | |
@@ -81,10 +68,11 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 流固耦合 | [涡激振动](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/viv) | 机理驱动 | MLP | 半监督学习 | [Data](https://github.com/PaddlePaddle/PaddleScience/blob/develop/examples/fsi/VIV_Training_Neta100.mat) | [Paper](https://arxiv.org/abs/2206.03864)|
| 多相流 | [气液两相流](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/bubble) | 机理驱动 | BubbleNet | 半监督学习 | [Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/BubbleNet/bubble.mat) | [Paper](https://pubs.aip.org/aip/adv/article/12/3/035153/2819394/Predicting-micro-bubble-dynamics-with-semi-physics)|
| 多相流 | [twophasePINN](https://aistudio.baidu.com/projectdetail/5379212) | 机理驱动 | MLP | 无监督学习 | - | [Paper](https://doi.org/10.1016/j.mlwa.2021.100029)|
+| 多相流 | 非高斯渗透率场估计coming soon | 机理驱动 | cINN | 监督学习 | - | [Paper](https://pubs.aip.org/aip/adv/article/12/3/035153/2819394/Predicting-micro-bubble-dynamics-with-semi-physics)|
| 流场高分辨率重构 | [2D 湍流流场重构](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/tempoGAN) | 数据驱动 | tempoGAN | 监督学习 | [Train Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tempoGAN/2d_train.mat)
[Eval Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tempoGAN/2d_valid.mat) | [Paper](https://dl.acm.org/doi/10.1145/3197517.3201304)|
| 流场高分辨率重构 | [2D 湍流流场重构](https://aistudio.baidu.com/projectdetail/4493261?contributionType=1) | 数据驱动 | cycleGAN | 监督学习 | [Train Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tempoGAN/2d_train.mat)
[Eval Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tempoGAN/2d_valid.mat) | [Paper](https://arxiv.org/abs/2007.15324)|
| 流场高分辨率重构 | [基于Voronoi嵌入辅助深度学习的稀疏传感器全局场重建](https://aistudio.baidu.com/projectdetail/5807904) | 数据驱动 | CNN | 监督学习 | [Data1](https://drive.google.com/drive/folders/1K7upSyHAIVtsyNAqe6P8TY1nS5WpxJ2c)
[Data2](https://drive.google.com/drive/folders/1pVW4epkeHkT2WHZB7Dym5IURcfOP4cXu)
[Data3](https://drive.google.com/drive/folders/1xIY_jIu-hNcRY-TTf4oYX1Xg4_fx8ZvD) | [Paper](https://arxiv.org/pdf/2202.11214.pdf) |
-| 流场预测 | [Catheter](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/catheter/) | 数据驱动 | FNO | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/291940) | [Paper](https://www.science.org/doi/pdf/10.1126/sciadv.adj1741) |
+| 流场高分辨率重构 | 基于扩散的流体超分重构coming soon | 数理融合 | DDPM | 监督学习 | - | [Paper](https://www.sciencedirect.com/science/article/pii/S0021999123000670)|
| 求解器耦合 | [CFD-GCN](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/cfdgcn) | 数据驱动 | GCN | 监督学习 | [Data](https://aistudio.baidu.com/aistudio/datasetdetail/184778)
[Mesh](https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/meshes.tar) | [Paper](https://arxiv.org/abs/2007.04439)|
| 受力分析 | [1D 欧拉梁变形](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/euler_beam) | 机理驱动 | MLP | 无监督学习 | - | - |
| 受力分析 | [2D 平板变形](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/biharmonic2d) | 机理驱动 | MLP | 无监督学习 | - | [Paper](https://arxiv.org/abs/2108.07243) |
@@ -92,9 +80,7 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 受力分析 | [结构震动模拟](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/phylstm) | 机理驱动 | PhyLSTM | 监督学习 | [Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/PhyLSTM/data_boucwen.mat) | [Paper](https://arxiv.org/abs/2002.10253) |
| 受力分析 | [2D 弹塑性结构](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/epnn) | 机理驱动 | EPNN | 无监督学习 | [Train Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/epnn/dstate-16-plas.dat)
[Eval Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/epnn/dstress-16-plas.dat) | [Paper](https://arxiv.org/abs/2204.12088) |
| 受力分析和逆问题 | [3D 汽车控制臂变形](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/control_arm) | 机理驱动 | MLP | 无监督学习 | - | - |
-| 受力分析和逆问题 | [3D 心脏仿真](https://paddlescience-docs.readthedocs.io/zh/examples/heart.md) | 数理融合 | PINN | 监督学习 | - | - |
| 拓扑优化 | [2D 拓扑优化](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/topopt) | 数据驱动 | TopOptNN | 监督学习 | [Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/topopt/top_dataset.h5) | [Paper](https://arxiv.org/pdf/1709.09578) |
-| 拓扑优化 | [2/3D 拓扑优化](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ntopo.md) | 机理驱动 | DenseSIRENModel | 无监督学习 | - | [Paper](https://arxiv.org/abs/2102.10782) |
| 热仿真 | [1D 换热器热仿真](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/heat_exchanger) | 机理驱动 | PI-DeepONet | 无监督学习 | - | - |
| 热仿真 | [2D 热仿真](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/heat_pinn) | 机理驱动 | PINN | 无监督学习 | - | [Paper](https://arxiv.org/abs/1711.10561)|
| 热仿真 | [2D 芯片热仿真](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/chip_heat) | 机理驱动 | PI-DeepONet | 无监督学习 | - | [Paper](https://doi.org/10.1063/5.0194245)|
@@ -105,40 +91,27 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 问题类型 | 案例名称 | 优化算法 | 模型类型 | 训练方式 | 数据集 | 参考资料 |
|-----|---------|-----|---------|----|---------|---------|
| 材料设计 | [散射板设计(反问题)](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/hpinns) | 数理融合 | 数据驱动 | 监督学习 | [Train Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/hPINNs/hpinns_holo_train.mat)
[Eval Data](https://paddle-org.bj.bcebos.com/paddlescience/datasets/hPINNs/hpinns_holo_valid.mat) | [Paper](https://arxiv.org/pdf/2102.04626.pdf) |
-| 晶体材料属性预测 | [CGCNN](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/cgcnn/) | 数据驱动 | GNN | 监督学习 | [MP](https://next-gen.materialsproject.org/) / [Perovskite](https://cmr.fysik.dtu.dk/cubic_perovskites/cubic_perovskites.html) / [C2DB](https://cmr.fysik.dtu.dk/c2db/c2db.html) / [test](https://paddle-org.bj.bcebos.com/paddlescience%2Fdatasets%2Fcgcnn%2Fcgcnn-test.zip) | [Paper](https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.120.145301) |
-| 分子生成 | [MoFlow](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/moflow/) | 数据驱动 | Flow Model | 监督学习 | [qm9/ zink250k](https://aistudio.baidu.com/datasetdetail/282687) | [Paper](https://arxiv.org/abs/2006.10137v1) |
-| 分子属性预测 | [IFM](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ifm/) | 数据驱动 | MLP | 监督学习 | [tox21/sider/hiv/bace/bbbp](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ifm/#:~:text=molecules%20%E6%95%B0%E6%8D%AE%E9%9B%86-,dataset.zip,-%EF%BC%8C%E6%88%96Google%20Drive) | [Paper](https://openreview.net/pdf?id=NLFqlDeuzt) |
-
+| 材料生成 | 面向对称感知的周期性材料生成coming soon | 数据驱动 | SyMat | 监督学习 | - | - |
地球科学(AI for Earth Science)
| 问题类型 | 案例名称 | 优化算法 | 模型类型 | 训练方式 | 数据集 | 参考资料 |
|-----|---------|-----|---------|----|---------|---------|
-| 天气预报 | [Extformer-MoE 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/extformer_moe.md) | 数据驱动 | Transformer | 监督学习 | [enso](https://tianchi.aliyun.com/dataset/98942) | - |
-| 天气预报 | [FourCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fourcastnet) | 数据驱动 | AFNO | 监督学习 | [ERA5](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://arxiv.org/pdf/2202.11214.pdf) |
-| 天气预报 | [NowCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
-| 天气预报 | [GraphCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/graphcast) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
-| 天气预报 | [GenCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/gencast) | 数据驱动 | Diffusion+Graph transformer | 监督学习 | [Gencast](https://console.cloud.google.com/storage/browser/dm_graphcast) | [Paper](https://arxiv.org/abs/2312.15796) |
-| 天气预报 | [Fuxi 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fuxi) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2306.12873) |
-| 天气预报 | [FengWu 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fengwu) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2304.02948) |
-| 天气预报 | [Pangu-Weather 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/pangu_weather) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
+| 天气预报 | [Extformer-MoE 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/extformer_moe.md) | 数据驱动 | FourCastNet | 监督学习 | [enso](https://tianchi.aliyun.com/dataset/98942) | - |
+| 天气预报 | [FourCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fourcastnet) | 数据驱动 | FourCastNet | 监督学习 | [ERA5](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://arxiv.org/pdf/2202.11214.pdf) |
+| 天气预报 | [NowCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet) | 数据驱动 | NowCastNet | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
+| 天气预报 | [GraphCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/graphcast) | 数据驱动 | GraphCastNet | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
-| 天气预报 | [DGMR 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/dgmr.md) | 数据驱动 | GAN | 监督学习 | [UK dataset](https://huggingface.co/datasets/openclimatefix/nimrod-uk-1km) | [Paper](https://arxiv.org/pdf/2104.00954.pdf) |
-| 地震波形反演 | [VelocityGAN 地震波形反演](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/velocity_gan.md) | 数据驱动 | VelocityGAN | 监督学习 | [OpenFWI](https://openfwi-lanl.github.io/docs/data.html#vel) | [Paper](https://arxiv.org/abs/1809.10262v6) |
-| 交通预测 | [TGCN 交通流量预测](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/tgcn.md) | 数据驱动 | GCN & CNN | 监督学习 | [PEMSD4 & PEMSD8](https://paddle-org.bj.bcebos.com/paddlescience/datasets/tgcn/tgcn_data.zip) | - |
-| 生成模型| [图像生成中的梯度惩罚应用](./zh/examples/wgan_gp.md)|数据驱动|WGAN GP|监督学习|[Data1](https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz)
[Data2](http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz)| [Paper](https://github.com/igul222/improved_wgan_training) |
+| 大气污染物 | [STAFNet 污染物浓度预测](./zh/examples/stafnet.md) | 数据驱动 | STAFNet | 监督学习 | [Data](https://quotsoft.net/air) | [Paper](https://link.springer.com/chapter/10.1007/978-3-031-78186-5_22) |
+| 天气预报 | [DGMR 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/dgmr.md) | 数据驱动 | DGMR | 监督学习 | [UK dataset](https://huggingface.co/datasets/openclimatefix/nimrod-uk-1km) | [Paper](https://arxiv.org/pdf/2104.00954.pdf) |
## 🕘最近更新
-- [沐曦MetaX](https://www.metax-tech.com/) 和 [太初元碁Tecorigin](http://www.tecorigin.com/cn/index.html) 完成与 PaddleScience 的第一阶段适配工作,详见:[多硬件支持](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/multi_device/)。
-- 基于 PaddleScience 的 ADR 方程求解方法 [Physics-informed neural networks for advection–diffusion–Langmuir adsorption processes](https://doi.org/10.1063/5.0221924) 被 Physics of Fluids 2024 接受。
-- 添加 [IJCAI 2024: 任意三维几何外形车辆的风阻快速预测竞赛](https://competition.atomgit.com/competitionInfo?id=7f3f276465e9e845fd3a811d2d6925b5),track A, B, C 的 paddle/pytorch 代码链接。
-- 添加 SPINN(基于 Helmholtz3D 方程求解) [helmholtz3d](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/spinn/)。
- 添加 CVit(基于 Advection 方程和 N-S 方程求解) [CVit(Navier-Stokes)](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ns_cvit/)、[CVit(Advection)](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/adv_cvit/)。
- 添加 PirateNet(基于 Allen-cahn 方程和 N-S 方程求解) [Allen-Cahn](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/allen_cahn/)、[LDC2D(Re3200)](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/ldc2d_steady/)。
-- 基于 PaddleScience 的快速热仿真方法 [A fast general thermal simulation model based on MultiBranch Physics-Informed deep operator neural network](https://doi.org/10.1063/5.0194245) 被 Physics of Fluids 2024 接受。
+- 基于 PaddleScience 的快速热仿真方法 [A fast general thermal simulation model based on MultiBranch Physics-Informed deep operator neural network](https://pubs.aip.org/aip/pof/article-abstract/36/3/037142/3277890/A-fast-general-thermal-simulation-model-based-on?redirectedFrom=fulltext) 被 Physics of Fluids 2024 接受。
- 添加多目标优化算法 [Relobralo](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/api/loss/mtl/#ppsci.loss.mtl.Relobralo) 。
- 添加气泡流求解案例([Bubble](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/bubble))、机翼优化案例([DeepCFD](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/deepcfd/))、热传导仿真案例([HeatPINN](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/heat_pinn))、非线性短临预报模型([Nowcasting(仅推理)](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet))、拓扑优化案例([TopOpt](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/topopt))、矩形平板线弹性方程求解案例([Biharmonic2D](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/biharmonic2d))。
- 添加二维血管案例([LabelFree-DNN-Surrogate](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/labelfree_DNN_surrogate/#4))、空气激波案例([ShockWave](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/shock_wave/))、去噪网络模型([DUCNN](https://github.com/PaddlePaddle/PaddleScience/tree/develop/jointContribution/DU_CNN))、风电预测模型([Deep Spatial Temporal](https://github.com/PaddlePaddle/PaddleScience/tree/develop/jointContribution/Deep-Spatio-Temporal))、域分解模型([XPINNs](https://github.com/PaddlePaddle/PaddleScience/tree/develop/jointContribution/XPINNs))、积分方程求解案例([Volterra Equation](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/volterra_ide))、分数阶方程求解案例([Fractional Poisson 2D](https://github.com/PaddlePaddle/PaddleScience/blob/develop/examples/fpde/fractional_poisson_2d.py))。
@@ -164,7 +137,7 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
### 安装 PaddlePaddle
-请根据您的运行环境,访问 [PaddlePaddle](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html) 官网,安装 3.0 或 develop 版的 PaddlePaddle。
+请在 [PaddlePaddle](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html) 官网按照您的运行环境,安装 3.0-beta 或 develop 版的 PaddlePaddle。
安装完毕之后,运行以下命令,验证 Paddle 是否安装成功。
@@ -179,7 +152,7 @@ python -c "import paddle; paddle.utils.run_check()"
1. 基础功能安装
- **从以下四种安装方式中,任选一种均可安装。**
+ **从以下三种安装方式中,任选一种均可安装。**
- git 源码安装[**推荐**]
@@ -193,7 +166,7 @@ python -c "import paddle; paddle.utils.run_check()"
cd PaddleScience
# install paddlesci with editable mode
- python -m pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
+ pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
```
@@ -203,33 +176,21 @@ python -c "import paddle; paddle.utils.run_check()"
``` shell
# release
- python -m pip install -U paddlesci -i https://pypi.tuna.tsinghua.edu.cn/simple
+ pip install -U paddlesci
# nightly build
- # python -m pip install https://paddle-qa.bj.bcebos.com/PaddleScience/whl/latest/dist/paddlesci-0.0.0-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
+ # pip install https://paddle-qa.bj.bcebos.com/PaddleScience/whl/latest/dist/paddlesci-0.0.0-py3-none-any.whl
```
- - conda 安装
-
- 执行以下命令以 conda 的方式安装 release / nightly build 版本的 PaddleScience。
-
- ``` shell
- # nightly build
- conda install paddlescience::paddlesci -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle -c conda-forge
- # release
- # conda install paddlescience::paddlescience=1.3.0 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle -c conda-forge
- ```
-
-
- 设置 PYTHONPATH 并手动安装 requirements
- 如果在您的环境中,上述两种方式都无法正常安装,则可以选择本方式,在终端内临时将环境变量 `PYTHONPATH` 设置为 PaddleScience 的**绝对路径**,如下所示。
+ 如果在您的环境中,上述两种方式都无法正常安装,则可以选择本方式,在终端内将环境变量 `PYTHONPATH` 临时设置为 `PaddleScience` 的**绝对路径**,如下所示。
``` shell
cd PaddleScience
export PYTHONPATH=$PYTHONPATH:$PWD # for linux
set PYTHONPATH=%cd% # for windows
- python -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # manually install requirements
+ pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # manually install requirements
```
注:上述方式的优点是步骤简单无需安装,缺点是当环境变量生效的终端被关闭后,需要重新执行上述命令设置 `PYTHONPATH` 才能再次使用 PaddleScience,较为繁琐。
@@ -254,30 +215,16 @@ python -c "import paddle; paddle.utils.run_check()"
请参考 [**快速开始**](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/quickstart/)
-## 🎈生态工具
+## 🎈其他领域支持
-除 PaddleScience 外,Paddle 框架同时支持了科学计算领域相关的研发套件和基础工具:
-
-| 工具 | 简介 | 支持情况 |
-| -- | -- | -- |
-| [DeepXDE](https://github.com/lululxvi/deepxde/tree/master?tab=readme-ov-file#deepxde) | 方程求解套件 | 全量支持 |
-| [DeepMD-kit](https://docs.deepmodeling.com/projects/deepmd/en/latest/index.html) | 分子动力学套件 | 部分支持 |
-| [Modulus-sym](https://github.com/PaddlePaddle/modulus-sym/tree/paddle?tab=readme-ov-file#modulus-symbolic-betapaddle-backend) | AI仿真套件 | 全量支持 |
-| [NVIDIA/warp](https://github.com/NVIDIA/warp) | 基于 Python 的 GPU 高性能仿真和图形库 | 全量支持 |
-| [tensorly](https://github.com/tensorly/tensorly) | 张量运算库 | 全量支持 |
-| [Open3D](https://github.com/PFCCLab/Open3D.git) | 三维图形库 | 全量支持 |
-| [neuraloperator](https://github.com/PFCCLab/neuraloperator) | 神经算子库 | 全量支持 |
-| [paddle_scatter](https://github.com/PFCCLab/paddle_scatter) | 张量稀疏计算库 | 全量支持 |
-| [paddle_harmonics](https://github.com/PFCCLab/paddle_harmonics.git) | 球面谐波变换库 | 全量支持 |
-| [deepali](https://github.com/PFCCLab/deepali) | 图像、点云配准库 | 全量支持 |
-| [DLPACK(v0.8)](https://dmlc.github.io/dlpack/latest/index.html) | 跨框架张量内存共享协议 | 全量支持 |
+除 PaddleScience 套件外,Paddle 框架还支持了 [Modulus-sym](https://github.com/PaddlePaddle/modulus-sym/tree/paddle?tab=readme-ov-file#modulus-symbolic-betapaddle-backend)、[DeepXDE](https://github.com/lululxvi/deepxde/tree/master?tab=readme-ov-file#deepxde) 的所有案例,分子动力学套件 [DeepMD-kit](https://github.com/deepmodeling/deepmd-kit/tree/paddle2?tab=readme-ov-file#deepmd-kitpaddlepaddle-backend) 部分案例和功能。
## 💬支持与建议
-如在使用过程中遇到问题或想提出开发建议,欢迎在 [**Discussion**](https://github.com/PaddlePaddle/PaddleScience/discussions/new?category=general) 中提出,或者在 [**Issue**](https://github.com/PaddlePaddle/PaddleScience/issues/new/choose) 页面新建 issue,会有专业的研发人员进行解答。
+如使用过程中遇到问题或想提出开发建议,欢迎在 [**Discussion**](https://github.com/PaddlePaddle/PaddleScience/discussions/new?category=general) 提出建议,或者在 [**Issue**](https://github.com/PaddlePaddle/PaddleScience/issues/new/choose) 页面新建 issue,会有专业的研发人员进行解答。
@@ -287,20 +234,20 @@ PaddleScience 项目欢迎并依赖开发人员和开源社区中的用户,会
> 在开源活动中如需使用 PaddleScience 进行开发,可参考 [**PaddleScience 开发与贡献指南**](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/development/) 以提升开发效率和质量。
-- 🔥第七期黑客松
-
- 面向全球开发者的深度学习领域编程活动,鼓励开发者了解与参与飞桨深度学习开源项目。活动进行中:[PaddlePaddle Hackathon 7th 开源贡献个人挑战赛](https://github.com/PaddlePaddle/Paddle/issues/67603)
-
- 🎁快乐开源
旨在鼓励更多的开发者参与到飞桨科学计算社区的开源建设中,帮助社区修复 bug 或贡献 feature,加入开源、共建飞桨。了解编程基本知识的入门用户即可参与,活动进行中:
[PaddleScience 快乐开源活动表单](https://github.com/PaddlePaddle/PaddleScience/issues/379)
+
+
## 🎯共创计划
-PaddleScience 作为一个开源项目,欢迎来各行各业的伙伴携手共建基于飞桨的 AI for Science 领域顶尖开源项目, 打造活跃的前瞻性的 AI for Science 开源社区,建立产学研闭环,推动科研创新与产业赋能。点击了解 [飞桨AI for Science共创计划](https://aistudio.baidu.com/activitydetail/1502019365)。
+PaddleScience 作为一个开源项目,欢迎来各行各业的伙伴携手共建基于飞桨的 AI for Science 领域顶尖开源项目, 打造活跃的前瞻性的 AI for Science 开源社区,建立产学研闭环,推动科研创新与产业赋能。点击了解 [飞桨AI for Science共创计划](https://www.paddlepaddle.org.cn/science)。
@@ -308,7 +255,7 @@ PaddleScience 作为一个开源项目,欢迎来各行各业的伙伴携手共
- PaddleScience 的部分模块和案例设计受 [NVIDIA-Modulus](https://github.com/NVIDIA/modulus/tree/main)、[DeepXDE](https://github.com/lululxvi/deepxde/tree/master)、[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP/tree/develop)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas/tree/develop) 等优秀开源套件的启发。
-- PaddleScience 的部分案例和代码由以下优秀社区开发者贡献,(完整的贡献者请参考: [Contributors](https://github.com/PaddlePaddle/PaddleScience/graphs/contributors)):
+- PaddleScience 的部分案例和代码由以下优秀社区开发者贡献(按 [Contributors](https://github.com/PaddlePaddle/PaddleScience/graphs/contributors) 排序):
[Asthestarsfalll](https://github.com/Asthestarsfalll),
[co63oc](https://github.com/co63oc),
[MayYouBeProsperous](https://github.com/MayYouBeProsperous),
@@ -335,7 +282,6 @@ PaddleScience 作为一个开源项目,欢迎来各行各业的伙伴携手共
[ccsuzzh](https://github.com/ccsuzzh),
[enkilee](https://github.com/enkilee),
[GreatV](https://github.com/GreatV)
- ...
## 🤝合作单位
diff --git a/mkdocs.yml b/mkdocs.yml
index 2e70c8092b..0b48de419a 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -34,7 +34,6 @@ nav:
- 功能介绍: zh/overview.md
- 安装使用: zh/install_setup.md
- 快速开始: zh/quickstart.md
- - 多硬件支持: zh/multi_device.md
- 学习资料: zh/tutorials.md
- 经典案例:
- " ":
@@ -52,11 +51,8 @@ nav:
- SPINN: zh/examples/spinn.md
- XPINN: zh/examples/xpinns.md
- NeuralOperator: zh/examples/neuraloperator.md
- - Brusselator3D: zh/examples/brusselator3d.md
- - Transformer4SR: zh/examples/transformer4sr.md
- 技术科学(AI for Technology):
- 流体:
- - Catheter: zh/examples/catheter.md
- AMGNet: zh/examples/amgnet.md
- Aneurysm: zh/examples/aneurysm.md
- BubbleNet: zh/examples/bubble.md
@@ -67,8 +63,6 @@ nav:
- Cylinder2D_unsteady_transform_physx: zh/examples/cylinder2d_unsteady_transformer_physx.md
- Darcy2D: zh/examples/darcy2d.md
- DeepCFD: zh/examples/deepcfd.md
- - DrivAerNet: zh/examples/drivaernet.md
- - DrivAerNetPlusPlus: zh/examples/drivaernetplusplus.md
- LDC2D_steady: zh/examples/ldc2d_steady.md
- LDC2D_unsteady: zh/examples/ldc2d_unsteady.md
- Labelfree_DNN_surrogate: zh/examples/labelfree_DNN_surrogate.md
@@ -85,8 +79,6 @@ nav:
- EPNN: zh/examples/epnn.md
- Phy-LSTM: zh/examples/phylstm.md
- TopOpt: zh/examples/topopt.md
- - NTopo: zh/examples/ntopo.md
- - Heart: zh/examples/heart.md
- 传热:
- Heat_Exchanger: zh/examples/heat_exchanger.md
- Heat_PINN: zh/examples/heat_pinn.md
@@ -94,26 +86,14 @@ nav:
- Chip_heat: zh/examples/chip_heat.md
- 材料科学(AI for Material):
- hPINNs: zh/examples/hpinns.md
- - CGCNN: zh/examples/cgcnn.md
- 地球科学(AI for Earth Science):
- Extformer-MoE: zh/examples/extformer_moe.md
- FourCastNet: zh/examples/fourcastnet.md
- NowcastNet: zh/examples/nowcastnet.md
- DGMR: zh/examples/dgmr.md
+ - STAFNet: zh/examples/stafnet.md
- EarthFormer: zh/examples/earthformer.md
- GraphCast: zh/examples/graphcast.md
- - GenCast: zh/examples/gencast.md
- - VelocityGAN: zh/examples/velocity_gan.md
- - TGCN: zh/examples/tgcn.md
- - IOPS: zh/examples/iops.md
- - Pang-Weather: zh/examples/pangu_weather.md
- - FengWu: zh/examples/fengwu.md
- - FuXi: zh/examples/fuxi.md
- - WGAN_GP: zh/examples/wgan_gp.md
- - 化学科学(AI for Chemistry):
- - Moflow: zh/examples/moflow.md
- - IFM: zh/examples/ifm.md
-
- API 文档:
- ppsci:
- ppsci.arch: zh/api/arch.md
@@ -154,7 +134,6 @@ nav:
- 开发与复现指南:
- 开发指南: zh/development.md
- 复现指南: zh/reproduction.md
- - 学术成果: zh/academic.md
- 技术稿件: zh/technical_doc.md
- 共创计划: zh/cooperation.md
- 实训社区: https://aistudio.baidu.com/aistudio/projectoverview/public?topic=15
@@ -184,7 +163,6 @@ theme:
- content.tabs.link
- content.action.edit
- content.action.view
- - content.tooltips
icon:
edit: material/pencil
view: material/eye
@@ -225,7 +203,6 @@ plugins:
# Extensions
markdown_extensions:
- - abbr
- pymdownx.critic
- pymdownx.highlight:
anchor_linenums: true
From ff226a752050a9f4a698e74bb807669441365a2e Mon Sep 17 00:00:00 2001
From: dylan-yin <52811073+dylan-yin@users.noreply.github.com>
Date: Fri, 6 Jun 2025 17:43:01 +0800
Subject: [PATCH 20/49] Add files via upload
---
docs/index.md | 71 +++++++++++++++++++++++++++------------------------
1 file changed, 37 insertions(+), 34 deletions(-)
diff --git a/docs/index.md b/docs/index.md
index 95ec7b42c5..cd5c52a1a1 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -4,9 +4,10 @@
./README.md:status
--8<--
---8<--
-./README.md:announcement
---8<--
+🔥 [IJCAI 2024: 任意三维几何外形车辆的风阻快速预测竞赛](https://competition.atomgit.com/competitionInfo?id=7f3f276465e9e845fd3a811d2d6925b5),track A, B, C 代码:
+
+- [paddle实现](../jointContribution/IJCAI_2024/README.md)
+- [pytorch实现](https://competition.atomgit.com/competitionInfo?id=7f3f276465e9e845fd3a811d2d6925b5)(点击**排行榜**可查看各个赛道前10名的代码)